- Was ist ein Klassifikator?
- Klassifizierungsalgorithmen
Für die Nutzung von KI und maschinellem Lernen brauchte man früher einen datenwissenschaftlichen und technischen Hintergrund, aber neue benutzerfreundliche Tools und SaaS-Plattformen machen maschinelles Lernen für jeden zugänglich.
Klassifikatoren für maschinelles Lernen sind eine der wichtigsten Anwendungen der KI-Technologie – zur automatischen Analyse von Daten, zur Rationalisierung von Prozessen und zur Gewinnung wertvoller Erkenntnisse.
- Was ist ein Klassifikator beim maschinellen Lernen?
- Was ist der Unterschied zwischen einem Klassifikator und einem Modell?
- Testen Sie mit Ihrem eigenen Text
- Ergebnisse
- 5 Arten von Klassifizierungsalgorithmen
- Entscheidungsbaum
- Naive Bayes Classifier
- K-Nächste Nachbarn
- Support Vector Machines (SVM)
- Künstliche neuronale Netze
- Lassen Sie Klassifizierer des maschinellen Lernens für sich arbeiten
Was ist ein Klassifikator beim maschinellen Lernen?
Ein Klassifikator beim maschinellen Lernen ist ein Algorithmus, der Daten automatisch in eine oder mehrere „Klassen“ einordnet oder kategorisiert. Eines der gebräuchlichsten Beispiele ist ein E-Mail-Klassifikator, der E-Mails scannt, um sie nach Klassenetikett zu filtern: Spam oder Nicht-Spam.
Maschinelle Lernalgorithmen sind hilfreich, um Aufgaben zu automatisieren, die zuvor manuell erledigt werden mussten. Sie können viel Zeit und Geld sparen und Unternehmen effizienter machen.
Was ist der Unterschied zwischen einem Klassifikator und einem Modell?
Ein Klassifikator ist der Algorithmus selbst – die Regeln, die von Maschinen zur Klassifizierung von Daten verwendet werden. Ein Klassifizierungsmodell hingegen ist das Endergebnis des maschinellen Lernens Ihres Klassifizierers. Das Modell wird mit Hilfe des Klassifizierers trainiert, so dass das Modell letztendlich Ihre Daten klassifiziert.
Es gibt überwachte und nicht überwachte Klassifizierer. Unüberwachte Klassifizierer für maschinelles Lernen werden nur mit unmarkierten Datensätzen gefüttert, die sie anhand von Mustererkennung oder Strukturen und Anomalien in den Daten klassifizieren. Überwachte und halbüberwachte Klassifizierer werden mit Trainingsdatensätzen gefüttert, anhand derer sie lernen, Daten nach vorgegebenen Kategorien zu klassifizieren.
Die Stimmungsanalyse ist ein Beispiel für überwachtes maschinelles Lernen, bei dem Klassifizierer darauf trainiert werden, Text auf seine Meinungspolarität hin zu analysieren und den Text in die jeweilige Klasse einzuordnen: Positiv, Neutral oder Negativ. Probieren Sie dieses Modell der Stimmungsanalyse aus, um zu sehen, wie es funktioniert.
Testen Sie mit Ihrem eigenen Text
Ergebnisse
Maschinenlernende Klassifikatoren werden verwendet, um automatisch Kundenkommentare (wie den obigen) aus sozialen Medien, E-Mails, Online-Bewertungen usw. zu analysieren,
Andere Textanalysetechniken, wie die Themenklassifizierung, können Kundendiensttickets oder NPS-Umfragen automatisch sortieren, nach Themen kategorisieren (Preise, Funktionen, Support usw.) und sie an die richtige Abteilung oder den richtigen Mitarbeiter weiterleiten.
SaaS-Textanalyseplattformen wie MonkeyLearn bieten einen einfachen Zugang zu leistungsstarken Klassifizierungsalgorithmen, mit denen Sie in der Regel in wenigen Schritten Klassifizierungsmodelle nach Ihren Bedürfnissen und Kriterien erstellen können.
Maschinelle Lernklassifizierer gehen über eine einfache Datenzuordnung hinaus und ermöglichen es den Benutzern, Modelle ständig mit neuen Lerndaten zu aktualisieren und an sich ändernde Anforderungen anzupassen. Selbstfahrende Autos beispielsweise verwenden Klassifizierungsalgorithmen, um Bilddaten einer Kategorie zuzuordnen, sei es ein Stoppschild, ein Fußgänger oder ein anderes Auto, und lernen dabei ständig dazu und verbessern sich im Laufe der Zeit.
Aber was sind die wichtigsten Klassifizierungsalgorithmen und wie funktionieren sie?
5 Arten von Klassifizierungsalgorithmen
Abhängig von Ihren Bedürfnissen und Ihren Daten sollten diese 5 wichtigsten Klassifizierungsalgorithmen für Sie geeignet sein.
- Entscheidungsbaum
- Naive Bayes Classifier
- K-Nächste Nachbarn
- Support Vector Machines
- Künstliche Neuronale Netze
Entscheidungsbaum
Ein Entscheidungsbaum ist ein überwachter Klassifizierungsalgorithmus des maschinellen Lernens, der verwendet wird, um Modelle wie die Struktur eines Baumes zu erstellen. Er klassifiziert Daten in immer feinere Kategorien: vom „Baumstamm“ über „Äste“ bis hin zu „Blättern“. Er verwendet die Wenn-dann-Regel der Mathematik, um Unterkategorien zu erstellen, die in breitere Kategorien passen, und ermöglicht eine präzise, organische Kategorisierung.
So würde ein Entscheidungsbaum beispielsweise einzelne Sportarten kategorisieren:
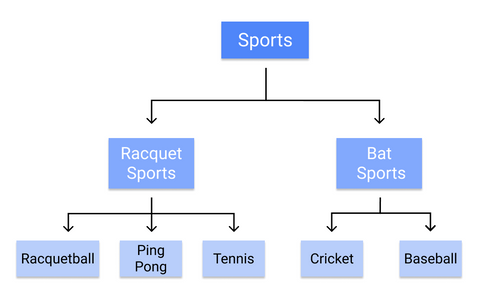
Da die Regeln sequentiell, vom Stamm bis zum Blatt, gelernt werden, benötigt ein Entscheidungsbaum von Beginn des Trainings an qualitativ hochwertige, saubere Daten, da sonst die Zweige überangepasst oder schief werden können.
Naive Bayes Classifier
Naive Bayes ist eine Familie von probabilistischen Algorithmen, die die Wahrscheinlichkeit berechnen, dass ein beliebiger Datenpunkt in eine oder mehrere Kategorien fällt (oder nicht). In der Textanalyse wird Naive Bayes verwendet, um Kundenkommentare, Nachrichtenartikel, E-Mails usw. zu kategorisieren, In der Textanalyse wird Naive Bayes verwendet, um Kundenkommentare, Nachrichtenartikel, E-Mails usw. in Themen oder „Tags“ zu kategorisieren, um sie nach vorher festgelegten Kriterien zu ordnen, z. B. so:
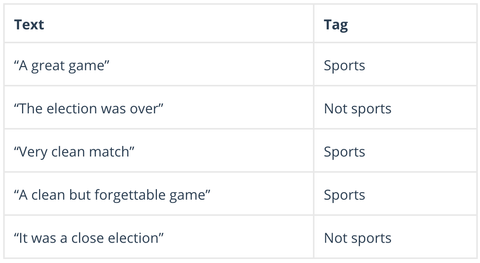
Naive Bayes-Algorithmen berechnen die Wahrscheinlichkeit jedes Tags für einen bestimmten Text und geben dann die höchste Wahrscheinlichkeit aus:

Das bedeutet, dass die Wahrscheinlichkeit von A, wenn B wahr ist, gleich der Wahrscheinlichkeit von B, wenn A wahr ist, mal der Wahrscheinlichkeit von A, wahr zu sein, geteilt durch die Wahrscheinlichkeit von B, wahr zu sein, ist.
Wenn man von Tag zu Tag geht, wird die Wahrscheinlichkeit berechnet, dass ein Datenpunkt zu einer bestimmten Kategorie gehört oder nicht: Ja/Nein.
K-Nächste Nachbarn
K-Nächste Nachbarn (k-NN) ist ein Algorithmus zur Mustererkennung, der Trainingsdatenpunkte speichert und daraus lernt, indem er berechnet, wie sie anderen Daten im n-dimensionalen Raum entsprechen. K-NN zielt darauf ab, die k nächstgelegenen verwandten Datenpunkte in zukünftigen, ungesehenen Daten zu finden.
In der Textanalyse würde k-NN ein bestimmtes Wort oder eine Phrase in eine vorher festgelegte Kategorie einordnen, indem es den nächsten Nachbarn berechnet: k wird durch eine Mehrheitsabstimmung seiner Nachbarn entschieden. Wenn k = 1 ist, wird es der Klasse zugeordnet, die der 1 am nächsten liegt.
Support Vector Machines (SVM)
SVM-Algorithmen klassifizieren Daten und trainieren Modelle innerhalb endlicher Polaritätsgrade und erstellen ein dreidimensionales Klassifizierungsmodell, das über die X/Y-Vorhersageachsen hinausgeht.
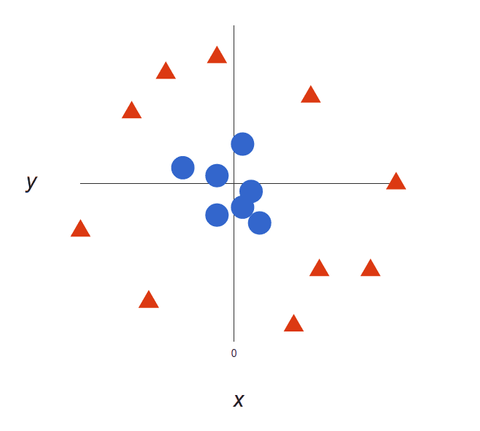
Werfen Sie einen Blick auf diese visuelle Darstellung, um zu verstehen, wie SVM-Algorithmen funktionieren. Wir haben zwei Tags: rot und blau, mit zwei Datenmerkmalen: X und Y, und wir trainieren unseren Klassifikator so, dass er eine X/Y-Koordinate entweder als rot oder blau ausgibt.
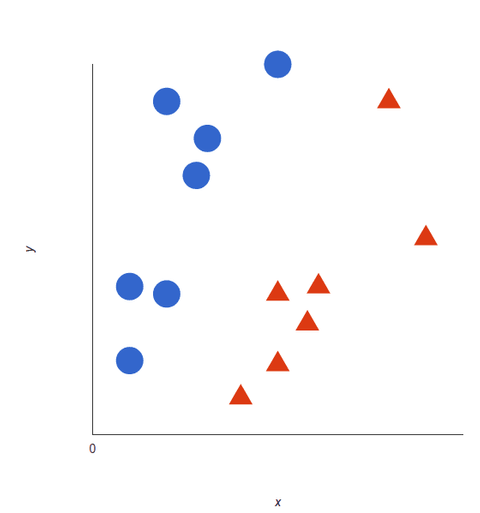
Der SVM weist eine Hyperebene zu, die die Tags am besten trennt (unterscheidet). In zwei Dimensionen ist dies einfach eine gerade Linie. Blaue Tags fallen auf die eine Seite der Hyperebene und rote auf die andere.
Um das Training des maschinellen Lernmodells zu maximieren, ist die beste Hyperebene diejenige mit dem größten Abstand zwischen den einzelnen Tags:
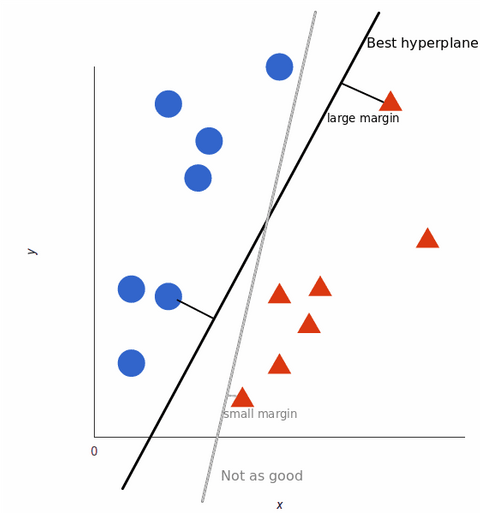
Wenn unsere Datensätze komplexer werden, kann es sein, dass es nicht möglich ist, eine einzige Linie zu zeichnen, um zwischen den beiden Klassen zu unterscheiden:
SVM-Algorithmen eignen sich hervorragend zur Klassifizierung, denn je komplexer die Daten sind, desto genauer wird die Vorhersage. Stellen Sie sich die obige Grafik als dreidimensionale Ausgabe vor, zu der eine Z-Achse hinzugefügt wurde, so dass sie zu einem Kreis wird.
Zurückgeführt auf 2D sieht sie mit der besten Hyperebene wie folgt aus:
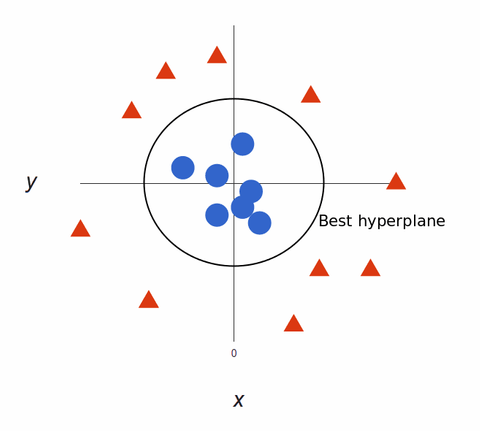
SVM-Algorithmen erstellen äußerst genaue Modelle für maschinelles Lernen, da sie mehrdimensional sind.
Künstliche neuronale Netze
Künstliche neuronale Netze sind keine „Art“ von Algorithmus, sondern vielmehr eine Sammlung von Algorithmen, die zusammenarbeiten, um Probleme zu lösen.
Künstliche neuronale Netze sind so konzipiert, dass sie ähnlich wie das menschliche Gehirn funktionieren. Sie verbinden Problemlösungsprozesse in einer Kette von Ereignissen, so dass, sobald ein Algorithmus oder Prozess ein Problem gelöst hat, der nächste Algorithmus (oder das nächste Glied in der Kette) aktiviert wird.
Künstliche neuronale Netze oder „Deep Learning“-Modelle erfordern riesige Mengen an Trainingsdaten, da ihre Prozesse sehr fortschrittlich sind, aber sobald sie richtig trainiert wurden, können sie mehr leisten als andere, individuelle Algorithmen.
Es gibt eine Vielzahl von künstlichen neuronalen Netzen, einschließlich Faltungsalgorithmen, rekurrenten Netzen, Feed-Forward-Netzen usw., und die Architektur des maschinellen Lernens, die für Ihre Bedürfnisse am besten geeignet ist, hängt von dem Problem ab, das Sie lösen wollen.
Lassen Sie Klassifizierer des maschinellen Lernens für sich arbeiten
Klassifizierungsalgorithmen ermöglichen die Automatisierung von Aufgaben des maschinellen Lernens, die noch vor wenigen Jahren undenkbar waren. Und, was noch besser ist, sie ermöglichen es Ihnen, KI-Modelle auf die Bedürfnisse, die Sprache und die Kriterien Ihres Unternehmens zu trainieren, die viel schneller und mit größerer Genauigkeit arbeiten, als es Menschen jemals könnten.
MonkeyLearn ist eine Plattform für die Textanalyse mit maschinellem Lernen, die die Leistung von Klassifizierern mit maschinellem Lernen mit einer äußerst benutzerfreundlichen Oberfläche nutzt, so dass Sie Prozesse rationalisieren und das Beste aus Ihren Textdaten herausholen können, um wertvolle Erkenntnisse zu gewinnen.
Testen Sie diese vortrainierten Klassifizierungsmodelle, um zu sehen, wie es funktioniert:
- NPS-Umfrage-Feedback-Klassifizierer: Klassifizieren Sie offene Umfrageantworten automatisch in die Kategorien Kundensupport, Benutzerfreundlichkeit, Funktionen und Preis
- Sentiment-Analysator: Analysieren Sie jeden Text auf die Polarität der Meinung: Positiv, Negativ, Neutral
- Email Intent Classifier: automatische Klassifizierung von Email-Antworten als interessiert, nicht interessiert, Autoresponder, Email Bounce, Abmeldung oder falsche Person
Oder vereinbaren Sie eine kostenlose Demo, um alles zu sehen, was MonkeyLearn zu bieten hat.