Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
Perceptron zaujímá v historii neuronových sítí a umělé inteligence zvláštní místo, protože počáteční humbuk kolem jeho výkonnosti vedl k vyvrácení ze strany Minského a Paperta a k širšímu rozšíření odporu, který na výzkum neuronových sítí vrhl na desítky let stín, zimu neuronových sítí, která zcela roztála až s výzkumem Geoffa Hintona v roce 2000, jehož výsledky od té doby zachvátily komunitu strojového učení.
Frank Rosenblatt, kmotr perceptronu, jej zpopularizoval spíše jako zařízení než jako algoritmus. Perceptron poprvé vstoupil do světa jako hardware.1 Rosenblatt, psycholog, který studoval a později přednášel na Cornellově univerzitě, získal finanční prostředky od amerického Úřadu pro námořní výzkum, aby sestrojil stroj, který se dokáže učit. Jeho stroj, perceptron Mark I, vypadal takto.

Perceptron je lineární klasifikátor; to znamená, že je to algoritmus, který klasifikuje vstupní data tak, že odděluje dvě kategorie přímkou. Vstupem je obvykle vektor příznaků x vynásobený váhami w a přičtený ke zkreslení by = w * x + b.
Perceptron vytváří jeden výstup na základě několika vstupů s reálnou hodnotou tak, že pomocí vstupních vah vytvoří lineární kombinaci (a někdy výstup prochází nelineární aktivační funkcí). Takto se to dá zapsat matematicky:
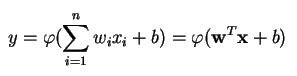
kde w označuje vektor vah, x je vektor vstupů, b je zkreslení a phi je nelineární aktivační funkce.
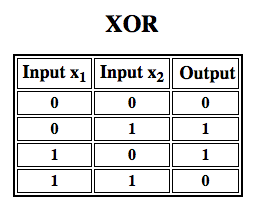
Rosenblatt sestavil jednovrstvý perceptron. To znamená, že jeho hardwarový algoritmus neobsahoval více vrstev, které umožňují neuronovým sítím modelovat hierarchii funkcí. Jednalo se tedy o mělkou neuronovou síť, což jeho perceptronu znemožňovalo provádět nelineární klasifikaci, jako je například funkce XOR (operátor XOR se spouští, když vstup vykazuje buď jeden, nebo druhý znak, ale ne oba; znamená „exkluzivní OR“), jak ukázali Minsky a Papert ve své knize.
Použití posilovacího učení v simulacích“
Vícevrstvé perceptrony (MLP)
Další práce s vícevrstvými perceptrony ukázala, že jsou schopny aproximovat operátor XOR i mnoho dalších nelineárních funkcí.
Stejně jako Rosenblatt založil perceptron na McCullochově-Pittsově neuronu, který byl koncipován v roce 1943, tak i samotné perceptrony jsou stavebními kameny, které se ukáží být užitečné až v takových větších funkcích, jako jsou vícevrstvé perceptrony2.)
Vícevrstvý perceptron je zdravým světem hlubokého učení: je dobrým začátkem, když se učíte o hlubokém učení.
Vícevrstvý perceptron (MLP) je hluboká umělá neuronová síť. Skládá se z více než jednoho perceptronu. Skládá se ze vstupní vrstvy, která přijímá signál, výstupní vrstvy, která provádí rozhodnutí nebo předpověď o vstupu, a mezi těmito dvěma vrstvami je libovolný počet skrytých vrstev, které jsou skutečným výpočetním motorem MLP. MLP s jednou skrytou vrstvou jsou schopny aproximovat libovolnou spojitou funkci.
Vícevrstvé perceptrony se často používají k řešení problémů učení pod dohledem3: trénují se na sadě dvojic vstup-výstup a učí se modelovat korelaci (nebo závislosti) mezi těmito vstupy a výstupy. Trénování zahrnuje úpravu parametrů neboli vah a zkreslení modelu s cílem minimalizovat chybu. K těmto úpravám vah a zkreslení vzhledem k chybě se používá zpětné šíření a samotnou chybu lze měřit různými způsoby, včetně střední kvadratické chyby (RMSE).
Sítě typu MLP jsou jako tenis nebo ping pong. Podílejí se především na dvou pohybech, neustálém pohybu tam a zpět. Tento ping pong odhadů a odpovědí si můžete představit jako druh zrychlené vědy, protože každý odhad je testem toho, co si myslíme, že víme, a každá odpověď je zpětnou vazbou, která nám dává najevo, jak moc se mýlíme.
Při dopředném průchodu se tok signálu pohybuje ze vstupní vrstvy přes skryté vrstvy do výstupní vrstvy a rozhodnutí výstupní vrstvy se měří oproti základním pravdivým štítkům.
Při zpětném průchodu se pomocí zpětného šíření a řetězového pravidla kalkulu zpětně šíří parciální derivace chybové funkce v závislosti na různých vahách a zkresleních prostřednictvím MLP. Touto diferenciací získáme gradient neboli krajinu chyby, podél které lze upravovat parametry tak, aby se MLP o krok přiblížil k minimu chyby. To lze provést pomocí libovolného optimalizačního algoritmu založeného na gradientu, jako je stochastický sestup po gradientu. Síť hraje tuto tenisovou hru, dokud chyba nemůže klesnout níže. Tento stav se nazývá konvergence.
Poznámky
1) Zajímavé je zde upozornit na to, že software a hardware existují na vývojovém diagramu: software lze vyjádřit jako hardware a naopak. Když se programují čipy, jako jsou FPGA, nebo se konstruují ASIC, aby se do křemíku zapekl určitý algoritmus, jednoduše implementujeme software o úroveň níže, aby fungoval rychleji. Stejně tak to, co je zapečeno v křemíku nebo zapojeno pomocí světel a potenciometrů, jako Rosenblattova značka I, může být také vyjádřeno symbolicky v kódu. Proto Alan Kay řekl: „Lidé, kteří to se softwarem myslí opravdu vážně, by si měli vyrobit svůj vlastní hardware“. Neexistuje však žádný oběd zdarma, tj. co získáte na rychlosti tím, že algoritmy zapracujete do křemíku, ztratíte na flexibilitě, a naopak. To se stává skutečným problémem v souvislosti se strojovým učením, protože algoritmy se samy mění působením dat. Výzvou je najít ty části algoritmu, které zůstanou stabilní i při změně parametrů; např. operace lineární algebry, které v současnosti nejrychleji zpracovávají grafické procesory.
2) Vaše myšlenky se mohou přiklonit k dalšímu kroku ve stále složitějších a také užitečnějších algoritmech. Přecházíme od jednoho neuronu k několika, kterým se říká vrstva; přecházíme od jedné vrstvy k několika, kterým se říká vícevrstvý perceptron. Můžeme přejít od jednoho MLP k několika, nebo budeme jednoduše vršit vrstvy, jako to udělala společnost Microsoft se svým vítězem ImageNet, ResNet, který měl více než 150 vrstev? Nebo je správnou kombinací MLP soubor mnoha algoritmů, které hlasují v jakési počítačové demokracii o nejlepší předpovědi? Nebo je to vložení jednoho algoritmu do druhého, jako je tomu u grafových konvolučních sítí?
3) Ve společnosti Google, která je pravděpodobně nejsofistikovanější společností zabývající se umělou inteligencí na světě, se široce používají pro širokou škálu úloh, a to navzdory existenci složitějších, nejmodernějších metod.
Další čtení
- Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrony: Úvod do výpočetní geometrie, Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Hebbova teorie
Další příspěvky na Pathmind Wiki
- Hluboké neuronové sítě
- Rekurentní neuronová síť Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning