Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
Il perceptron occupa un posto speciale nella storia delle reti neurali e dell’intelligenza artificiale, perché il clamore iniziale sulle sue prestazioni ha portato a una confutazione da parte di Minsky e Papert, e a un contraccolpo più ampio che ha gettato un’ombra sulla ricerca sulle reti neurali per decenni, un inverno delle reti neurali che è stato completamente scongelato solo con la ricerca di Geoff Hinton negli anni 2000, i cui risultati hanno poi spazzato la comunità dell’apprendimento automatico.
Frank Rosenblatt, padrino del perceptron, lo ha reso popolare come un dispositivo piuttosto che un algoritmo. Il perceptron è entrato per la prima volta nel mondo come hardware.1 Rosenblatt, uno psicologo che ha studiato e poi insegnato alla Cornell University, ha ricevuto un finanziamento dall’U.S. Office of Naval Research per costruire una macchina che potesse imparare. La sua macchina, il Mark I perceptron, aveva questo aspetto.

Un perceptron è un classificatore lineare; cioè, è un algoritmo che classifica l’input separando due categorie con una linea retta. L’input è tipicamente un vettore di caratteristiche x moltiplicato per i pesi w e aggiunto ad un bias by = w * x + b.
Un perceptron produce un singolo output basato su diversi input a valore reale formando una combinazione lineare usando i suoi pesi di input (e talvolta passando l’output attraverso una funzione di attivazione non lineare). Ecco come si può scrivere in matematica:
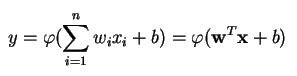
dove w denota il vettore dei pesi, x è il vettore degli ingressi, b è il bias e phi è la funzione di attivazione non lineare.
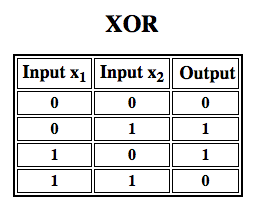
Rosenblatt ha costruito un perceptron a singolo strato. Cioè, il suo algoritmo hardware non includeva strati multipli, che permettono alle reti neurali di modellare una gerarchia di caratteristiche. Era, quindi, una rete neurale poco profonda, che impediva al suo perceptron di eseguire una classificazione non lineare, come la funzione XOR (un operatore XOR scatta quando l’input mostra o un tratto o un altro, ma non entrambi; sta per “OR esclusivo”), come Minsky e Papert hanno mostrato nel loro libro.
Applica l’apprendimento per rinforzo alle simulazioni”
Percettroni multistrato (MLP)
I lavori successivi con i percettori multistrato hanno dimostrato che sono in grado di approssimare un operatore XOR così come molte altre funzioni non lineari.
Come Rosenblatt ha basato il perceptron su un neurone McCulloch-Pitts, concepito nel 1943, così anche i perceptron stessi sono blocchi di costruzione che si dimostrano utili solo in funzioni più grandi come i perceptron multistrato2.)
Il perceptron multistrato è il mondo dell’apprendimento profondo: un buon punto di partenza quando si sta imparando l’apprendimento profondo.
Un perceptron multistrato (MLP) è una rete neurale artificiale profonda. È composta da più di un perceptron. Sono composti da uno strato di input per ricevere il segnale, uno strato di output che prende una decisione o una previsione sull’input, e tra questi due, un numero arbitrario di strati nascosti che sono il vero motore computazionale dell’MLP. Le MLP con uno strato nascosto sono in grado di approssimare qualsiasi funzione continua.
I percettori multistrato sono spesso applicati a problemi di apprendimento supervisionato3: si allenano su un insieme di coppie input-output e imparano a modellare la correlazione (o dipendenza) tra questi input e output. L’addestramento comporta la regolazione dei parametri, o dei pesi e dei bias, del modello al fine di minimizzare l’errore. La backpropagation è usata per fare quelle regolazioni di pesi e bias relative all’errore, e l’errore stesso può essere misurato in una varietà di modi, incluso l’errore quadratico medio (RMSE).
Le reti feedforward come le MLP sono come il tennis, o il ping pong. Sono principalmente coinvolte in due movimenti, un costante avanti e indietro. Si può pensare a questo ping pong di ipotesi e risposte come a una sorta di scienza accelerata, poiché ogni ipotesi è un test di ciò che pensiamo di sapere, e ogni risposta è un feedback che ci fa sapere quanto ci stiamo sbagliando.
Nel passaggio in avanti, il flusso del segnale si muove dallo strato di ingresso attraverso gli strati nascosti fino allo strato di uscita, e la decisione dello strato di uscita è misurata rispetto alle etichette della verità di base.
Nel passaggio all’indietro, usando la backpropagation e la regola della catena del calcolo, le derivate parziali della funzione di errore rispetto ai vari pesi e bias sono retropropagate attraverso la MLP. Questo atto di differenziazione ci dà un gradiente, o un paesaggio di errore, lungo il quale i parametri possono essere regolati mentre spostano la MLP un passo più vicino al minimo dell’errore. Questo può essere fatto con qualsiasi algoritmo di ottimizzazione basato sul gradiente, come la discesa del gradiente stocastico. La rete continua a giocare questa partita a tennis fino a quando l’errore non può scendere più in basso. Questo stato è noto come convergenza.
Note
1) La cosa interessante da sottolineare qui è che software e hardware esistono su un diagramma di flusso: il software può essere espresso come hardware e viceversa. Quando i chip come gli FPGA sono programmati, o gli ASIC sono costruiti per cuocere un certo algoritmo nel silicio, stiamo semplicemente implementando il software un livello più in basso per farlo funzionare più velocemente. Allo stesso modo, ciò che è cotto nel silicio o cablato insieme con luci e potenziometri, come il Mark I di Rosenblatt, può anche essere espresso simbolicamente in codice. Questo è il motivo per cui Alan Kay ha detto: “Le persone che sono davvero serie riguardo al software dovrebbero costruirsi il proprio hardware”. Ma non c’è un pranzo gratis; cioè quello che si guadagna in velocità cuocendo algoritmi nel silicio, si perde in flessibilità, e viceversa. Questo è un problema reale per quanto riguarda l’apprendimento automatico, poiché gli algoritmi si modificano attraverso l’esposizione ai dati. La sfida è trovare quelle parti dell’algoritmo che rimangono stabili anche se i parametri cambiano; per esempio le operazioni di algebra lineare che sono attualmente elaborate più rapidamente dalle GPU.
2) I tuoi pensieri possono inclinare verso il prossimo passo verso algoritmi sempre più complessi e anche più utili. Passiamo da un neurone a più neuroni, chiamato strato; passiamo da uno strato a più strati, chiamato perceptron multistrato. Possiamo passare da un MLP a diversi, o dobbiamo semplicemente continuare ad accumulare strati, come ha fatto Microsoft con il suo vincitore di ImageNet, ResNet, che aveva più di 150 strati? O la giusta combinazione di MLP è un insieme di molti algoritmi che votano in una sorta di democrazia computazionale sulla migliore previsione? O è l’incorporazione di un algoritmo all’interno di un altro, come facciamo con le reti convoluzionali a grafo?
3) Sono ampiamente utilizzati a Google, che è probabilmente l’azienda di IA più sofisticata del mondo, per una vasta gamma di compiti, nonostante l’esistenza di metodi più complessi e all’avanguardia.
Altra lettura
- Il Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, di Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: An Introduction to Computational Geometry, di Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Teoria Hebbiana
Altri post Wiki Pathmind
- Reti Neurali Profonde
- Reti Neurali Ricorrenti Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning