En octobre dernier, Google a annoncé qu’une de ces puces, appelée Sycamore, était devenue la première à démontrer la « suprématie quantique » en réalisant une tâche qui serait pratiquement impossible sur une machine classique. Avec seulement 53 qubits, Sycamore a effectué en quelques minutes un calcul qui, selon Google, aurait pris 10 000 ans au superordinateur le plus puissant du monde, Summit. Google a vanté cette avancée majeure, la comparant au lancement du Spoutnik ou au premier vol des frères Wright – le seuil d’une nouvelle ère de machines qui ferait passer le plus puissant ordinateur actuel pour un boulier.
Lors d’une conférence de presse dans le laboratoire de Santa Barbara, l’équipe de Google a joyeusement répondu aux questions des journalistes pendant près de trois heures. Mais leur bonne humeur n’a pas pu tout à fait masquer une tension sous-jacente. Deux jours plus tôt, des chercheurs d’IBM, le principal rival de Google en matière d’informatique quantique, avaient torpillé sa grande révélation. Ils avaient publié un article qui accusait essentiellement les Googlers de s’être trompés dans leurs calculs. IBM a estimé qu’il aurait fallu à Summit quelques jours seulement, et non des millénaires, pour reproduire ce que Sycamore avait fait. Lorsqu’on lui a demandé ce qu’il pensait du résultat d’IBM, Hartmut Neven, le chef de l’équipe de Google, a évité de manière pointue de donner une réponse directe.

Vous pourriez écarter cette affaire comme une simple querelle académique – et dans un sens, c’était le cas. Même si IBM avait raison, Sycamore avait quand même fait le calcul mille fois plus vite que Summit ne l’aurait fait. Et il ne se passerait probablement que quelques mois avant que Google ne construise une machine quantique légèrement plus grande qui prouverait le point sans aucun doute.
L’objection plus profonde d’IBM, cependant, n’était pas que l’expérience de Google était moins réussie que ce qui était prétendu, mais qu’il s’agissait d’un test sans signification en premier lieu. Contrairement à la plupart du monde de l’informatique quantique, IBM ne pense pas que la « suprématie quantique » soit le moment Wright brothers de la technologie ; en fait, elle ne croit même pas qu’il y aura un tel moment.
IBM poursuit plutôt une mesure très différente du succès, quelque chose qu’elle appelle « avantage quantique ». Il ne s’agit pas d’une simple différence de mots ou même de science, mais d’une position philosophique qui trouve ses racines dans l’histoire, la culture et les ambitions d’IBM – et, peut-être, dans le fait que, depuis huit ans, son chiffre d’affaires et son bénéfice ont connu un déclin presque ininterrompu, tandis que Google et sa société mère Alphabet n’ont fait que voir leurs chiffres augmenter. Ce contexte, et ces objectifs divergents, pourraient influencer celui qui – si l’un ou l’autre – sort en tête de la course à l’informatique quantique.
Des mondes à part
La courbe élégante et balayée du centre de recherche Thomas J. Watson d’IBM dans la banlieue nord de New York, chef-d’œuvre néo-futuriste de l’architecte finlandais Eero Saarinen, est un continent et un univers loin des fouilles anodines de l’équipe Google. Achevé en 1961 avec le boni qu’IBM a tiré des ordinateurs centraux, il a une qualité de musée, rappelant à tous ceux qui y travaillent les percées de l’entreprise dans tous les domaines, de la géométrie fractale aux supraconducteurs en passant par l’intelligence artificielle et l’informatique quantique.
Le chef de la division de la recherche, qui compte 4 000 personnes, est Dario Gil, un Espagnol dont le discours rapide fait la course pour suivre son zèle presque évangélique. Les deux fois où je lui ai parlé, il a égrené des jalons historiques destinés à souligner combien de temps IBM a été impliqué dans la recherche liée à l’informatique quantique (voir la chronologie à droite).


Une grande expérience : Théorie et pratique quantiques
L’élément de base d’un ordinateur quantique est le bit quantique, ou qubit. Dans un ordinateur classique, un bit peut stocker soit un 0, soit un 1. Un qubit peut stocker non seulement 0 ou 1, mais aussi un état intermédiaire appelé superposition – qui peut prendre beaucoup de valeurs différentes. Par analogie, si l’information était une couleur, un bit classique pourrait être soit noir, soit blanc. Un qubit, lorsqu’il est en superposition, pourrait être n’importe quelle couleur du spectre, et pourrait également varier en luminosité.
Le résultat est qu’un qubit peut stocker et traiter une vaste quantité d’informations par rapport à un bit – et la capacité augmente de façon exponentielle lorsque vous connectez des qubits ensemble. Stocker toutes les informations des 53 qubits de la puce Sycamore de Google nécessiterait environ 72 pétaoctets (72 milliards de gigaoctets) de mémoire informatique classique. Il ne faut pas beaucoup plus de qubits avant d’avoir besoin d’un ordinateur classique de la taille de la planète.
Mais ce n’est pas simple. Délicats et facilement perturbés, les qubits doivent être presque parfaitement isolés de la chaleur, des vibrations et des atomes parasites – d’où les réfrigérateurs « chandeliers » du laboratoire quantique de Google. Même dans ce cas, ils peuvent fonctionner tout au plus pendant quelques centaines de microsecondes avant de se « décohérer » et de perdre leur superposition.
Et les ordinateurs quantiques ne sont pas toujours plus rapides que les ordinateurs classiques. Ils sont juste différents, plus rapides pour certaines choses et plus lents pour d’autres, et nécessitent différents types de logiciels. Pour comparer leurs performances, il faut écrire un programme classique qui simule approximativement le programme quantique.
Pour son expérience, Google a choisi un test d’étalonnage appelé « échantillonnage aléatoire de circuits quantiques ». Il génère des millions de nombres aléatoires, mais avec de légers biais statistiques qui sont la marque de fabrique de l’algorithme quantique. Si Sycamore était une calculatrice de poche, cela reviendrait à appuyer sur des boutons au hasard et à vérifier que l’écran affiche les résultats escomptés.
Gogle en a simulé certaines parties sur ses propres fermes de serveurs massives ainsi que sur Summit, le plus grand superordinateur du monde, au Oak Ridge National Laboratory. Les chercheurs ont estimé que la réalisation de l’ensemble du travail, qui a demandé 200 secondes à Sycamore, aurait pris environ 10 000 ans à Summit. Voilà : la suprématie quantique.
Alors, quelle était l’objection d’IBM ? Essentiellement, qu’il existe différentes façons d’amener un ordinateur classique à simuler une machine quantique – et que le logiciel que vous écrivez, la façon dont vous découpez les données et les stockez, et le matériel que vous utilisez font tous une grande différence dans la rapidité d’exécution de la simulation. Selon IBM, Google a supposé que la simulation devrait être découpée en de nombreux morceaux, mais Summit, avec ses 280 pétaoctets de stockage, est suffisamment grand pour contenir l’état complet de Sycamore en une seule fois. (Et IBM a construit Summit, donc il devrait savoir.)
Mais au fil des décennies, l’entreprise a acquis la réputation de lutter pour transformer ses projets de recherche en succès commerciaux. Prenez, plus récemment, Watson, l’IA jouant à Jeopardy qu’IBM a essayé de convertir en gourou médical robotisé. Il était censé fournir des diagnostics et identifier des tendances dans des océans de données médicales, mais malgré des dizaines de partenariats avec des fournisseurs de soins de santé, il y a eu peu d’applications commerciales, et même celles qui ont émergé ont donné des résultats mitigés.
L’équipe d’informatique quantique, selon le récit de Gil, essaie de briser ce cycle en faisant la recherche et le développement commercial en parallèle. Presque aussitôt qu’elle a disposé d’ordinateurs quantiques fonctionnels, elle a commencé à les rendre accessibles aux personnes extérieures en les plaçant sur le cloud, où ils peuvent être programmés au moyen d’une simple interface de type glisser-déposer qui fonctionne dans un navigateur web. L' »IBM Q Experience », lancée en 2016, se compose désormais de 15 ordinateurs quantiques accessibles au public, dont la taille varie de cinq à 53 qubits. Quelque 12 000 personnes par mois les utilisent, allant des chercheurs universitaires aux écoliers. Le temps passé sur les petites machines est gratuit ; IBM dit qu’il a déjà plus de 100 clients qui paient (il ne dira pas combien) pour utiliser les plus grandes.
Aucun de ces appareils – ni aucun autre ordinateur quantique dans le monde, à l’exception de Sycamore de Google – n’a encore montré qu’il pouvait battre une machine classique à quoi que ce soit. Pour IBM, ce n’est pas l’essentiel pour le moment. La mise à disposition des machines en ligne permet à l’entreprise d’apprendre ce dont ses futurs clients pourraient avoir besoin et aux développeurs de logiciels externes d’apprendre à écrire du code pour ces machines. Cela, à son tour, contribue à leur développement, rendant les ordinateurs quantiques suivants meilleurs.
Ce cycle, estime l’entreprise, est la voie la plus rapide vers son soi-disant avantage quantique, un avenir dans lequel les ordinateurs quantiques ne laisseront pas nécessairement les ordinateurs classiques dans la poussière, mais feront certaines choses utiles un peu plus rapidement ou plus efficacement – suffisamment pour les rendre économiquement intéressants. Alors que la suprématie quantique est un jalon unique, l’avantage quantique est un « continuum », disent les IBMers – un monde de possibilités qui s’étend progressivement.
Voici donc la grande théorie unifiée de Gil sur IBM : en combinant son héritage, son expertise technique, la matière grise d’autres personnes et son dévouement aux clients commerciaux, elle peut construire des ordinateurs quantiques utiles plus tôt et mieux que quiconque.
Dans cette vision des choses, IBM voit la démonstration de suprématie quantique de Google comme « un tour de parloir », dit Scott Aaronson, physicien à l’Université du Texas à Austin, qui a contribué aux algorithmes quantiques utilisés par Google. Au mieux, il s’agit d’une distraction tape-à-l’œil qui détourne l’attention du travail réel qui doit être effectué. Au pire, elle est trompeuse, car elle pourrait faire croire aux gens que les ordinateurs quantiques peuvent battre les ordinateurs classiques dans n’importe quel domaine plutôt que dans une tâche très précise. « ‘Suprématie’ est un mot anglais qu’il sera impossible pour le public de ne pas mal interpréter », dit Gil.
Google, bien sûr, voit les choses plutôt différemment.
Enter the upstart
Google était une entreprise précoce de huit ans lorsqu’elle a commencé à bricoler des problèmes quantiques en 2006, mais elle n’a pas formé de laboratoire quantique dédié avant 2012 – l’année même où John Preskill, un physicien de Caltech, a inventé le terme « suprématie quantique ». »
Le chef du laboratoire est Hartmut Neven, un informaticien allemand à la présence imposante et au penchant pour le chic façon Burning Man ; je l’ai vu une fois dans un manteau bleu en fourrure et une autre fois dans une tenue entièrement argentée qui le faisait ressembler à un astronaute grunge. (« C’est ma femme qui m’achète ces choses », explique-t-il.) Au départ, Neven a acheté une machine construite par une société extérieure, D-Wave, et a passé un certain temps à essayer d’atteindre la suprématie quantique sur celle-ci, mais sans succès. Il dit avoir convaincu Larry Page, alors PDG de Google, d’investir dans la construction d’ordinateurs quantiques en 2014 en lui promettant que Google relèverait le défi de Preskill : « Nous lui avons dit : « Écoutez, Larry, dans trois ans, nous reviendrons et nous mettrons sur votre table un prototype de puce qui pourra au moins calculer un problème dépassant les capacités des machines classiques. »
Faute de l’expertise quantique d’IBM, Google a engagé une équipe extérieure, dirigée par John Martinis, un physicien de l’Université de Californie à Santa Barbara. Martinis et son groupe faisaient déjà partie des meilleurs fabricants d’ordinateurs quantiques au monde – ils avaient réussi à enchaîner jusqu’à neuf qubits ensemble – et la promesse de Neven à Page semblait être un objectif digne d’intérêt pour eux.
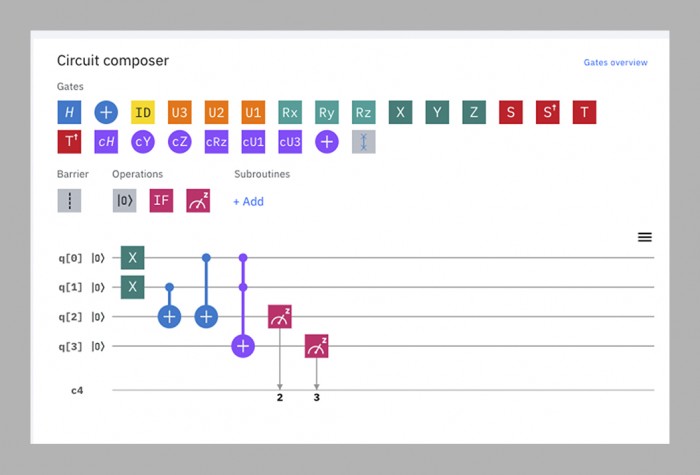
L’échéance de trois ans est passée alors que l’équipe de Martinis luttait pour fabriquer une puce à la fois assez grande et assez stable pour relever le défi. En 2018, Google a publié son plus grand processeur à ce jour, Bristlecone. Avec 72 qubits, il était bien en avance sur tout ce que ses rivaux avaient fabriqué, et Martinis a prédit qu’il atteindrait la suprématie quantique la même année. Mais quelques membres de l’équipe avaient travaillé en parallèle sur une autre architecture de puce, appelée Sycamore, qui s’est avérée capable de faire plus avec moins de qubits. C’est donc une puce de 53 qubits – à l’origine 54, mais l’un d’eux a mal fonctionné – qui a démontré sa suprématie l’automne dernier.
À des fins pratiques, le programme utilisé dans cette démonstration est pratiquement inutile – il génère des nombres aléatoires, ce qui n’est pas quelque chose pour lequel vous avez besoin d’un ordinateur quantique. Mais il les génère d’une manière particulière qu’un ordinateur classique aurait beaucoup de mal à reproduire, établissant ainsi la preuve du concept (voir page ci-contre).
Demandez aux IBMers ce qu’ils pensent de cette réalisation, et vous obtenez des regards peinés. « Je n’aime pas le mot , et je n’aime pas les implications », dit Jay Gambetta, un Australien au parler prudent qui dirige l’équipe quantique d’IBM. Le problème, dit-il, est qu’il est pratiquement impossible de prédire si un calcul quantique donné sera difficile pour une machine classique, donc le montrer dans un cas ne vous aide pas à trouver d’autres cas.
Pour tous ceux à qui j’ai parlé en dehors d’IBM, ce refus de traiter la suprématie quantique comme significative frise l’entêtement. « Toute personne qui aura un jour une offre commercialement pertinente – ils doivent d’abord montrer la suprématie. Je pense que c’est tout simplement la logique de base », déclare M. Neven. Même Will Oliver, un physicien du MIT aux manières douces qui a été l’un des observateurs les plus impartiaux de la prise de bec, déclare : « C’est une étape très importante de montrer qu’un ordinateur quantique surpasse un ordinateur classique dans une certaine tâche, quelle qu’elle soit. »
Le saut quantique
Que vous soyez d’accord avec la position de Google ou d’IBM, le prochain objectif est clair, dit Oliver : construire un ordinateur quantique capable de faire quelque chose d’utile. L’espoir est que de telles machines puissent un jour résoudre des problèmes qui requièrent aujourd’hui des quantités irréalisables de puissance de calcul brute, comme la modélisation de molécules complexes pour aider à découvrir de nouveaux médicaments et matériaux, ou l’optimisation des flux de trafic urbain en temps réel pour réduire la congestion, ou encore la réalisation de prévisions météorologiques à plus long terme. (Un jour, ils pourraient être capables de craquer les codes cryptographiques utilisés aujourd’hui pour sécuriser les communications et les transactions financières, mais d’ici là, la plupart des pays du monde auront probablement adopté une cryptographie résistante aux quanta). Le problème est qu’il est presque impossible de prédire quelle sera la première tâche utile, ou quelle sera la taille de l’ordinateur nécessaire pour l’accomplir.
Cette incertitude concerne à la fois le matériel et le logiciel. Sur le plan matériel, Google estime que ses conceptions actuelles de puces peuvent l’amener à quelque part entre 100 et 1 000 qubits. Cependant, tout comme les performances d’une voiture ne dépendent pas uniquement de la taille du moteur, celles d’un ordinateur quantique ne sont pas simplement déterminées par son nombre de qubits. Il faut tenir compte d’un grand nombre d’autres facteurs, notamment la durée pendant laquelle on peut empêcher la décohésion des qubits, leur vulnérabilité aux erreurs, leur vitesse de fonctionnement et la manière dont ils sont interconnectés. Cela signifie que tout ordinateur quantique fonctionnant aujourd’hui n’atteint qu’une fraction de son plein potentiel.
Les logiciels pour les ordinateurs quantiques, quant à eux, en sont autant à leurs balbutiements que les machines elles-mêmes. Dans l’informatique classique, les langages de programmation sont désormais éloignés de plusieurs niveaux du « code machine » brut que les premiers développeurs de logiciels devaient utiliser, car les détails de la façon dont les données sont stockées, traitées et déplacées sont déjà normalisés. « Sur un ordinateur classique, lorsque vous le programmez, vous n’avez pas besoin de savoir comment fonctionne un transistor », explique Dave Bacon, qui dirige l’effort logiciel de l’équipe Google. Le code quantique, en revanche, doit être hautement adapté aux qubits sur lesquels il fonctionnera, de manière à tirer le meilleur parti de leurs performances capricieuses. Cela signifie que le code des puces d’IBM ne fonctionnera pas sur celles d’autres entreprises, et que même les techniques d’optimisation du Sycamore à 53 qubits de Google ne fonctionneront pas nécessairement sur son futur frère à 100 qubits. Plus important encore, cela signifie que personne ne peut prédire à quel point ces 100 qubits seront capables de s’attaquer à un problème difficile.
Le plus que quiconque ose espérer est que les ordinateurs dotés de quelques centaines de qubits seront cajolés pour simuler une chimie modérément complexe dans les prochaines années – peut-être même suffisamment pour faire avancer la recherche d’un nouveau médicament ou d’une batterie plus efficace. Pourtant, la décohérence et les erreurs mettront toutes ces machines à l’arrêt avant qu’elles ne puissent faire quelque chose de vraiment difficile comme casser la cryptographie.
Pour construire un ordinateur quantique avec la puissance de 1 000 qubits, il faudrait un million de qubits réels.
Cela nécessitera un ordinateur quantique « tolérant aux pannes », capable de compenser les erreurs et de se maintenir indéfiniment en fonctionnement, comme le font les ordinateurs classiques. La solution attendue sera de créer de la redondance : faire en sorte que des centaines de qubits agissent comme un seul, dans un état quantique partagé. Collectivement, ils peuvent corriger les erreurs des qubits individuels. Et lorsque chaque qubit succombera à la décohérence, ses voisins le ramèneront à la vie, dans un cycle sans fin de réanimation mutuelle.
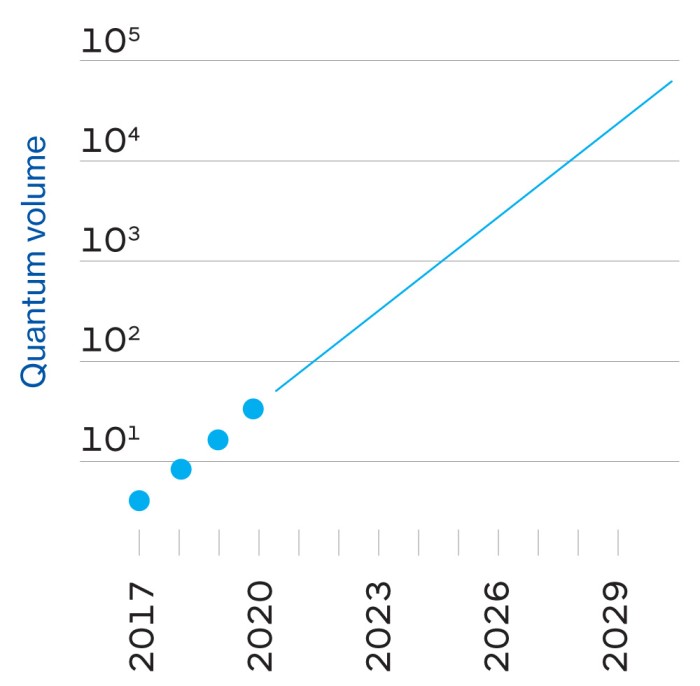
La prédiction typique est qu’il faudrait jusqu’à 1 000 qubits conjoints pour atteindre cette stabilité – ce qui signifie que pour construire un ordinateur avec la puissance de 1 000 qubits, il faudrait un million de qubits réels. Google estime « prudemment » qu’il peut construire un processeur à un million de qubits d’ici 10 ans, dit Neven, bien qu’il y ait de gros obstacles techniques à surmonter, dont un dans lequel IBM pourrait encore avoir l’avantage sur Google (voir page ci-contre).
D’ici là, beaucoup de choses pourraient avoir changé. Les qubits supraconducteurs que Google et IBM utilisent actuellement pourraient s’avérer être les tubes à vide de leur époque, remplacés par quelque chose de beaucoup plus stable et fiable. Les chercheurs du monde entier expérimentent diverses méthodes de fabrication de qubits, mais peu d’entre eux sont suffisamment avancés pour construire des ordinateurs fonctionnels. Des startups rivales comme Rigetti, IonQ ou Quantum Circuits pourraient développer un avantage dans une technique particulière et dépasser les grandes entreprises.
Un conte de deux transmons
Les qubits transmon de Google et d’IBM sont presque identiques, à une petite différence près, mais potentiellement cruciale.
Dans les ordinateurs quantiques de Google et d’IBM, les qubits eux-mêmes sont contrôlés par des impulsions micro-ondes. De minuscules défauts de fabrication font qu’il n’y a pas deux qubits qui répondent à des impulsions ayant exactement la même fréquence. Il existe deux solutions à ce problème : faire varier la fréquence des impulsions pour trouver le point idéal de chaque qubit, comme on secoue une clé mal taillée dans une serrure jusqu’à ce qu’elle s’ouvre ; ou utiliser des champs magnétiques pour « accorder » chaque qubit à la bonne fréquence.
IBM utilise la première méthode ; Google utilise la seconde. Chaque approche présente des avantages et des inconvénients. Les qubits accordables de Google fonctionnent plus rapidement et plus précisément, mais ils sont moins stables et nécessitent plus de circuits. Les qubits à fréquence fixe d’IBM sont plus stables et plus simples, mais fonctionnent plus lentement.
D’un point de vue technique, c’est à peu près un pile ou face, du moins à ce stade. En termes de philosophie d’entreprise, cependant, c’est la différence entre Google et IBM en un mot – ou plutôt, en un qubit.
Google a choisi d’être agile. « En général, notre philosophie va un peu plus dans le sens d’une plus grande contrôlabilité au détriment des chiffres que les gens recherchent généralement », explique Hartmut Neven.
IBM, en revanche, a choisi la fiabilité. « Il y a une énorme différence entre faire une expérience en laboratoire et publier un article, et mettre en place un système avec, par exemple, une fiabilité de 98% où vous pouvez le faire fonctionner tout le temps », dit Dario Gil.
Pour l’instant, Google a l’avantage. Mais à mesure que les machines deviennent plus grandes, l’avantage pourrait revenir à IBM. Chaque qubit est contrôlé par ses propres fils individuels ; un qubit accordable nécessite un fil supplémentaire. La mise au point du câblage de milliers ou de millions de qubits sera l’un des défis techniques les plus difficiles à relever pour les deux entreprises ; IBM affirme que c’est l’une des raisons pour lesquelles elle a opté pour un qubit à fréquence fixe. M. Martinis, qui dirige l’équipe de Google, affirme qu’il a personnellement passé les trois dernières années à essayer de trouver des solutions de câblage. « C’est un problème tellement important que j’y ai travaillé », plaisante-t-il.
Mais compte tenu de leur taille et de leur richesse, Google et IBM ont toutes deux une chance de devenir des acteurs sérieux dans le domaine de l’informatique quantique. Les entreprises loueront leurs machines pour s’attaquer aux problèmes de la même manière qu’elles louent actuellement le stockage de données en nuage et la puissance de traitement d’Amazon, Google, IBM ou Microsoft. Et ce qui a commencé comme une bataille entre physiciens et informaticiens se transformera en un concours entre les divisions de services commerciaux et les départements de marketing.
Quelle entreprise est la mieux placée pour gagner ce concours ? IBM, avec ses revenus en baisse, a peut-être un plus grand sentiment d’urgence que Google. Elle sait d’expérience ce qu’il en coûte de tarder à entrer sur un marché : l’été dernier, dans son achat le plus coûteux, elle a déboursé 34 milliards de dollars pour Red Hat, un fournisseur de services cloud à code source ouvert, dans le but de rattraper Amazon et Microsoft dans ce domaine et de renverser sa fortune financière. Sa stratégie consistant à mettre ses machines quantiques sur le cloud et à construire une activité payante dès le départ semble conçue pour lui donner une longueur d’avance.
Google a récemment commencé à suivre l’exemple d’IBM, et ses clients commerciaux comprennent désormais le ministère américain de l’énergie, Volkswagen et Daimler. La raison pour laquelle elle ne l’a pas fait plus tôt, dit Martinis, est simple : « Nous n’avions pas les ressources nécessaires pour le mettre dans le nuage ». Mais c’est une autre façon de dire qu’elle avait le luxe de ne pas avoir à faire du développement commercial une priorité.
Si cette décision donne un avantage à IBM, il est trop tôt pour le dire, mais ce qui sera probablement plus important, c’est la façon dont les deux entreprises appliqueront leurs autres forces au problème dans les années à venir. IBM, dit Gil, bénéficiera de son expertise « full stack » dans tous les domaines, de la science des matériaux à la fabrication de puces en passant par le service aux grandes entreprises. Google, quant à lui, peut se targuer d’une culture de l’innovation digne de la Silicon Valley et d’une grande pratique de la mise à l’échelle rapide des opérations.
Pour ce qui est de la suprématie quantique elle-même, ce sera un moment important de l’histoire, mais cela ne signifie pas qu’il sera décisif. After all, everyone knows about the Wright brothers’ first flight, but can anybody remember what they did afterwards?
Sign inSubscribe now