- Ce este un clasificator?
- Algoritmi de clasificare
Anni de zile era nevoie de un background în domeniul științei datelor și al ingineriei pentru a utiliza AI și învățarea automată, dar noile instrumente ușor de utilizat și platformele SaaS fac învățarea automată accesibilă tuturor.
Clasificatorii de învățare automată sunt una dintre utilizările de top ale tehnologiei AI – pentru a analiza automat datele, a raționaliza procesele și a aduna informații valoroase.
- Ce este un clasificator în învățarea automată?
- Care este diferența dintre un clasificator și un model?
- Testați cu propriul text
- Rezultate
- 5 tipuri de algoritmi de clasificare
- Arbore de decizie
- Clasificatorul Bayes naiv
- K-Nearest Neighbors
- Mașini vectoriale de sprijin (SVM)
- Rețele neuronale artificiale
- Puneți clasificatorii de învățare automată să lucreze pentru dumneavoastră
Ce este un clasificator în învățarea automată?
Un clasificator în învățarea automată este un algoritm care ordonează sau clasifică automat datele în una sau mai multe dintre un set de „clase”. Unul dintre cele mai comune exemple este un clasificator de e-mailuri care scanează e-mailurile pentru a le filtra în funcție de eticheta clasei: Spam sau Not Spam.
Algoritmii de învățare mecanică sunt utili pentru a automatiza sarcini care anterior trebuiau făcute manual. Ei pot economisi cantități uriașe de timp și bani și pot face afacerile mai eficiente.
Care este diferența dintre un clasificator și un model?
Un clasificator este algoritmul în sine – regulile folosite de mașini pentru a clasifica datele. Un model de clasificare, pe de altă parte, este rezultatul final al învățării automate a clasificatorului dumneavoastră. Modelul este antrenat cu ajutorul clasificatorului, astfel încât modelul, în cele din urmă, clasifică datele dumneavoastră.
Există atât clasificatori supravegheați, cât și nesupravegheați. Clasificatoarele de învățare automată nesupravegheate sunt alimentate doar cu seturi de date neetichetate, pe care le clasifică în funcție de recunoașterea modelelor sau de structurile și anomaliile din date. Clasificatorii supravegheați și semisupravegheați sunt alimentați cu seturi de date de instruire, din care învață să clasifice datele în funcție de categorii prestabilite.
Analiza sentimentelor este un exemplu de învățare mecanică supravegheată, în care clasificatorii sunt instruiți să analizeze textul pentru polaritatea opiniilor și să scoată textul în clasa respectivă: Pozitiv, Neutru sau Negativ. Încercați acest model pre-antrenat de analiză a sentimentului pentru a vedea cum funcționează.
Testați cu propriul text
Rezultate
Clasificatorii de învățare mecanică sunt utilizați pentru a analiza automat comentariile clienților (precum cel de mai sus) din social media, e-mailuri, recenzii online etc., pentru a afla ce spun clienții despre marca dvs.
Alte tehnici de analiză a textului, cum ar fi clasificarea subiectelor, pot sorta automat biletele de serviciu clienți sau sondajele NPS, le pot clasifica în funcție de subiect (Prețuri, Caracteristici, Asistență etc.) și le pot direcționa către departamentul sau angajatul corect.
Platformele de analiză de text SaaS, cum ar fi MonkeyLearn, oferă acces ușor la algoritmi puternici de clasificare, permițându-vă să construiți modele de clasificare personalizate în funcție de nevoile și criteriile dumneavoastră, de obicei în doar câțiva pași.
Clasificatorii de învățare mecanică merg dincolo de simpla cartografiere a datelor, permițând utilizatorilor să actualizeze în mod constant modelele cu noi date de învățare și să le adapteze la nevoile în schimbare. Mașinile care se conduc singure, de exemplu, folosesc algoritmi de clasificare pentru a introduce date de imagine într-o categorie; fie că este vorba de un semn de oprire, de un pieton sau de o altă mașină, învățând și îmbunătățindu-se în mod constant în timp.
Dar care sunt principalii algoritmi de clasificare și cum funcționează?
5 tipuri de algoritmi de clasificare
În funcție de nevoile dvs. și de datele dvs., acești 5 algoritmi de clasificare de top ar trebui să vă acopere.
- Arbore de decizie
- Naive Bayes Classifier
- K-Nearest Neighbors
- Support Vector Machines
- Artificial Neural Networks
Arbore de decizie
Un arbore de decizie este un algoritm de clasificare supravegheat de învățare automată utilizat pentru a construi modele ca structura unui arbore. Acesta clasifică datele în categorii din ce în ce mai fine: de la „trunchi de copac”, la „ramuri”, la „frunze”. Folosește regula dacă-atunci a matematicii pentru a crea subcategorii care se încadrează în categorii mai largi și permite o clasificare precisă, organică.
De exemplu, iată cum ar clasifica un arbore de decizie sporturile individuale:
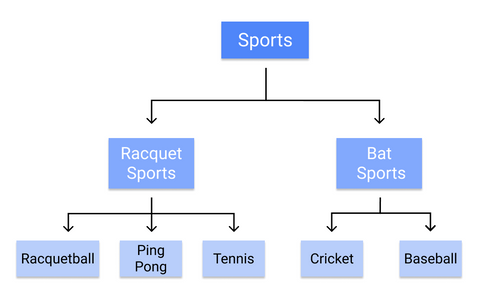
Pentru că regulile sunt învățate secvențial, de la trunchi la frunză, un arbore de decizie necesită date de înaltă calitate, curate, încă de la începutul antrenamentului, altfel ramurile pot deveni supraadaptate sau distorsionate.
Clasificatorul Bayes naiv
Bayes naiv este o familie de algoritmi probabilistici care calculează posibilitatea ca orice punct de date dat să se încadreze în una sau mai multe dintre un grup de categorii (sau nu). În analiza de text, Naive Bayes este utilizat pentru a clasifica comentariile clienților, articolele de știri, e-mailurile etc., în subiecte, teme sau „etichete” pentru a le organiza în funcție de criterii prestabilite, cum ar fi acesta:
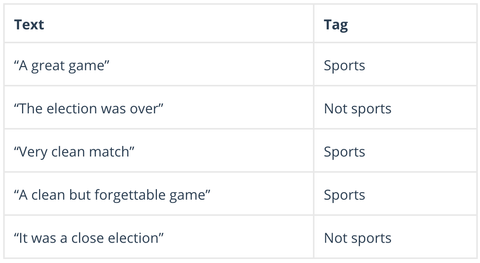
Algoritmii Naive Bayes calculează probabilitatea fiecărei etichete pentru un text dat, apoi ies pentru cea mai mare probabilitate:

Înseamnă că, probabilitatea ca A, dacă B este adevărat, este egală cu probabilitatea ca B, dacă A este adevărat, înmulțită cu probabilitatea ca A să fie adevărat, împărțită la probabilitatea ca B să fie adevărat.
Mutând de la o etichetă la alta, aceasta calculează probabilitatea ca un punct de date să aparțină sau nu unei anumite categorii: Da/Nu.
K-Nearest Neighbors
K-nearest neighbors (k-NN) este un algoritm de recunoaștere a tiparelor care stochează și învață din punctele de date de antrenament prin calcularea modului în care acestea corespund altor date în spațiul n-dimensional. K-NN urmărește să găsească cele mai apropiate k puncte de date înrudite în datele viitoare, nevăzute.
În analiza de text, k-NN ar plasa un cuvânt sau o frază dată într-o categorie predeterminată prin calcularea celui mai apropiat vecin al său: k este decis prin votul plural al vecinilor săi. Dacă k = 1, ar fi etichetat în clasa cea mai apropiată de 1.
Mașini vectoriale de sprijin (SVM)
Argitmii SVM clasifică datele și antrenează modele în cadrul unor grade super finite de polaritate, creând un model de clasificare tridimensional care depășește doar axele de predicție X/Y.
Aruncă o privire la această reprezentare vizuală pentru a înțelege cum funcționează algoritmii SVM. Avem două etichete: roșu și albastru, cu două caracteristici de date: X și Y, și antrenăm clasificatorul nostru pentru a produce o coordonată X/Y ca fiind roșie sau albastră.
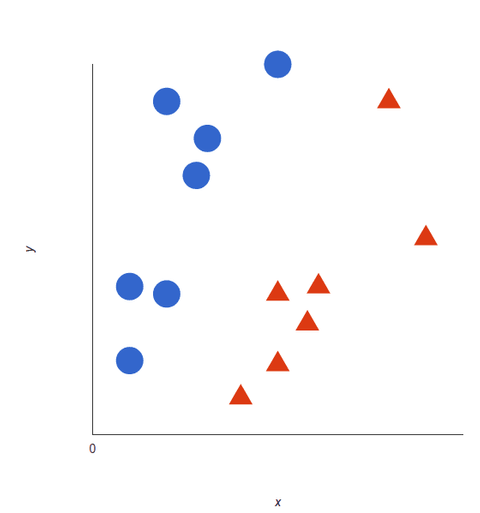
SVM-ul atribuie un hiperplan care separă cel mai bine (distinge între) etichetele. În două dimensiuni, acesta este pur și simplu o linie dreaptă. Etichetele albastre se încadrează pe o parte a hiperplanului, iar cele roșii pe cealaltă parte. În analiza sentimentelor, aceste etichete ar fi Pozitiv și Negativ.
Pentru a maximiza antrenarea modelului de învățare automată, cel mai bun hiperplan este cel care are cea mai mare distanță între fiecare etichetă:
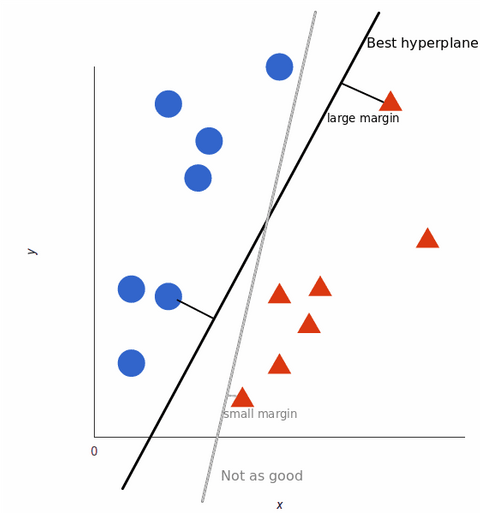
Pe măsură ce seturile noastre de date devin mai complexe, este posibil să nu fie posibilă trasarea unei singure linii care să facă distincția între cele două clase:
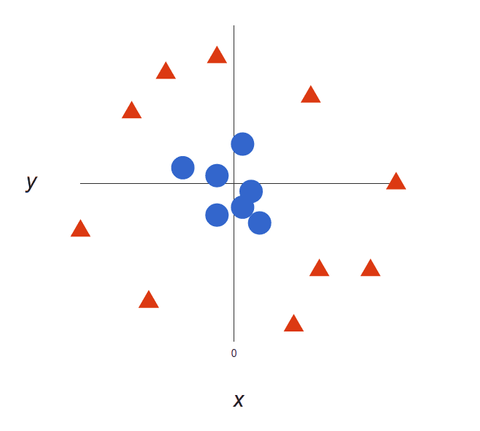
Algoritmii SVM sunt clasificatori excelenți deoarece, cu cât datele sunt mai complexe, cu atât predicția va fi mai precisă. Imaginați-vă imaginea de mai sus ca o ieșire tridimensională, cu o axă Z adăugată, astfel încât să devină un cerc.
Mapped back to 2D, cu cel mai bun hiperplan, arată astfel:
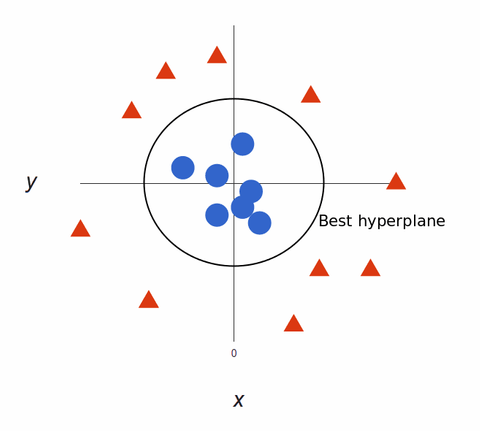
Algoritmii SVM creează modele de învățare automată foarte precise, deoarece sunt multidimensionali.
Rețele neuronale artificiale
Rețelele neuronale artificiale nu sunt un „tip” de algoritm, cât sunt o colecție de algoritmi care lucrează împreună pentru a rezolva probleme.
Rețelele neuronale artificiale sunt concepute pentru a funcționa la fel ca și creierul uman. Ele conectează procesele de rezolvare a problemelor într-un lanț de evenimente, astfel încât, odată ce un algoritm sau un proces a rezolvat o problemă, următorul algoritm (sau verigă din lanț) este activat.
Rețelele neuronale artificiale sau modelele de „învățare profundă” necesită cantități uriașe de date de antrenament, deoarece procesele lor sunt foarte avansate, dar, odată ce au fost antrenate în mod corespunzător, acestea pot avea performanțe care depășesc alți algoritmi individuali.
Există o varietate de rețele neuronale artificiale, inclusiv rețele convoluționale, recurente, de tip feed-forward etc., iar arhitectura de învățare automată cea mai potrivită pentru nevoile dumneavoastră depinde de problema pe care doriți să o rezolvați.
Puneți clasificatorii de învățare automată să lucreze pentru dumneavoastră
Algoritmii de clasificare permit automatizarea sarcinilor de învățare automată care erau de neconceput cu doar câțiva ani în urmă. Și, mai mult decât atât, vă permit să antrenați modele de inteligență artificială în funcție de nevoile, limbajul și criteriile afacerii dumneavoastră, performând mult mai rapid și cu un nivel de acuratețe mai mare decât ar fi putut-o face vreodată oamenii.
MonkeyLearn este o platformă de analiză a textelor prin învățare automată care valorifică puterea clasificatorilor de învățare automată cu o interfață extrem de ușor de utilizat, astfel încât să puteți simplifica procesele și să obțineți maximul din datele dumneavoastră de text pentru a obține informații valoroase.
Încercați aceste modele de clasificare pre-antrenate pentru a vedea cum funcționează:
- NPS Survey Feedback Classifier: clasificați automat răspunsurile deschise la sondaje în categoriile Asistență clienți, Ușurința de utilizare, Caracteristici și Prețuri
- Sentiment Analyzer: analizați orice text pentru polaritatea opiniilor: Pozitiv, Negativ, Neutru
- Email Intent Classifier: clasificați automat răspunsurile prin e-mail ca fiind Interesat, Neinteresat, Autoresponder, Email Bounce, Dezabonare sau Persoană greșită
Sau programați o demonstrație gratuită pentru a vedea tot ceea ce MonkeyLearn are de oferit.