Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
O perceptron ocupa um lugar especial na história das redes neurais e da inteligência artificial, porque o hype inicial sobre o seu desempenho levou a uma refutação por parte de Minsky e Papert, e a uma maior propagação do backlash que lançou um manto na pesquisa das redes neurais durante décadas, uma rede neural de inverno que só descongelou completamente com a pesquisa de Geoff Hinton nos anos 2000, cujos resultados varreram desde então a comunidade de aprendizagem da máquina.
Frank Rosenblatt, padrinho do perceptron, popularizou-o como um dispositivo e não como um algoritmo. O perceptron primeiro entrou no mundo como hardware.1 Rosenblatt, um psicólogo que estudou e posteriormente lecionou na Universidade Cornell, recebeu financiamento do Escritório de Pesquisa Naval dos EUA para construir uma máquina que pudesse aprender. Sua máquina, a Mark I perceptron, tinha este aspecto.

Um perceptron é um classificador linear; ou seja, é um algoritmo que classifica a entrada, separando duas categorias com uma linha reta. O input é tipicamente um vector de característica x multiplicado por pesos w e adicionado a um bias by = w * x + b.
Um perceptron produz uma única saída baseada em várias entradas com valor real, formando uma combinação linear usando seus pesos de entrada (e às vezes passando a saída por uma função de ativação não linear). Eis como se pode escrever isso em matemática:
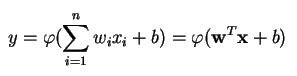
onde w denota o vector de pesos, x é o vector de entradas, b é o bias e phi é a função de activação não linear.
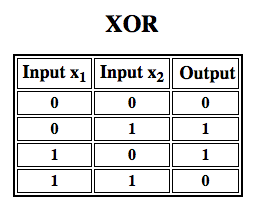
Rosenblatt construiu um perceptron de camada única. Ou seja, seu algoritmo de hardware não incluiu múltiplas camadas, o que permite que as redes neurais modelem uma hierarquia de características. Era, portanto, uma rede neural rasa, o que impedia que seu perceptron realizasse uma classificação não linear, como a função XOR (um operador XOR aciona quando a entrada exibe uma ou outra característica, mas não ambas; significa “OR exclusivo”), como Minsky e Papert mostraram em seu livro.
Apply Reinforcement Learning to Simulations “
Multilayer Perceptrons (MLP)
Trabalho subseqüente com perceptrons multicamadas mostrou que eles são capazes de aproximar um operador XOR, bem como muitas outras funções não-lineares.
Apenas como Rosenblatt baseado o perceptron num neurónio McCulloch-Pitts, concebido em 1943, assim também os próprios perceptrons são blocos de construção que só provam ser úteis em funções tão grandes como perceptrons multicamadas.2)
O perceptron multicamadas é o olá mundo do aprendizado profundo: um bom lugar para começar quando você está aprendendo sobre o aprendizado profundo.
Um perceptron multicamadas (MLP) é uma rede neural profunda e artificial. É composta por mais do que um perceptron. Eles são compostos de uma camada de entrada para receber o sinal, uma camada de saída que toma uma decisão ou previsão sobre a entrada, e entre essas duas, um número arbitrário de camadas ocultas que são o verdadeiro motor computacional do MLP. Os MLPs com uma camada oculta são capazes de se aproximar de qualquer função contínua.
Perceptores de várias camadas são frequentemente aplicados a problemas de aprendizagem supervisionados3: eles treinam num conjunto de pares input-output e aprendem a modelar a correlação (ou dependências) entre essas entradas e saídas. O treinamento envolve o ajuste dos parâmetros, ou dos pesos e viés, do modelo de forma a minimizar erros. A retropropagação é usada para fazer aqueles ajustes de peso e viés relativos ao erro, e o erro em si pode ser medido de várias maneiras, incluindo por erro médio quadrático (RMSE).
Rede de alimentação como o MLPs são como o tênis, ou ping pong. Eles estão envolvidos principalmente em dois movimentos, um constante para frente e para trás. Você pode pensar neste ping pong de suposições e respostas como uma espécie de ciência acelerada, já que cada suposição é um teste do que achamos que sabemos, e cada resposta é um feedback que nos permite saber o quanto estamos errados.
Na passagem para frente, o fluxo de sinal move-se da camada de entrada através das camadas ocultas para a camada de saída, e a decisão da camada de saída é medida contra as etiquetas da verdade do solo.
Na passagem para trás, usando a retropropagação e a regra da cadeia de cálculo, derivadas parciais da função de erro u.r.t. os vários pesos e viés são retropropagados através do MLP. Esse ato de diferenciação nos dá um gradiente, ou uma paisagem de erro, ao longo do qual os parâmetros podem ser ajustados à medida que eles movem o MLP um passo mais próximo do mínimo de erro. Isto pode ser feito com qualquer algoritmo de otimização baseado em gradientes, como a descida de gradientes estocásticos. A rede continua a jogar esse jogo de ténis até que o erro não possa descer mais. Este estado é conhecido como convergência.
Footnotes
1) O interessante aqui é que software e hardware existem em um fluxograma: software pode ser expresso como hardware e vice-versa. Quando chips como FPGAs são programados, ou ASICs são construídos para transformar um certo algoritmo em silício, estamos simplesmente implementando software um nível abaixo para fazê-lo funcionar mais rápido. Da mesma forma, o que é cozido em silício ou ligado em conjunto com luzes e potenciômetros, como o Mark I de Rosenblatt, também pode ser expresso simbolicamente em código. É por isso que Alan Kay disse: “As pessoas que realmente levam o software a sério devem fazer o seu próprio hardware”. Mas não há almoço grátis; ou seja, o que se ganha em velocidade com algoritmos de cozimento em silício, perde-se em flexibilidade e vice-versa. Acontece que isto é um problema real no que diz respeito à aprendizagem da máquina, uma vez que os algoritmos se alteram através da exposição aos dados. O desafio é encontrar as partes do algoritmo que permanecem estáveis mesmo quando os parâmetros mudam; por exemplo, as operações de álgebra linear que são atualmente processadas mais rapidamente pelas GPUs.
2) Seus pensamentos podem inclinar-se para o próximo passo em algoritmos cada vez mais complexos e também mais úteis. Passamos de um neurônio para vários, chamado de uma camada; passamos de uma camada para várias, chamado de um perceptron de várias camadas. Podemos passar de um MLP para vários, ou simplesmente continuamos a empilhar em camadas, como a Microsoft fez com o seu vencedor do ImageNet, o ResNet, que tinha mais de 150 camadas? Ou a combinação certa de MLPs é um conjunto de muitos algoritmos de votação em uma espécie de democracia computacional sobre a melhor previsão? Ou será que incorpora um algoritmo dentro de outro, como fazemos com as redes convolucionais gráficas?
3) São amplamente utilizados no Google, que é provavelmente a empresa de IA mais sofisticada do mundo, para uma vasta gama de tarefas, apesar da existência de métodos mais complexos e de última geração.
Outras Leituras
- The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, por Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: Uma Introdução à Geometria Computacional, por Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Teoria Hebbiana
Outros Posts Wiki Pathmind
- Deep Neural Networks
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning