Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
A perceptron különleges helyet foglal el a neurális hálózatok és a mesterséges intelligencia történetében, mert a teljesítményével kapcsolatos kezdeti hype Minsky és Papert cáfolatához és szélesebb körben elterjedt ellenérzéshez vezetett, amely évtizedekre beárnyékolta a neurális hálózatok kutatását, egy olyan neurális hálózati telet, amely csak Geoff Hinton kutatásával olvadt el teljesen a 2000-es években, amelynek eredményei azóta végigsöpörtek a gépi tanulás közösségén.
Frank Rosenblatt, a perceptron keresztapja inkább eszközként, mint algoritmusként népszerűsítette. A perceptron először hardverként került a világba.1 Rosenblatt, a Cornell Egyetemen tanult és később előadásokat tartott pszichológus, az amerikai haditengerészeti kutatási hivataltól kapott támogatást egy tanulni képes gép megépítésére. Az ő gépe, a Mark I perceptron így nézett ki.

A perceptron egy lineáris osztályozó, azaz olyan algoritmus, amely a bemenetet úgy osztályozza, hogy két kategóriát egyenes vonallal választ el. A bemenet jellemzően egy jellemzővektor x, amelyet megszorozunk súlyokkal w és hozzáadunk egy torzítást by = w * x + b.
A perceptron több valós értékű bemenet alapján egyetlen kimenetet állít elő úgy, hogy a bemeneti súlyok felhasználásával lineáris kombinációt képez (és néha a kimenetet nemlineáris aktiválási függvényen engedi át). Ezt így írhatjuk le matematikailag:
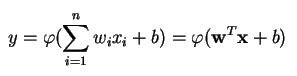
ahol w a súlyok vektorát, x a bemenetek vektorát, b az előfeszítést és phi a nemlineáris aktiváló függvényt jelöli.
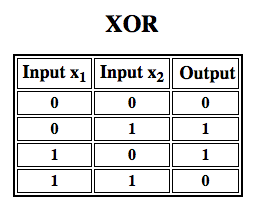
Rosenblatt egy egyrétegű perceptront épített. Vagyis az ő hardver-algoritmusa nem tartalmazott több réteget, amelyek lehetővé teszik a neurális hálózatok számára a jellemzőhierarchia modellezését. Ezért sekély neurális hálózat volt, ami megakadályozta, hogy perceptronja nemlineáris osztályozást végezzen, mint például az XOR-függvény (az XOR-operátor akkor vált ki, ha a bemenet vagy az egyik vagy a másik tulajdonságot mutatja, de nem mindkettőt; a “kizárólagos VAGY” rövidítése), ahogy azt Minsky és Papert könyvükben kimutatták.
A megerősítéses tanulás alkalmazása szimulációkra”
Multilayer Perceptrons (MLP)
A multilayer perceptronokkal végzett későbbi munkák kimutatták, hogy azok képesek az XOR-operátor, valamint számos más nemlineáris függvény közelítésére.
Mint ahogy Rosenblatt a perceptront az 1943-ban kitalált McCulloch-Pitts neuronra alapozta, úgy maguk a perceptronok is olyan építőelemek, amelyek csak olyan nagyobb funkciókban bizonyulnak hasznosnak, mint a többrétegű perceptronok.2)
A többrétegű perceptron a mélytanulás helló világa: jó kiindulópont a mélytanulás megismeréséhez.
A többrétegű perceptron (MLP) egy mély, mesterséges neurális hálózat. Egynél több perceptronból áll. Egy bemeneti rétegből áll, amely fogadja a jelet, egy kimeneti rétegből, amely döntést vagy előrejelzést hoz a bemenetről, és e kettő között tetszőleges számú rejtett rétegből, amelyek az MLP valódi számítási motorját alkotják. Az egy rejtett réteggel rendelkező MLP-k bármilyen folytonos függvényt képesek közelíteni.
A többrétegű perceptronokat gyakran alkalmazzák felügyelt tanulási problémákra3: bemenet-kimenet párokon tanulnak, és megtanulják modellezni a bemenetek és kimenetek közötti korrelációt (vagy függőséget). A képzés során a modell paramétereit, azaz a súlyokat és az előfeszítéseket kell beállítani a hiba minimalizálása érdekében. A backpropagationt arra használják, hogy ezeket a súly- és torzításbeállításokat a hibához képest elvégezzék, maga a hiba pedig többféleképpen is mérhető, többek között a hiba négyzetes középértékével (RMSE).
Az MLP-khez hasonló előretolt hálózatok olyanok, mint a tenisz vagy a pingpong. Főleg két mozgásban vesznek részt, egy állandó oda-vissza mozgásban. A találgatások és válaszok pingpongjára úgy is gondolhatunk, mint egyfajta felgyorsított tudományra, mivel minden egyes találgatás egy teszt, hogy mit gondolunk tudni, és minden egyes válasz visszajelzés, amely tudatja velünk, hogy mennyire tévedtünk.
Az előrehaladásban a jeláramlás a bemeneti rétegtől a rejtett rétegeken keresztül a kimeneti rétegig halad, és a kimeneti réteg döntését az alapigazság címkékhez mérjük.
A visszafelé haladásban a visszaterjedés és a számítási láncszabály segítségével a hibafüggvénynek a különböző súlyokkal és előfeszítésekkel kapcsolatos részleges deriváltjai visszaterjednek az MLP-n keresztül. Ez a differenciálás egy gradienst vagy hibatájképet ad, amely mentén a paraméterek módosíthatók, mivel az MLP-t egy lépéssel közelebb viszik a hibaminimumhoz. Ez bármilyen gradiens alapú optimalizációs algoritmussal, például sztochasztikus gradiens ereszkedéssel elvégezhető. A hálózat addig játssza ezt a teniszjátékot, amíg a hiba nem tud lejjebb menni. Ezt az állapotot nevezzük konvergenciának.
Lábjegyzetek
1) Az érdekes dolog, amire itt rá kell mutatni, hogy a szoftver és a hardver egy folyamatábrán létezik: a szoftver kifejezhető hardverként és fordítva. Amikor chipeket, például FPGA-kat programozunk, vagy ASIC-ket építünk, hogy egy bizonyos algoritmust szilíciumba süssünk, akkor egyszerűen egy szoftvert implementálunk egy szinttel lejjebb, hogy gyorsabban működjön. Hasonlóképpen, amit szilíciumba sütünk vagy fényekkel és potenciométerekkel összedrótozunk, mint például Rosenblatt Mark I-jét, azt szimbolikusan kódban is ki lehet fejezni. Ezért mondta Alan Kay, hogy “Aki igazán komolyan gondolja a szoftvert, annak saját hardvert kell készítenie”. De nincs ingyen ebéd, azaz amit az algoritmusok szilíciumba sütésével sebességben nyerünk, azt elveszítjük rugalmasságban, és fordítva. Ez a gépi tanulással kapcsolatban valódi probléma, mivel az algoritmusok az adatoknak való kitettség hatására megváltoztatják önmagukat. A kihívás az, hogy megtaláljuk az algoritmus azon részeit, amelyek a paraméterek változása esetén is stabilak maradnak; pl. a lineáris algebrai műveletek, amelyeket jelenleg a GPU-k dolgoznak fel a leggyorsabban.
2) A gondolatok az egyre összetettebb és egyben hasznosabb algoritmusok következő lépése felé hajlanak. Egy neuronról többre lépünk, amit rétegnek nevezünk; egy rétegről többre lépünk, amit többrétegű perceptronnak nevezünk. Lehet-e egy MLP-ről többre lépni, vagy egyszerűen csak tovább halmozzuk a rétegeket, ahogy a Microsoft tette az ImageNet győztesével, a ResNet-tel, amely több mint 150 réteget tartalmazott? Vagy az MLP-k megfelelő kombinációja egy sok algoritmusból álló együttes, amely egyfajta számítási demokráciában szavaz a legjobb előrejelzésről? Vagy az egyik algoritmus beágyazása egy másikba, mint a gráfkonvolúciós hálózatok esetében?
3) A Google-nél, amely valószínűleg a világ legfejlettebb mesterséges intelligenciával foglalkozó vállalata, széles körben használják őket a feladatok széles skálájára, annak ellenére, hogy léteznek összetettebb, korszerűbb módszerek is.
További olvasmányok
- A Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: An Introduction to Computational Geometry, Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Hebbian Theory
Other Pathmind Wiki Posts
- Deep Neural Networks
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning