Fine ottobre scorso, Google ha annunciato che uno di questi chip, chiamato Sycamore, era diventato il primo a dimostrare la “supremazia quantistica” eseguendo un compito che sarebbe stato praticamente impossibile su una macchina classica. Con soli 53 qubit, Sycamore ha completato in pochi minuti un calcolo che, secondo Google, avrebbe richiesto al più potente supercomputer esistente al mondo, Summit, 10.000 anni. Google ha propagandato questo come un importante passo avanti, paragonandolo al lancio dello Sputnik o al primo volo dei fratelli Wright – la soglia di una nuova era di macchine che avrebbe fatto sembrare il computer più potente di oggi un abaco.
A una conferenza stampa nel laboratorio di Santa Barbara, il team di Google ha allegramente risposto alle domande dei giornalisti per quasi tre ore. Ma il loro buon umore non poteva mascherare una tensione di fondo. Due giorni prima, i ricercatori di IBM, il principale rivale di Google nel calcolo quantistico, avevano silurato la sua grande rivelazione. Avevano pubblicato un documento che essenzialmente accusava i Googler di aver sbagliato i loro calcoli. IBM ha calcolato che ci sarebbero voluti solo giorni, non millenni, per replicare ciò che Sycamore aveva fatto. Quando gli è stato chiesto cosa pensasse del risultato di IBM, Hartmut Neven, il capo del team di Google, ha evitato di dare una risposta diretta.

Si potrebbe liquidare tutto questo come un semplice battibecco accademico – e in un certo senso lo era. Anche se IBM aveva ragione, Sycamore aveva comunque fatto il calcolo mille volte più velocemente di quanto avrebbe fatto Summit. E probabilmente ci sarebbero voluti solo mesi prima che Google costruisse una macchina quantistica leggermente più grande che dimostrasse il punto oltre ogni dubbio.
L’obiezione più profonda di IBM, però, non era che l’esperimento di Google avesse meno successo di quanto sostenuto, ma che fosse un test senza senso in primo luogo. A differenza della maggior parte del mondo dell’informatica quantistica, IBM non pensa che la “supremazia quantistica” sia il momento dei fratelli Wright della tecnologia; infatti, non crede nemmeno che ci sarà un tale momento.
IBM sta invece inseguendo una misura di successo molto diversa, qualcosa che chiama “vantaggio quantistico”. Non si tratta di una semplice differenza di parole e nemmeno di scienza, ma di una posizione filosofica che ha radici nella storia, nella cultura e nelle ambizioni di IBM e, forse, nel fatto che per otto anni le sue entrate e i suoi profitti sono stati in declino quasi incessante, mentre Google e la sua società madre Alphabet hanno visto solo crescere i loro numeri. Questo contesto, e questi obiettivi diversi, potrebbero influenzare chi – se uno dei due – esce vincitore nella corsa al calcolo quantistico.
Mondi a parte
L’elegante, ampia curva del Thomas J. Watson Research Center di IBM nei sobborghi a nord di New York City, un capolavoro neo-futurista dell’architetto finlandese Eero Saarinen, è un continente e un universo lontano dagli scavi senza nome del team di Google. Completato nel 1961 con la fortuna che IBM ha ricavato dai mainframe, ha una qualità da museo, che ricorda a tutti quelli che ci lavorano le scoperte dell’azienda in tutto, dalla geometria frattale ai superconduttori all’intelligenza artificiale e al calcolo quantistico.
Il capo della divisione di ricerca di 4.000 persone è Dario Gil, uno spagnolo il cui rapido discorso corre per tenere il passo con il suo zelo quasi evangelico. Entrambe le volte che ho parlato con lui, ha snocciolato pietre miliari storiche per sottolineare da quanto tempo IBM è coinvolta nella ricerca legata al quantum-computing (vedi la linea del tempo a destra).


Un grande esperimento: Teoria e pratica quantistica
Il blocco di base di un computer quantistico è il bit quantistico, o qubit. In un computer classico, un bit può memorizzare o uno 0 o un 1. Un qubit può memorizzare non solo 0 o 1 ma anche uno stato intermedio chiamato superposizione, che può assumere molti valori diversi. Un’analogia è che se l’informazione fosse un colore, allora un bit classico potrebbe essere bianco o nero. Un qubit quando è in sovrapposizione potrebbe essere qualsiasi colore dello spettro, e potrebbe anche variare in luminosità.
Il risultato è che un qubit può memorizzare ed elaborare una grande quantità di informazioni rispetto a un bit – e la capacità aumenta esponenzialmente quando si collegano i qubit insieme. Memorizzare tutte le informazioni nei 53 qubit del chip Sycamore di Google richiederebbe circa 72 petabyte (72 miliardi di gigabyte) di memoria classica del computer. Non ci vogliono molti altri qubit prima di aver bisogno di un computer classico grande come il pianeta.
Ma non è semplice. Delicati e facilmente disturbabili, i qubit devono essere quasi perfettamente isolati dal calore, dalle vibrazioni e dagli atomi vaganti – da qui i frigoriferi “chandelier” nel laboratorio quantistico di Google. Anche allora, possono funzionare al massimo per qualche centinaio di microsecondi prima di “decohere” e perdere la loro sovrapposizione.
E i computer quantistici non sono sempre più veloci di quelli classici. Sono solo diversi, più veloci in alcune cose e più lenti in altre, e richiedono diversi tipi di software. Per confrontare le loro prestazioni, bisogna scrivere un programma classico che simuli approssimativamente quello quantistico.
Per il suo esperimento, Google ha scelto un test di benchmarking chiamato “random quantum circuit sampling”. Genera milioni di numeri casuali, ma con leggere distorsioni statistiche che sono una caratteristica dell’algoritmo quantistico. Se Sycamore fosse una calcolatrice tascabile, sarebbe l’equivalente di premere pulsanti a caso e controllare che il display mostri i risultati attesi.
Google ha simulato parti di questo test sulle sue massicce server farm e su Summit, il più grande supercomputer del mondo, all’Oak Ridge National Laboratory. I ricercatori hanno stimato che il completamento dell’intero lavoro, che ha richiesto a Sycamore 200 secondi, avrebbe richiesto a Summit circa 10.000 anni. Voilà: supremazia quantistica.
Quindi qual è stata l’obiezione di IBM? Fondamentalmente, che ci sono diversi modi per far sì che un computer classico simuli una macchina quantistica – e che il software che si scrive, il modo in cui si sminuzzano i dati e li si memorizza, e l’hardware che si usa fanno tutti una grande differenza su quanto velocemente la simulazione può essere eseguita. IBM ha detto che Google ha ipotizzato che la simulazione avrebbe dovuto essere tagliata in molti pezzi, ma Summit, con 280 petabyte di memoria, è abbastanza grande da contenere lo stato completo di Sycamore in una sola volta. (E IBM ha costruito Summit, quindi dovrebbe saperlo.)
Ma nel corso dei decenni, l’azienda ha guadagnato la reputazione di lottare per trasformare i suoi progetti di ricerca in successi commerciali. Prendete, più recentemente, Watson, l’IA che gioca a Jeopardy e che IBM ha cercato di convertire in un robot guru medico. Era destinato a fornire diagnosi e identificare le tendenze in oceani di dati medici, ma nonostante decine di partnership con i fornitori di servizi sanitari, ci sono state poche applicazioni commerciali, e anche quelle che sono emerse hanno dato risultati contrastanti.
Il team di calcolo quantistico, secondo Gil, sta cercando di rompere questo ciclo facendo la ricerca e lo sviluppo del business in parallelo. Quasi non appena ha avuto computer quantistici funzionanti, ha iniziato a renderli accessibili agli esterni mettendoli sul cloud, dove possono essere programmati per mezzo di una semplice interfaccia drag-and-drop che funziona in un browser web. La “IBM Q Experience”, lanciata nel 2016, consiste ora in 15 computer quantistici pubblicamente disponibili che vanno da cinque a 53 qubit di dimensione. Circa 12.000 persone al mese li usano, dai ricercatori accademici ai ragazzi delle scuole. Il tempo sulle macchine più piccole è gratuito; IBM dice che ha già più di 100 clienti che pagano (non dice quanto) per utilizzare quelle più grandi.
Nessuno di questi dispositivi – o qualsiasi altro computer quantistico nel mondo, ad eccezione di Sycamore di Google – ha ancora dimostrato di poter battere una macchina classica in qualcosa. Per IBM, questo non è il punto ora. Rendere le macchine disponibili online permette all’azienda di imparare ciò che i futuri clienti potrebbero avere bisogno da loro e permette agli sviluppatori di software esterni di imparare a scrivere codice per loro. Questo, a sua volta, contribuisce al loro sviluppo, rendendo i successivi computer quantistici migliori.
Questo ciclo, l’azienda crede, è il percorso più veloce verso il suo cosiddetto vantaggio quantistico, un futuro in cui i computer quantistici non lasceranno necessariamente quelli classici nella polvere, ma faranno alcune cose utili un po’ più velocemente o in modo più efficiente – abbastanza da renderli economicamente vantaggiosi. Mentre la supremazia quantistica è una singola pietra miliare, il vantaggio quantistico è un “continuum”, dicono gli IBMers – un mondo di possibilità che si espande gradualmente.
Questa, quindi, è la grande teoria unificata di IBM di Gil: che combinando la sua eredità, la sua esperienza tecnica, la potenza intellettuale di altre persone e la sua dedizione ai clienti commerciali, può costruire computer quantistici utili prima e meglio di chiunque altro.
In questa visione delle cose, IBM vede la dimostrazione della supremazia quantistica di Google come “un trucco da salotto”, dice Scott Aaronson, un fisico dell’Università del Texas a Austin, che ha contribuito agli algoritmi quantistici che Google sta usando. Nel migliore dei casi è una distrazione appariscente dal vero lavoro che deve essere fatto. Nel peggiore dei casi è fuorviante, perché potrebbe far pensare che i computer quantistici possono battere quelli classici in qualsiasi cosa piuttosto che in un compito molto stretto. “‘Supremazia’ è una parola inglese che sarà impossibile per il pubblico non fraintendere”, dice Gil.
Google, naturalmente, la vede piuttosto diversamente.
Entrare nell’upstart
Google era una precoce azienda di otto anni quando ha iniziato ad armeggiare con i problemi quantistici nel 2006, ma non ha formato un laboratorio quantistico dedicato fino al 2012 – lo stesso anno in cui John Preskill, un fisico del Caltech, ha coniato il termine “supremazia quantistica”.”
Il capo del laboratorio è Hartmut Neven, un informatico tedesco con una presenza imponente e un’inclinazione per lo stile chic del Burning Man; l’ho visto una volta in un cappotto blu peloso e un’altra volta in un completo argentato che lo faceva sembrare un astronauta grunge. (“Mia moglie compra queste cose per me”, ha spiegato.) Inizialmente, Neven ha comprato una macchina costruita da una ditta esterna, D-Wave, e ha trascorso un po’ di tempo cercando di raggiungere la supremazia quantistica su di essa, ma senza successo. Dice di aver convinto Larry Page, l’allora amministratore delegato di Google, a investire nella costruzione di computer quantistici nel 2014, promettendogli che Google avrebbe raccolto la sfida di Preskill: “Gli abbiamo detto: ‘Ascolta, Larry, in tre anni torneremo e metteremo sul tuo tavolo un prototipo di chip che può almeno calcolare un problema che è al di là delle capacità delle macchine classiche'”
Non avendo la competenza quantistica di IBM, Google ha assunto un team esterno, guidato da John Martinis, un fisico dell’Università della California, Santa Barbara. Martinis e il suo gruppo erano già tra i migliori costruttori di computer quantistici al mondo – erano riusciti a mettere insieme fino a nove qubit – e la promessa di Neven a Page sembrava un obiettivo degno di essere raggiunto.
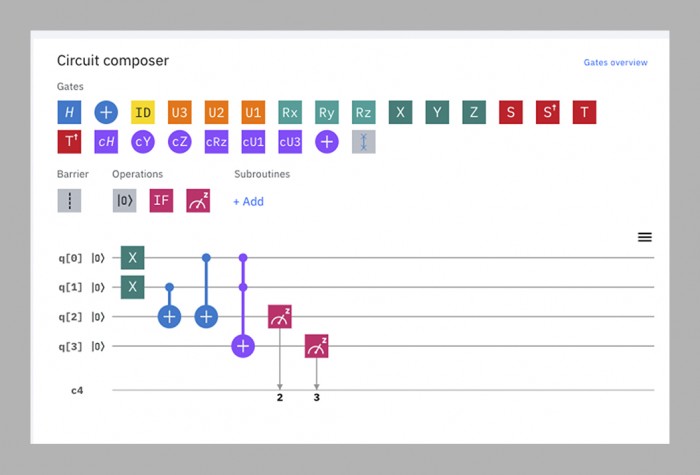
Il termine di tre anni arrivò e passò mentre il team di Martinis lottava per realizzare un chip sufficientemente grande e stabile per questa sfida. Nel 2018 Google ha rilasciato il suo più grande processore, Bristlecone. Con 72 qubit, era molto più avanti di qualsiasi cosa i suoi rivali avevano fatto, e Martinis ha previsto che avrebbe raggiunto la supremazia quantistica quello stesso anno. Ma alcuni membri del team avevano lavorato in parallelo su una diversa architettura di chip, chiamata Sycamore, che alla fine si è dimostrata in grado di fare di più con meno qubit. Quindi è stato un chip da 53 qubit – originariamente 54, ma uno di essi ha funzionato male – che alla fine ha dimostrato la supremazia lo scorso autunno.
Per scopi pratici, il programma usato in quella dimostrazione è praticamente inutile – genera numeri casuali, che non è qualcosa per cui si ha bisogno di un computer quantistico. Ma li genera in un modo particolare che un computer classico troverebbe molto difficile da replicare, stabilendo così la prova del concetto (vedi pagina accanto). “Non mi piace la parola, e non mi piacciono le implicazioni”, dice Jay Gambetta, un cauto australiano a capo del team quantistico di IBM. Il problema, dice, è che è praticamente impossibile prevedere se un dato calcolo quantistico sarà difficile per una macchina classica, quindi mostrarlo in un caso non aiuta a trovare altri casi.
A tutti quelli con cui ho parlato fuori da IBM, questo rifiuto di trattare la supremazia quantistica come significativa rasenta la cocciutaggine. “Chiunque avrà mai un’offerta commercialmente rilevante – deve prima mostrare la supremazia. Penso che sia solo una logica di base”, dice Neven. Anche Will Oliver, un mite fisico del MIT che è stato uno degli osservatori più imparziali della spada, dice: “È una pietra miliare molto importante mostrare che un computer quantistico supera un computer classico in qualche compito, qualunque esso sia.”
Il salto quantico
A prescindere se si è d’accordo con la posizione di Google o di IBM, il prossimo obiettivo è chiaro, dice Oliver: costruire un computer quantistico che possa fare qualcosa di utile. La speranza è che tali macchine possano un giorno risolvere problemi che richiedono quantità irrealizzabili di potenza di calcolo brute-force ora, come la modellazione di molecole complesse per aiutare a scoprire nuovi farmaci e materiali, o l’ottimizzazione dei flussi di traffico cittadino in tempo reale per ridurre la congestione, o fare previsioni del tempo a lungo termine. (Alla fine potrebbero essere in grado di decifrare i codici crittografici utilizzati oggi per proteggere le comunicazioni e le transazioni finanziarie, anche se per allora la maggior parte del mondo avrà probabilmente adottato una crittografia resistente ai quanti). Il problema è che è quasi impossibile prevedere quale sarà il primo compito utile, o quanto grande sarà il computer necessario per eseguirlo.
Questa incertezza ha a che fare sia con l’hardware che con il software. Per quanto riguarda l’hardware, Google ritiene che i suoi attuali progetti di chip possano arrivare a qualcosa tra i 100 e i 1.000 qubit. Tuttavia, proprio come la performance di un’auto non dipende solo dalla dimensione del motore, la performance di un computer quantistico non è semplicemente determinata dal suo numero di qubit. C’è una serie di altri fattori da prendere in considerazione, tra cui quanto a lungo possono essere trattenuti dalla decoerenza, quanto sono soggetti a errori, quanto velocemente operano e come sono interconnessi. Questo significa che qualsiasi computer quantistico che opera oggi raggiunge solo una frazione del suo pieno potenziale.
Il software per i computer quantistici, nel frattempo, è nella sua infanzia tanto quanto le macchine stesse. Nell’informatica classica, i linguaggi di programmazione sono ora diversi livelli rimossi dal “codice macchina” grezzo che i primi sviluppatori di software dovevano usare, perché il nitty-gritty di come i dati vengono memorizzati, elaborati e spostati è già standardizzato. “Su un computer classico, quando lo programmi, non devi sapere come funziona un transistor”, dice Dave Bacon, che guida lo sforzo software del team di Google. Il codice quantistico, d’altra parte, deve essere altamente adattato ai qubit su cui verrà eseguito, in modo da trarre il massimo dalle loro prestazioni temperamentali. Questo significa che il codice per i chip di IBM non funzionerà su quelli di altre aziende, e anche le tecniche per ottimizzare il Sycamore a 53 qubit di Google non andranno necessariamente bene sul suo futuro fratello a 100 qubit. Ancora più importante, significa che nessuno può prevedere quanto sarà difficile un problema che quei 100 qubit saranno in grado di affrontare.
Il massimo che qualcuno osa sperare è che i computer con qualche centinaio di qubit saranno persuasi a simulare qualche chimica moderatamente complessa nei prossimi anni, forse anche abbastanza per far avanzare la ricerca di un nuovo farmaco o di una batteria più efficiente. Eppure la decoerenza e gli errori porteranno tutte queste macchine a fermarsi prima che possano fare qualcosa di veramente difficile come rompere la crittografia.
Per costruire un computer quantistico con la potenza di 1.000 qubit, avresti bisogno di un milione di qubit reali.
Questo richiederà un computer quantistico “fault-tolerant”, che possa compensare gli errori e continuare a funzionare indefinitamente, proprio come fanno quelli classici. La soluzione prevista sarà quella di creare ridondanza: far agire centinaia di qubit come uno solo, in uno stato quantico condiviso. Collettivamente, possono correggere gli errori dei singoli qubit. E come ogni qubit soccombe alla decoerenza, i suoi vicini lo riporteranno in vita, in un ciclo infinito di rianimazione reciproca.
La previsione tipica è che ci vorrebbero fino a 1.000 qubit congiunti per raggiungere quella stabilità – il che significa che per costruire un computer con la potenza di 1.000 qubit, ce ne vorrebbero un milione. Google stima “prudentemente” di poter costruire un processore da un milione di qubit entro 10 anni, dice Neven, anche se ci sono alcuni grandi ostacoli tecnici da superare, tra cui uno in cui IBM potrebbe ancora avere il vantaggio su Google (vedi pagina a fianco).
Per allora, molte cose potrebbero essere cambiate. I qubit superconduttori che Google e IBM usano attualmente potrebbero rivelarsi i tubi a vuoto della loro era, sostituiti da qualcosa di molto più stabile e affidabile. I ricercatori di tutto il mondo stanno sperimentando vari metodi per realizzare i qubit, anche se pochi sono abbastanza avanzati per costruire computer funzionanti. Startup rivali come Rigetti, IonQ o Quantum Circuits potrebbero sviluppare un vantaggio in una particolare tecnica e sorpassare le aziende più grandi.
Un racconto di due transmons
I qubit transmon di Google e IBM sono quasi identici, con una piccola ma potenzialmente cruciale differenza.
In entrambi i computer quantistici di Google e IBM, i qubit stessi sono controllati da impulsi a microonde. Piccoli difetti di fabbricazione fanno sì che non ci siano due qubit che rispondano a impulsi della stessa frequenza. Ci sono due soluzioni a questo problema: variare la frequenza degli impulsi per trovare il punto dolce di ogni qubit, come scuotere una chiave mal tagliata in una serratura finché non si apre; o usare campi magnetici per “sintonizzare” ogni qubit alla giusta frequenza.
IBM usa il primo metodo; Google usa il secondo. Ogni approccio ha vantaggi e svantaggi. I qubit sintonizzabili di Google funzionano più velocemente e più precisamente, ma sono meno stabili e richiedono più circuiti. I qubit a frequenza fissa di IBM sono più stabili e più semplici, ma funzionano più lentamente.
Da un punto di vista tecnico, è praticamente un testa a testa, almeno in questa fase. In termini di filosofia aziendale, però, è la differenza tra Google e IBM in poche parole – o meglio, in un qubit.
Google ha scelto di essere agile. “In generale la nostra filosofia va un po’ più verso una maggiore controllabilità a spese dei numeri che la gente tipicamente cerca”, dice Hartmut Neven.
IBM, d’altra parte, ha scelto l’affidabilità. “C’è un’enorme differenza tra fare un esperimento di laboratorio e pubblicare un articolo, e mettere su un sistema con, tipo, il 98% di affidabilità dove puoi farlo funzionare tutto il tempo”, dice Dario Gil.
In questo momento, Google è in vantaggio. Quando le macchine diventano più grandi, però, il vantaggio potrebbe passare a IBM. Ogni qubit è controllato dai suoi singoli fili; un qubit accordabile richiede un filo in più. Capire il cablaggio per migliaia o milioni di qubit sarà una delle sfide tecniche più difficili che le due aziende dovranno affrontare; IBM dice che è una delle ragioni per cui hanno scelto il qubit a frequenza fissa. Martinis, il capo del team di Google, dice di aver passato personalmente gli ultimi tre anni a cercare di trovare soluzioni di cablaggio. “È un problema così importante che ci ho lavorato”, scherza.
Ma date le loro dimensioni e la loro ricchezza, sia Google che IBM hanno la possibilità di diventare giocatori seri nel business del quantum computing. Le aziende affitteranno le loro macchine per affrontare i problemi nel modo in cui attualmente affittano l’archiviazione dei dati e la potenza di elaborazione basata su cloud da Amazon, Google, IBM o Microsoft. E quella che è iniziata come una battaglia tra fisici e informatici si evolverà in una gara tra le divisioni dei servizi aziendali e i dipartimenti di marketing.
Quale azienda è nella posizione migliore per vincere questa gara? IBM, con le sue entrate in calo, potrebbe avere un senso di urgenza maggiore di Google. Conosce per amara esperienza i costi della lentezza nell’entrare in un mercato: l’estate scorsa, nel suo acquisto più costoso di sempre, ha sborsato 34 miliardi di dollari per Red Hat, un fornitore di servizi cloud open-source, nel tentativo di raggiungere Amazon e Microsoft in quel campo e invertire le sue sorti finanziarie. La sua strategia di mettere le sue macchine quantistiche sulla nuvola e costruire un business pagante fin dall’inizio sembra progettata per darle un vantaggio.
Google ha recentemente iniziato a seguire l’esempio di IBM, e i suoi clienti commerciali ora includono il Dipartimento dell’Energia degli Stati Uniti, Volkswagen e Daimler. La ragione per cui non l’ha fatto prima, dice Martinis, è semplice: “Non avevamo le risorse per metterlo sul cloud”. Ma questo è un altro modo per dire che ha avuto il lusso di non dover fare dello sviluppo del business una priorità.
Se questa decisione dà a IBM un vantaggio è troppo presto per dirlo, ma probabilmente più importante sarà il modo in cui le due società applicano le loro altre forze al problema nei prossimi anni. IBM, dice Gil, beneficerà della sua esperienza “full stack” in tutto, dalla scienza dei materiali e la fabbricazione di chip per servire i grandi clienti aziendali. Google, d’altra parte, può vantare una cultura dell’innovazione in stile Silicon Valley e un sacco di pratica per scalare rapidamente le operazioni.
Per quanto riguarda la supremazia quantistica, sarà un momento importante nella storia, ma questo non significa che sarà decisivo. After all, everyone knows about the Wright brothers’ first flight, but can anybody remember what they did afterwards?
Sign inSubscribe now