Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
Perceptronul ocupă un loc special în istoria rețelelor neuronale și a inteligenței artificiale, pentru că entuziasmul inițial cu privire la performanțele sale a dus la o dezmințire din partea lui Minsky și Papert și la o reacție de amploare mai mare care a aruncat o umbră asupra cercetării în domeniul rețelelor neuronale timp de zeci de ani, o iarnă a rețelelor neuronale care s-a dezghețat în totalitate doar cu cercetările lui Geoff Hinton din anii 2000, ale căror rezultate au măturat de atunci comunitatea de învățare a mașinilor.
Frank Rosenblatt, nașul perceptronului, l-a popularizat ca fiind mai degrabă un dispozitiv decât un algoritm. Perceptronul a intrat pentru prima dată în lume sub formă de hardware.1 Rosenblatt, un psiholog care a studiat și mai târziu a predat la Universitatea Cornell, a primit finanțare de la Biroul de Cercetare Navală al SUA pentru a construi o mașină care să poată învăța. Mașina sa, perceptronul Mark I, arăta astfel.

Un perceptron este un clasificator liniar; adică este un algoritm care clasifică intrările prin separarea a două categorii cu o linie dreaptă. Intrarea este, de obicei, un vector de caracteristici x înmulțit cu ponderile w și adăugat la un bias by = w * x + b.
Un perceptron produce o singură ieșire pe baza mai multor intrări cu valori reale prin formarea unei combinații liniare folosind ponderile sale de intrare (și, uneori, trecând ieșirea printr-o funcție de activare neliniară). Iată cum puteți scrie asta în matematică:
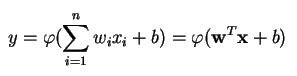
unde w reprezintă vectorul de ponderi, x este vectorul de intrări, b este polarizarea și phi este funcția de activare neliniară.
Rosenblatt a construit un perceptron cu un singur strat. Adică algoritmul său hardware nu a inclus straturi multiple, care permit rețelelor neuronale să modeleze o ierarhie de caracteristici. A fost, prin urmare, o rețea neuronală superficială, ceea ce a împiedicat perceptronul său să realizeze o clasificare neliniară, cum ar fi funcția XOR (un operator XOR se declanșează atunci când intrarea prezintă fie o trăsătură, fie alta, dar nu ambele; înseamnă „OR exclusiv”), așa cum au arătat Minsky și Papert în cartea lor.
Aplicați învățarea prin întărire la simulări”
Perceptroni multistrat (MLP)
Lucrările ulterioare cu perceptroni multistrat au arătat că aceștia sunt capabili să aproximeze un operator XOR, precum și multe alte funcții neliniare.
La fel cum Rosenblatt a bazat perceptronul pe un neuron McCulloch-Pitts, conceput în 1943, la fel și perceptronii în sine sunt blocuri de construcție care se dovedesc a fi utile doar în funcții mai mari precum perceptronii multistrat.2)
Perceptronul multistrat este lumea bună a învățării profunde: un loc bun pentru a începe atunci când învățați despre învățarea profundă.
Un perceptron multistrat (MLP) este o rețea neuronală artificială profundă. Este compusă din mai mult de un perceptron. Acestea sunt compuse dintr-un strat de intrare pentru a primi semnalul, un strat de ieșire care ia o decizie sau face o predicție cu privire la intrare și, între aceste două, un număr arbitrar de straturi ascunse care reprezintă adevăratul motor de calcul al MLP. MLP-urile cu un singur strat ascuns sunt capabile să aproximeze orice funcție continuă.
Perceptronii multistrat sunt adesea aplicați la probleme de învățare supravegheată3: aceștia se antrenează pe un set de perechi intrare-ieșire și învață să modeleze corelația (sau dependențele) dintre aceste intrări și ieșiri. Instruirea implică ajustarea parametrilor, sau a ponderilor și a polarizărilor modelului, pentru a minimiza eroarea. Backpropagation este utilizat pentru a face aceste ajustări ale ponderilor și bias-urilor în raport cu eroarea, iar eroarea însăși poate fi măsurată într-o varietate de moduri, inclusiv prin eroarea medie pătratică (RMSE).
Rețelele de tip feedforward, cum ar fi MLP, sunt ca tenisul sau ping pong. Ele sunt implicate în principal în două mișcări, o mișcare constantă înainte și înapoi. Vă puteți gândi la acest ping-pong de presupuneri și răspunsuri ca la un fel de știință accelerată, deoarece fiecare presupunere este un test a ceea ce credem că știm, iar fiecare răspuns este un feedback care ne anunță cât de mult ne înșelăm.
În pasul înainte, fluxul de semnal se deplasează de la stratul de intrare prin straturile ascunse până la stratul de ieșire, iar decizia stratului de ieșire este măsurată în raport cu etichetele de adevăr de bază.
În pasul înapoi, cu ajutorul propagării înapoi și a regulii de calcul în lanț, derivatele parțiale ale funcției de eroare în raport cu diferitele ponderi și polarizări sunt propagate înapoi prin MLP. Acest act de diferențiere ne oferă un gradient, sau un peisaj al erorii, de-a lungul căruia pot fi ajustați parametrii pe măsură ce aceștia apropie MLP-ul cu un pas de minimul erorii. Acest lucru poate fi realizat cu orice algoritm de optimizare bazat pe gradient, cum ar fi coborârea stocastică a gradientului. Rețeaua continuă să joace acest joc de tenis până când eroarea nu poate fi mai mică. Această stare este cunoscută sub numele de convergență.
Note de subsol
1) Lucrul interesant de subliniat aici este că software-ul și hardware-ul există pe o organigramă: software-ul poate fi exprimat ca hardware și viceversa. Atunci când cipuri precum FPGA-urile sunt programate sau ASIC-urile sunt construite pentru a coace un anumit algoritm în siliciu, nu facem decât să implementăm software-ul cu un nivel mai jos pentru a-l face să funcționeze mai rapid. De asemenea, ceea ce este copt în siliciu sau cablat împreună cu lumini și potențiometre, cum ar fi Mark I al lui Rosenblatt, poate fi, de asemenea, exprimat simbolic în cod. Acesta este motivul pentru care Alan Kay a spus: „Oamenii care sunt cu adevărat serioși în materie de software ar trebui să își facă propriul hardware”. Dar nu există un prânz gratuit; adică ceea ce câștigi în viteză prin coacerea algoritmilor în siliciu, pierzi în flexibilitate și viceversa. Aceasta se întâmplă să fie o problemă reală în ceea ce privește învățarea automată, deoarece algoritmii se modifică singuri prin expunerea la date. Provocarea constă în găsirea acelor părți ale algoritmului care rămân stabile chiar și atunci când se schimbă parametrii; de exemplu, operațiile de algebră liniară care, în prezent, sunt procesate cel mai rapid de către GPU.
2) Gândurile dumneavoastră pot înclina spre următorul pas în algoritmi din ce în ce mai complecși și, de asemenea, mai utili. Trecem de la un neuron la mai mulți, numit strat; trecem de la un strat la mai mulți, numit perceptron multistrat. Putem trece de la un MLP la mai multe, sau pur și simplu continuăm să acumulăm straturi, așa cum a făcut Microsoft cu câștigătorul său ImageNet, ResNet, care avea peste 150 de straturi? Sau combinația corectă de MLP-uri este un ansamblu de mai mulți algoritmi care votează într-un fel de democrație computațională asupra celei mai bune predicții? Sau este vorba de încorporarea unui algoritm în altul, așa cum facem cu rețelele grafice convoluționale?
3) Acestea sunt utilizate pe scară largă la Google, care este probabil cea mai sofisticată companie de inteligență artificială din lume, pentru o gamă largă de sarcini, în ciuda existenței unor metode mai complexe, de ultimă generație.
Lecturi suplimentare
- Perceptronul: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, de Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptron: An Introduction to Computational Geometry, de Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Hebbian Theory
Other Pathmind Wiki Posts
- Rețele neuronale profunde
- Recurrent Neural Networks
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning