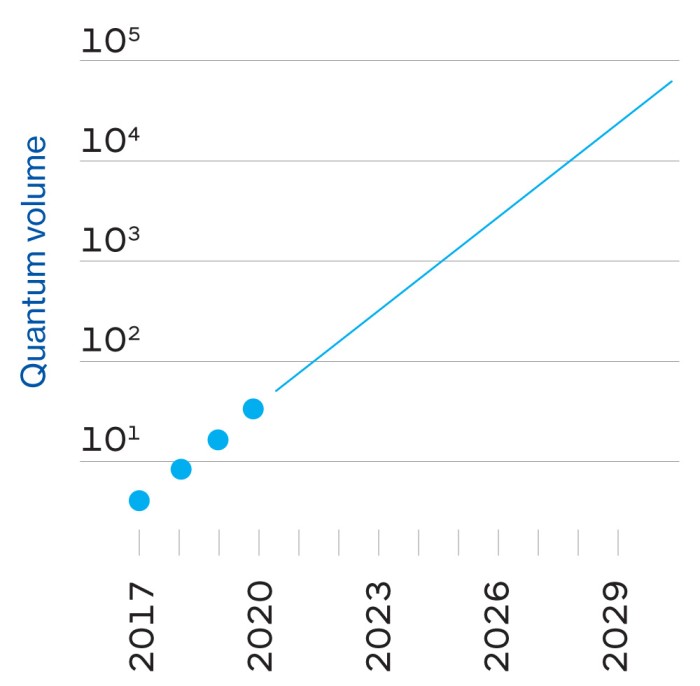
Ende Oktober letzten Jahres gab Google bekannt, dass einer dieser Chips, Sycamore, als erster die „Quantenüberlegenheit“ demonstriert hat, indem er eine Aufgabe ausführte, die auf einem klassischen Computer praktisch unmöglich wäre. Mit nur 53 Qubits hat Sycamore in wenigen Minuten eine Berechnung durchgeführt, für die der leistungsstärkste bestehende Supercomputer der Welt, Summit, laut Google 10.000 Jahre gebraucht hätte. Google bezeichnete dies als großen Durchbruch und verglich es mit dem Start des Sputniks oder dem ersten Flug der Gebrüder Wright – die Schwelle zu einer neuen Ära von Maschinen, die den mächtigsten Computer von heute wie einen Abakus aussehen lassen würden.
Bei einer Pressekonferenz im Labor in Santa Barbara stellte sich das Google-Team fast drei Stunden lang fröhlich den Fragen der Journalisten. Doch ihre gute Laune konnte eine unterschwellige Spannung nicht ganz verbergen. Zwei Tage zuvor hatten Forscher von IBM, Googles führendem Konkurrenten im Bereich der Quanteninformatik, die große Enthüllung torpediert. Sie hatten ein Papier veröffentlicht, in dem sie die Googler im Wesentlichen beschuldigten, sich bei ihren Berechnungen geirrt zu haben. IBM rechnete vor, dass Summit nur Tage und nicht Jahrtausende gebraucht hätte, um zu replizieren, was Sycamore getan hatte. Auf die Frage, was er von IBMs Ergebnis halte, vermied Hartmut Neven, der Leiter des Google-Teams, eine direkte Antwort.

Man könnte dies als einen akademischen Streit abtun – und in gewisser Weise war es das auch. Selbst wenn IBM Recht hatte, hatte Sycamore die Berechnung immer noch tausendmal schneller durchgeführt als Summit es getan hätte. Und es würde wahrscheinlich nur Monate dauern, bis Google eine etwas größere Quantenmaschine bauen würde, die diesen Punkt zweifelsfrei beweisen würde.
Der tiefere Einwand von IBM war jedoch nicht, dass Googles Experiment weniger erfolgreich war als behauptet, sondern dass es überhaupt ein sinnloser Test war. Anders als der Großteil der Quantencomputerwelt glaubt IBM nicht, dass die „Quantenvorherrschaft“ der Wright-Brüder-Moment der Technologie ist; tatsächlich glaubt es nicht einmal, dass es einen solchen Moment geben wird.
IBM verfolgt stattdessen ein ganz anderes Maß an Erfolg, etwas, das es „Quantenvorteil“ nennt. Dabei handelt es sich nicht um einen bloßen Unterschied in der Wortwahl oder gar in der Wissenschaft, sondern um eine philosophische Haltung, die ihre Wurzeln in der Geschichte, der Kultur und den Ambitionen von IBM hat – und vielleicht auch in der Tatsache, dass die Umsätze und Gewinne des Unternehmens seit acht Jahren fast ununterbrochen rückläufig sind, während die Zahlen von Google und seiner Muttergesellschaft Alphabet immer noch steigen. Dieser Kontext und diese unterschiedlichen Ziele könnten einen Einfluss darauf haben, wer – wenn überhaupt – im Rennen um das Quantencomputing die Nase vorn hat.
Welten trennen sich
Das elegante, geschwungene IBM Thomas J. Watson Research Center in den Vororten nördlich von New York City, ein neo-futuristisches Meisterwerk des finnischen Architekten Eero Saarinen, ist einen Kontinent und ein Universum entfernt von den unscheinbaren Bauten des Google-Teams. Es wurde 1961 mit dem Geld, das IBM mit Großrechnern verdiente, fertiggestellt und erinnert jeden, der darin arbeitet, an die Durchbrüche des Unternehmens in allen Bereichen, von fraktaler Geometrie über Supraleiter bis hin zu künstlicher Intelligenz und Quantencomputern.
Der Leiter der 4.000 Mitarbeiter zählenden Forschungsabteilung ist Dario Gil, ein Spanier, dessen rasante Rede mit seinem fast schon evangelischen Eifer Schritt halten kann. Beide Male, als ich mit ihm sprach, rasselte er historische Meilensteine herunter, um zu unterstreichen, wie lange IBM schon in der Quantencomputerforschung tätig ist (siehe Zeitleiste rechts).


Ein großes Experiment: Quantentheorie und Praxis
Der Grundbaustein eines Quantencomputers ist das Quantenbit. In einem klassischen Computer kann ein Bit entweder eine 0 oder eine 1 speichern. Ein Qubit kann nicht nur 0 oder 1 speichern, sondern auch einen Zwischenzustand, die so genannte Superposition, die viele verschiedene Werte annehmen kann. Eine Analogie ist, dass ein klassisches Bit entweder schwarz oder weiß sein kann, wenn Information eine Farbe wäre. Ein Qubit, das sich in Überlagerung befindet, kann jede beliebige Farbe des Spektrums annehmen und auch in der Helligkeit variieren.
Das Ergebnis ist, dass ein Qubit im Vergleich zu einem Bit eine enorme Menge an Informationen speichern und verarbeiten kann – und die Kapazität steigt exponentiell, wenn man Qubits miteinander verbindet. Um alle Informationen in den 53 Qubits auf dem Sycamore-Chip von Google zu speichern, bräuchte man etwa 72 Petabyte (72 Milliarden Gigabyte) an klassischem Computerspeicher. Es braucht nicht viel mehr Qubits, bis man einen klassischen Computer von der Größe der Erde braucht.
Aber das ist nicht so einfach. Da Qubits empfindlich sind und leicht gestört werden können, müssen sie nahezu perfekt von Hitze, Vibrationen und verirrten Atomen isoliert werden – daher auch die „Kronleuchter“-Kühlschränke in Googles Quantenlabor. Selbst dann können sie höchstens ein paar hundert Mikrosekunden lang funktionieren, bevor sie „dekohärent“ werden und ihre Überlagerung verlieren.
Und Quantencomputer sind nicht immer schneller als klassische Computer. Sie sind einfach anders, in manchen Dingen schneller und in anderen langsamer, und sie erfordern eine andere Art von Software. Um ihre Leistung zu vergleichen, muss man ein klassisches Programm schreiben, das das Quantenprogramm annähernd simuliert.
Für sein Experiment wählte Google einen Benchmarking-Test namens „Random Quantum Circuit Sampling“. Er generiert Millionen von Zufallszahlen, allerdings mit leichten statistischen Verzerrungen, die ein Markenzeichen des Quantenalgorithmus sind. Wäre Sycamore ein Taschenrechner, wäre es so, als würde man nach dem Zufallsprinzip Knöpfe drücken und prüfen, ob das Display die erwarteten Ergebnisse anzeigt.
Google simulierte Teile davon auf seinen eigenen riesigen Serverfarmen sowie auf Summit, dem größten Supercomputer der Welt, im Oak Ridge National Laboratory. Die Forscher schätzten, dass Summit für die gesamte Aufgabe, für die Sycamore 200 Sekunden benötigte, etwa 10.000 Jahre gebraucht hätte. Voilà: Quantenüberlegenheit.
Was war also der Einwand von IBM? Im Wesentlichen, dass es verschiedene Möglichkeiten gibt, einen klassischen Computer dazu zu bringen, eine Quantenmaschine zu simulieren, und dass die Software, die man schreibt, die Art und Weise, wie man Daten zerhackt und speichert, und die verwendete Hardware einen großen Unterschied machen, wie schnell die Simulation laufen kann. IBM sagte, Google sei davon ausgegangen, dass die Simulation in viele Teile zerlegt werden müsse, aber Summit ist mit 280 Petabyte Speicherplatz groß genug, um den gesamten Zustand von Sycamore auf einmal zu speichern. (Und IBM hat Summit gebaut, sollte es also wissen.)
Aber im Laufe der Jahrzehnte hat sich das Unternehmen den Ruf erworben, dass es Schwierigkeiten hat, seine Forschungsprojekte in kommerzielle Erfolge umzuwandeln. Ein Beispiel aus jüngster Zeit ist Watson, die Jeopardy spielende KI, die IBM in einen medizinischen Roboter-Guru verwandeln wollte. Trotz Dutzender Partnerschaften mit Gesundheitsdienstleistern gab es nur wenige kommerzielle Anwendungen, und selbst die, die es gab, lieferten gemischte Ergebnisse.
Das Quantencomputerteam versucht nach Gils Worten, diesen Kreislauf zu durchbrechen, indem es Forschung und Geschäftsentwicklung parallel betreibt. Kaum hatte es funktionierende Quantencomputer, machte es sie für Außenstehende zugänglich, indem es sie in die Cloud stellte, wo sie über eine einfache Drag-and-Drop-Schnittstelle in einem Webbrowser programmiert werden können. Die „IBM Q Experience“, die 2016 ins Leben gerufen wurde, besteht nun aus 15 öffentlich zugänglichen Quantencomputern mit einer Größe von fünf bis 53 Qubits. Sie werden monatlich von etwa 12 000 Menschen genutzt, von akademischen Forschern bis hin zu Schülern. Die Zeit auf den kleineren Maschinen ist kostenlos; IBM sagt, dass bereits mehr als 100 Kunden für die Nutzung der größeren Maschinen zahlen (wie viel, wird nicht gesagt).
Keines dieser Geräte – oder irgendein anderer Quantencomputer auf der Welt, mit Ausnahme von Googles Sycamore – hat bisher gezeigt, dass es eine klassische Maschine bei irgendetwas schlagen kann. Für IBM ist das im Moment auch nicht das Wichtigste. Indem das Unternehmen die Maschinen online zur Verfügung stellt, erfährt es, welche Anforderungen künftige Kunden an sie stellen könnten, und ermöglicht es externen Softwareentwicklern, zu lernen, wie man Code für sie schreibt.
Dieser Zyklus, so glaubt das Unternehmen, ist der schnellste Weg zum so genannten Quantenvorteil, einer Zukunft, in der Quantencomputer die klassischen Computer nicht unbedingt in den Schatten stellen, aber einige nützliche Dinge etwas schneller oder effizienter erledigen werden – genug, um sie wirtschaftlich lohnend zu machen. Während die Quantenvorherrschaft ein einzelner Meilenstein ist, ist der Quantenvorteil ein „Kontinuum“, sagen die IBMer – eine sich allmählich erweiternde Welt der Möglichkeiten.
Das ist also Gils große vereinheitlichte Theorie von IBM: dass das Unternehmen durch die Kombination seines Erbes, seines technischen Know-hows, der Intelligenz anderer Leute und seines Engagements für Geschäftskunden nützliche Quantencomputer schneller und besser als jeder andere bauen kann.
In dieser Sicht der Dinge sieht IBM die Demonstration der Quantenüberlegenheit von Google als „einen Taschenspielertrick“, sagt Scott Aaronson, ein Physiker an der University of Texas in Austin, der an den von Google verwendeten Quantenalgorithmen mitgewirkt hat. Im besten Fall ist es eine auffällige Ablenkung von der eigentlichen Arbeit, die geleistet werden muss. Schlimmstenfalls ist es irreführend, denn es könnte den Eindruck erwecken, dass Quantencomputer klassische Computer in allen Bereichen schlagen können und nicht nur in einer ganz bestimmten Aufgabe. „Supremacy‘ ist ein englisches Wort, das von der Öffentlichkeit unmöglich falsch interpretiert werden kann“, sagt Gil.
Google sieht das natürlich ganz anders.
Einstieg in den Emporkömmling
Google war ein frühreifes achtjähriges Unternehmen, als es 2006 begann, an Quantenproblemen herumzubasteln, aber es gründete erst 2012 ein eigenes Quantenlabor – im selben Jahr, in dem John Preskill, ein Physiker am Caltech, den Begriff „Quantenüberlegenheit“ prägte.“
Der Leiter des Labors ist Hartmut Neven, ein deutscher Informatiker mit einer souveränen Ausstrahlung und einer Vorliebe für Burning-Man-Chic; ich habe ihn einmal in einem pelzigen blauen Mantel und ein anderes Mal in einem komplett silbernen Outfit gesehen, das ihn wie einen schäbigen Astronauten aussehen ließ. („Meine Frau kauft diese Sachen für mich“, erklärte er.) Anfangs kaufte Neven eine Maschine, die von einer externen Firma, D-Wave, gebaut wurde, und verbrachte eine Weile damit, auf ihr die Quantenüberlegenheit zu erreichen, jedoch ohne Erfolg. Er sagt, er habe Larry Page, den damaligen CEO von Google, davon überzeugt, 2014 in den Bau von Quantencomputern zu investieren, indem er ihm versprach, dass Google Preskills Herausforderung annehmen würde: „Wir sagten ihm: ‚Hör zu, Larry, in drei Jahren kommen wir zurück und legen dir einen Prototyp-Chip auf den Tisch, der zumindest ein Problem berechnen kann, das die Fähigkeiten klassischer Maschinen übersteigt.'“
Da IBM nicht über das nötige Quanten-Know-how verfügte, engagierte Google ein externes Team unter der Leitung von John Martinis, einem Physiker an der University of California, Santa Barbara. Martinis und seine Gruppe gehörten bereits zu den weltbesten Quantencomputerherstellern – es war ihnen gelungen, bis zu neun Qubits aneinander zu reihen – und Nevens Versprechen an Page schien ihnen ein lohnendes Ziel zu sein, das sie anstreben sollten.
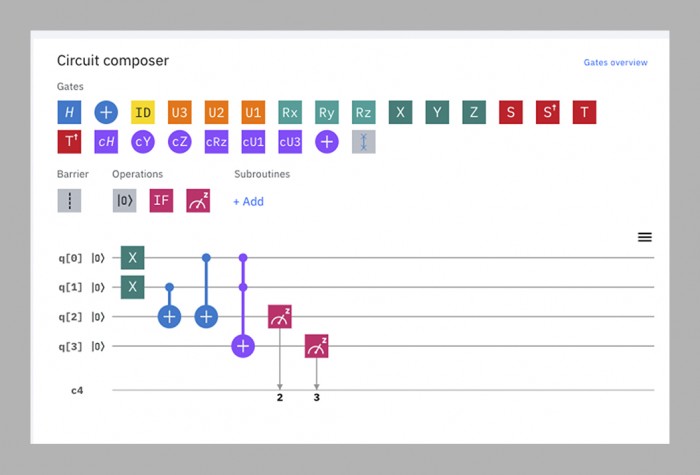
Die Dreijahresfrist kam und ging, während Martinis Team darum kämpfte, einen Chip zu bauen, der sowohl groß als auch stabil genug für die Herausforderung war. Im Jahr 2018 stellte Google seinen bisher größten Prozessor, Bristlecone, vor. Mit 72 Qubits war er allen seinen Konkurrenten weit voraus, und Martinis sagte voraus, dass er noch im selben Jahr die Quantenvorherrschaft erlangen würde. Einige Teammitglieder hatten jedoch parallel an einer anderen Chiparchitektur namens Sycamore gearbeitet, die mit weniger Qubits mehr leisten konnte. So war es ein Chip mit 53 Qubits – ursprünglich waren es 54, aber eines davon funktionierte nicht -, der im letzten Herbst die Überlegenheit demonstrierte.
Für praktische Zwecke ist das in dieser Demonstration verwendete Programm praktisch nutzlos – es erzeugt Zufallszahlen, wofür man keinen Quantencomputer braucht. Aber es erzeugt sie auf eine besondere Art und Weise, die ein klassischer Computer nur sehr schwer nachbilden könnte, wodurch der Beweis des Konzepts erbracht wurde (siehe gegenüberliegende Seite).
Fragte man IBMer, was sie von dieser Leistung hielten, erntete man gequälte Blicke. „Ich mag das Wort nicht und ich mag die Implikationen nicht“, sagt Jay Gambetta, ein zurückhaltend sprechender Australier, der das Quantenteam von IBM leitet. Das Problem, sagt er, ist, dass es praktisch unmöglich ist, vorherzusagen, ob eine bestimmte Quantenberechnung für eine klassische Maschine schwierig sein wird, so dass es nicht hilft, andere Fälle zu finden.
Für alle, mit denen ich außerhalb von IBM gesprochen habe, grenzt diese Weigerung, die Quantenüberlegenheit als signifikant zu betrachten, an Starrköpfigkeit. „Jeder, der jemals ein kommerziell relevantes Angebot haben wird, muss zuerst seine Überlegenheit beweisen. Ich denke, das ist einfach nur logisch“, sagt Neven. Sogar Will Oliver, ein sanftmütiger MIT-Physiker, der zu den unparteiischsten Beobachtern des Streits gehört, sagt: „Es ist ein sehr wichtiger Meilenstein, wenn ein Quantencomputer einen klassischen Computer bei einer Aufgabe übertrifft, was auch immer das sein mag.“
Der Quantensprung
Ungeachtet dessen, ob man mit Googles oder IBMs Position einverstanden ist, ist das nächste Ziel klar, sagt Oliver: einen Quantencomputer zu bauen, der etwas Nützliches tun kann. Die Hoffnung ist, dass solche Maschinen eines Tages Probleme lösen könnten, für die heute noch unvorstellbare Mengen an Brute-Force-Rechenleistung erforderlich sind, wie z. B. die Modellierung komplexer Moleküle zur Entdeckung neuer Medikamente und Materialien, die Optimierung des Verkehrsflusses in Städten in Echtzeit zur Verringerung von Staus oder die Erstellung längerfristiger Wettervorhersagen. (Irgendwann könnten sie in der Lage sein, die kryptografischen Codes zu knacken, die heute zur Sicherung von Kommunikation und Finanztransaktionen verwendet werden, obwohl bis dahin wahrscheinlich der größte Teil der Welt eine quantenresistente Kryptografie eingeführt haben wird.) Das Problem ist, dass es fast unmöglich ist, vorherzusagen, was die erste nützliche Aufgabe sein wird oder wie groß ein Computer sein muss, um sie zu erfüllen.
Diese Unsicherheit hat sowohl mit der Hardware als auch mit der Software zu tun. Auf der Hardwareseite geht Google davon aus, dass seine derzeitigen Chipdesigns es auf 100 bis 1.000 Qubits bringen können. Doch so wie die Leistung eines Autos nicht nur von der Größe des Motors abhängt, wird die Leistung eines Quantencomputers nicht einfach durch die Anzahl der Qubits bestimmt. Es gibt noch eine ganze Reihe anderer Faktoren, die zu berücksichtigen sind, z. B. wie lange sie vor Dekohärenz geschützt werden können, wie fehleranfällig sie sind, wie schnell sie arbeiten und wie sie miteinander verbunden sind. Das bedeutet, dass jeder Quantencomputer, der heute in Betrieb ist, nur einen Bruchteil seines vollen Potenzials erreicht.
Die Software für Quantencomputer steckt derweil ebenso in den Kinderschuhen wie die Maschinen selbst. In der klassischen Datenverarbeitung sind die Programmiersprachen heute mehrere Ebenen vom rohen „Maschinencode“ entfernt, den die frühen Softwareentwickler verwenden mussten, weil die Feinheiten der Datenspeicherung, -verarbeitung und -verschiebung bereits standardisiert sind. „Wenn man einen klassischen Computer programmiert, muss man nicht wissen, wie ein Transistor funktioniert“, sagt Dave Bacon, der die Software-Bemühungen des Google-Teams leitet. Der Quantencode hingegen muss genau auf die Qubits zugeschnitten sein, auf denen er läuft, um das Beste aus deren temperamentvoller Leistung herauszuholen. Das bedeutet, dass der Code für IBMs Chips nicht auf den Chips anderer Unternehmen laufen wird, und selbst Techniken zur Optimierung von Googles 53-Qubit-Sycamore werden nicht unbedingt auf seinem zukünftigen 100-Qubit-Geschwisterchen gut funktionieren. Noch wichtiger ist, dass niemand vorhersagen kann, wie schwierig ein Problem sein wird, das diese 100 Qubits lösen können.
Das Einzige, worauf man zu hoffen wagt, ist, dass Computer mit ein paar hundert Qubits in den nächsten Jahren dazu gebracht werden können, eine einigermaßen komplexe Chemie zu simulieren – vielleicht sogar genug, um die Suche nach einem neuen Medikament oder einer effizienteren Batterie voranzutreiben. Doch Dekohärenz und Fehler werden all diese Maschinen zum Stillstand bringen, bevor sie etwas wirklich Schwieriges wie das Knacken von Kryptographie leisten können.
Um einen Quantencomputer mit der Leistung von 1.000 Qubits zu bauen, bräuchte man eine Million tatsächlicher Qubits.
Dazu braucht man einen „fehlertoleranten“ Quantencomputer, der Fehler kompensieren und unbegrenzt weiterlaufen kann, genau wie klassische Computer. Die erwartete Lösung wird darin bestehen, Redundanz zu schaffen: Hunderte von Qubits sollen sich in einem gemeinsamen Quantenzustand wie ein einziges verhalten. Gemeinsam können sie die Fehler der einzelnen Qubits ausgleichen. Und wenn jedes Qubit der Dekohärenz erliegt, wird es von seinen Nachbarn wieder zum Leben erweckt, in einem nicht enden wollenden Zyklus der gegenseitigen Wiederbelebung.
Die typische Vorhersage ist, dass man bis zu 1.000 verbundene Qubits braucht, um diese Stabilität zu erreichen – das heißt, um einen Computer mit der Leistung von 1.000 Qubits zu bauen, braucht man eine Million tatsächlicher Qubits. Google schätzt „konservativ“, dass es innerhalb von 10 Jahren einen Prozessor mit einer Million Qubits bauen kann, sagt Neven, obwohl es einige große technische Hürden zu überwinden gibt, darunter eine, bei der IBM noch einen Vorteil gegenüber Google haben könnte (siehe gegenüberliegende Seite).
Bis dahin könnte sich einiges geändert haben. Die supraleitenden Qubits, die Google und IBM derzeit verwenden, könnten sich als die Vakuumröhren ihrer Zeit erweisen und durch etwas viel Stabileres und Zuverlässigeres ersetzt werden. Forscher auf der ganzen Welt experimentieren mit verschiedenen Methoden zur Herstellung von Qubits, aber nur wenige sind weit genug fortgeschritten, um damit funktionierende Computer zu bauen. Konkurrierende Start-ups wie Rigetti, IonQ oder Quantum Circuits könnten einen Vorsprung in einer bestimmten Technik entwickeln und die größeren Unternehmen überholen.
Eine Geschichte von zwei Transmonen
Die Transmonen-Qubits von Google und IBM sind fast identisch, mit einem kleinen, aber möglicherweise entscheidenden Unterschied.
Bei den Quantencomputern von Google und IBM werden die Qubits selbst durch Mikrowellenpulse gesteuert. Winzige Herstellungsfehler führen dazu, dass keine zwei Qubits auf Pulse mit genau derselben Frequenz reagieren. Dafür gibt es zwei Lösungen: Man kann die Frequenz der Pulse variieren, um den „Sweet Spot“ jedes Qubits zu finden, so wie man an einem schlecht gearbeiteten Schlüssel in einem Schloss rüttelt, bis es sich öffnet, oder man kann Magnetfelder verwenden, um jedes Qubit auf die richtige Frequenz zu „tunen“.
IBM verwendet die erste Methode, Google die zweite. Jeder Ansatz hat Vor- und Nachteile. Die abstimmbaren Qubits von Google arbeiten schneller und präziser, sind aber weniger stabil und erfordern mehr Schaltkreise. IBMs Qubits mit fester Frequenz sind stabiler und einfacher, laufen aber langsamer.
Aus technischer Sicht ist das Ganze ein ziemliches Hin und Her, zumindest in diesem Stadium. In Bezug auf die Unternehmensphilosophie ist es jedoch der Unterschied zwischen Google und IBM in einer Nussschale – oder besser gesagt, in einem Qubit.
Google hat sich entschieden, wendig zu sein. „Im Allgemeinen geht unsere Philosophie ein wenig mehr in Richtung höherer Kontrollierbarkeit auf Kosten der Zahlen, nach denen die Leute normalerweise suchen“, sagt Hartmut Neven.
IBM hingegen entschied sich für Zuverlässigkeit. „Es ist ein großer Unterschied, ob man ein Laborexperiment durchführt und eine Arbeit veröffentlicht oder ob man ein System mit einer Zuverlässigkeit von 98 % aufbaut, das die ganze Zeit läuft“, sagt Dario Gil.
Im Moment ist Google noch im Vorteil. Wenn die Maschinen jedoch größer werden, könnte der Vorteil auf IBM übergehen. Jedes Qubit wird durch seine eigenen Drähte gesteuert; ein abstimmbares Qubit erfordert einen zusätzlichen Draht. Die Verkabelung für Tausende oder Millionen von Qubits zu finden, wird eine der größten technischen Herausforderungen für die beiden Unternehmen sein. Martinis, der Leiter des Google-Teams, sagt, er habe persönlich die letzten drei Jahre damit verbracht, Lösungen für die Verkabelung zu finden. „Es ist ein so wichtiges Problem, dass ich daran gearbeitet habe“, scherzt er.
Aufgrund ihrer Größe und ihres Reichtums haben sowohl Google als auch IBM die Chance, ernsthafte Akteure im Quantencomputing-Geschäft zu werden. Unternehmen werden ihre Maschinen mieten, um Probleme zu lösen, so wie sie derzeit Cloud-basierten Datenspeicher und Rechenleistung von Amazon, Google, IBM oder Microsoft mieten. Und was als Kampf zwischen Physikern und Informatikern begann, wird sich zu einem Wettbewerb zwischen Geschäftsdienstleistungsabteilungen und Marketingabteilungen entwickeln.
Welches Unternehmen ist am besten geeignet, diesen Wettbewerb zu gewinnen? IBM mit seinen rückläufigen Einnahmen hat vielleicht ein größeres Gespür für die Dringlichkeit als Google. IBM weiß aus bitterer Erfahrung, was es kostet, wenn man zu langsam in einen Markt einsteigt: Im letzten Sommer hat das Unternehmen in seinem bisher teuersten Kauf 34 Milliarden Dollar für Red Hat, einen Anbieter von Open-Source-Cloud-Diensten, ausgegeben, um in diesem Bereich zu Amazon und Microsoft aufzuschließen und sein finanzielles Schicksal zu wenden. Die Strategie des Unternehmens, seine Quantencomputer in die Cloud zu stellen und von Anfang an ein kostenpflichtiges Geschäft aufzubauen, scheint ihm einen Vorsprung zu verschaffen.
Google hat vor kurzem begonnen, dem Beispiel von IBM zu folgen, und zu seinen kommerziellen Kunden gehören jetzt das US-Energieministerium, Volkswagen und Daimler. Der Grund dafür, dass dies nicht schon früher geschehen ist, ist laut Martinis einfach: „Wir hatten nicht die Ressourcen, um es in die Cloud zu stellen“.
Ob diese Entscheidung IBM einen Vorteil verschafft, lässt sich noch nicht sagen, aber wahrscheinlich wird es wichtiger sein, wie die beiden Unternehmen in den kommenden Jahren ihre anderen Stärken auf das Problem anwenden. IBM, so Gil, wird von seinem „Full-Stack“-Fachwissen in allen Bereichen profitieren, von der Materialwissenschaft über die Chipherstellung bis hin zur Betreuung großer Firmenkunden. Google hingegen kann sich einer Innovationskultur im Stil des Silicon Valley rühmen und hat reichlich Erfahrung mit der schnellen Skalierung von Operationen.
Was die Quantenüberlegenheit selbst betrifft, so wird dies ein wichtiger Moment in der Geschichte sein, aber das bedeutet nicht, dass er entscheidend sein wird. After all, everyone knows about the Wright brothers‘ first flight, but can anybody remember what they did afterwards?
Sign inSubscribe now