Die Entdeckung von Themen in qualitativen Daten kann entmutigend und schwierig sein. Die Zusammenfassung einer quantitativen Studie ist relativ klar: Sie haben 25% besser abgeschnitten als die Konkurrenz, sagen wir mal. Aber wie fasst man eine Sammlung qualitativer Beobachtungen zusammen?
In der Anfangsphase eines Projekts wird oft eine explorative Forschung durchgeführt. Diese Forschung bringt oft eine Menge qualitativer Daten hervor, die Folgendes beinhalten können:
Qualitative Einstellungsdaten, wie z.B. die Gedanken, Überzeugungen und selbstberichteten Bedürfnisse der Menschen, die aus Nutzerinterviews, Fokusgruppen und sogar Tagebuchstudien gewonnen werden
Qualitative Verhaltensdaten, wie z.B. Beobachtungen über das Verhalten von Menschen, die durch kontextbezogene Untersuchungen und andere ethnografische Ansätze gesammelt wurden
Die thematische Analyse, die jeder durchführen kann, macht wichtige Aspekte der qualitativen Daten sichtbar und erleichtert die Aufdeckung von Themen.
- Was ist eine Thematische Analyse?
- Herausforderungen bei der Analyse qualitativer Daten
- Werkzeuge und Methoden zur Durchführung der thematischen Analyse
- Verwendung von Software
- Journaling
- Affinity-Diagramming Techniques
- Codes und Kodierung
- Codetypen: Beschreibend und interpretierend
- Schritte zur Durchführung einer thematischen Analyse
- Schritt 1: Sammeln Sie alle Ihre Daten
- Schritt 2: Lesen Sie alle Ihre Daten von Anfang bis Ende
- Schritt 3: Kodieren des Textes auf der Grundlage des Themas
- Traditionelle Methode: Codes vor der Gruppierung erstellen
- Schnelle Methode: Gruppieren von Textsegmenten und Zuweisen eines Codes
- Schritt 4: Erstellen Sie neue Codes, die potenzielle Themen einschließen
- Schritt 5: Einen Tag Pause machen und dann zu den Daten zurückkehren
- Schritt 6: Bewerten Sie Ihre Themen auf gute Passung
- Fazit
Was ist eine Thematische Analyse?
Definition: Die thematische Analyse ist eine systematische Methode, um reichhaltige Daten aus der qualitativen Forschung aufzuschlüsseln und zu organisieren, indem einzelne Beobachtungen und Zitate mit entsprechenden Codes versehen werden, um die Entdeckung bedeutender Themen zu erleichtern.
Wie der Name schon sagt, geht es bei einer thematischen Analyse darum, Themen zu finden.
Definition: Ein Thema:
- ist eine Beschreibung einer Überzeugung, einer Praxis, eines Bedürfnisses oder eines anderen Phänomens, das aus den Daten entdeckt wird
- entsteht, wenn verwandte Befunde mehrfach über Teilnehmer oder Datenquellen hinweg auftauchen
Herausforderungen bei der Analyse qualitativer Daten
Viele Forscher fühlen sich von qualitativen Daten aus explorativer Forschung, die in den frühen Phasen eines Projekts durchgeführt werden, überfordert. Die folgende Tabelle zeigt einige häufige Herausforderungen und daraus resultierende Probleme.
| CHALLENGES | RESULTING ISSUES |
|
Large quantity of data: Qualitative research results in long transcripts and extensive field notes that can be time-consuming to read; you may have a hard time seeing patterns and remembering what’s important. |
Superficial analysis: Analysis is often done very superficially, just skimming topics, focusing on only memorable events and quotes, and missing large sections of notes. |
|
Rich data: There are lots of detail within every sentence or paragraph. It can be hard to see which details are useful and which are superfluous. |
Analysis becomes a description of many details: The analysis simply becomes a regurgitation of what participants‘ may have said or done, without any analytical thinking applied to it. |
|
Contradicting data: Manchmal enthalten die Daten verschiedener Teilnehmer oder sogar desselben Teilnehmers Widersprüche, die die Forscher auswerten müssen. |
Die Ergebnisse sind nicht endgültig: Die Analyse ist nicht endgültig, weil die Rückmeldungen der Teilnehmer widersprüchlich sind oder, schlimmer noch, Standpunkte, die nicht mit den Überzeugungen des Forschers übereinstimmen, ignoriert werden. |
| Keine Ziele für die Analyse festgelegt: Die Ziele der anfänglichen Datenerhebung gehen verloren, weil sich die Forscher leicht zu sehr in Details verlieren. | Vergeudete Zeit und fehlgeleitete Analyse: Der Analyse fehlt der Fokus und die Forschung berichtet über das Falsche. |
Ohne eine Form von systematischem Prozess entstehen bei der Analyse qualitativer Daten leicht die skizzierten Probleme. Die thematische Analyse sorgt dafür, dass die Forscher organisiert und fokussiert sind und gibt ihnen ein allgemeines Verfahren an die Hand, dem sie bei der Analyse qualitativer Daten folgen können.
Werkzeuge und Methoden zur Durchführung der thematischen Analyse
Eine thematische Analyse kann auf viele verschiedene Arten durchgeführt werden. Das beste Werkzeug oder die beste Methode für diesen Prozess wird auf der Grundlage folgender Faktoren bestimmt:
- Daten
- Kontext und Einschränkungen der Datenanalysephase
- der persönliche Arbeitsstil des Forschers
3 gängige Methoden sind:
- Verwendung von Software
- Journaling
- Verwendung von Affinitätsdiagrammtechniken
Verwendung von Software
Um große Mengen qualitativer Daten zu analysieren, verwenden qualitative Forscher häufig Software, die als CAQDAS (Computer-Aided Qualitative-Data-Analysis Software) bekannt ist – ausgesprochen „cak∙das“. Die Forscher laden Transkripte und Feldnotizen in ein Softwareprogramm hoch und analysieren den Text dann systematisch durch formale Kodierung. Die Software hilft bei der Entdeckung von Themen, indem sie verschiedene Visualisierungswerkzeuge wie Wortbäume oder Wortwolken anbietet, mit denen die kodierten Daten auf viele verschiedene Arten bearbeitet werden können.
Vorteile
- Die Analyse ist sehr gründlich.
- Eine physische Projektdatei (die die Rohdaten und die Analyse enthält) kann mit anderen geteilt werden. (Diese Methode ist bei Studentenprojekten an akademischen Einrichtungen sehr beliebt.)
Nachteile
- Zeitaufwendig, da viele Codes entstehen, die zu einer kleinen, überschaubaren Liste verdichtet werden müssen, überschaubare Liste verdichtet werden müssen
- Aufwändig
- Schwer mit anderen synchron zu analysieren
- Erfordert ein gewisses Maß an Einarbeitung in die Software
- Kann sich restriktiv anfühlen
Journaling
Das Aufschreiben von Gedankengängen und Ideen, die man zu einem Text hat, ist unter Forschern, die die Grounded-Theory-Methodologie anwenden, üblich. Journaling as a form of thematic analysis is based on this methodology and involves manual annotation and highlighting of the data, followed by writing down the researchers‘ ideas and thought processes. The notes are known as memos (not to be confused with the office memo delivering news to employees).
Benefits
- The process encourages reflection through the writing of detailed notes.
- Researchers have a record of how they arrived at their themes.
- The analysis is cheap and flexible.
Drawbacks
- Hard to do collaboratively
Affinity-Diagramming Techniques
The data is highlighted, cut out physically or digitally, and reassembled into meaningful groups until themes emerge on a physical or digital board. (See a video demonstrating affinity-diagramming.)
Benefits
- Can be done collaboratively
- Quick arriving at themes
- Cheap and flexible
- Visual, und unterstützt einen iterativen Analyseprozess
Nachteile
- Nicht so gründlich wie andere Methoden, da Textsegmente oft nicht mehrfach kodiert werden
- Schwer zu machen, wenn die Daten sehr vielfältig sind, oder eine große Datenmenge vorliegt
Codes und Kodierung
Alle Methoden der thematischen Analyse setzen ein gewisses Maß an Kodierung voraus (nicht zu verwechseln mit dem Schreiben eines Programms in einer Programmiersprache).
Definition: Ein Code ist ein Wort oder ein Satz, der als Etikett für ein Textsegment dient.
Ein Code beschreibt, worum es in einem Text geht, und ist eine Kurzschrift für kompliziertere Informationen. (Eine gute Analogie ist, dass ein Code Daten so beschreibt, wie ein Schlüsselwort einen Artikel oder ein Hashtag einen Tweet.) Oft haben qualitative Forscher nicht nur einen Namen für jeden Code, sondern auch eine Beschreibung der Bedeutung des Codes und Beispiele für Texte, die zu dem Code passen oder nicht passen. Diese Beschreibungen und Beispiele sind besonders nützlich, wenn mehr als eine Person für die Kodierung der Daten verantwortlich ist oder wenn die Kodierung über einen längeren Zeitraum erfolgt.
Definition: Kodierung bezeichnet den Prozess der Kennzeichnung von Textsegmenten mit den entsprechenden Codes.
Wenn die Codes einmal zugewiesen sind, ist es einfach, Textsegmente zu identifizieren und zu vergleichen, die sich auf dieselbe Sache beziehen. Die Codes ermöglichen es uns, Informationen leicht zu sortieren und Daten zu analysieren, um Ähnlichkeiten, Unterschiede und Beziehungen zwischen den Abschnitten aufzudecken. So können wir zu einem Verständnis der wesentlichen Themen gelangen.
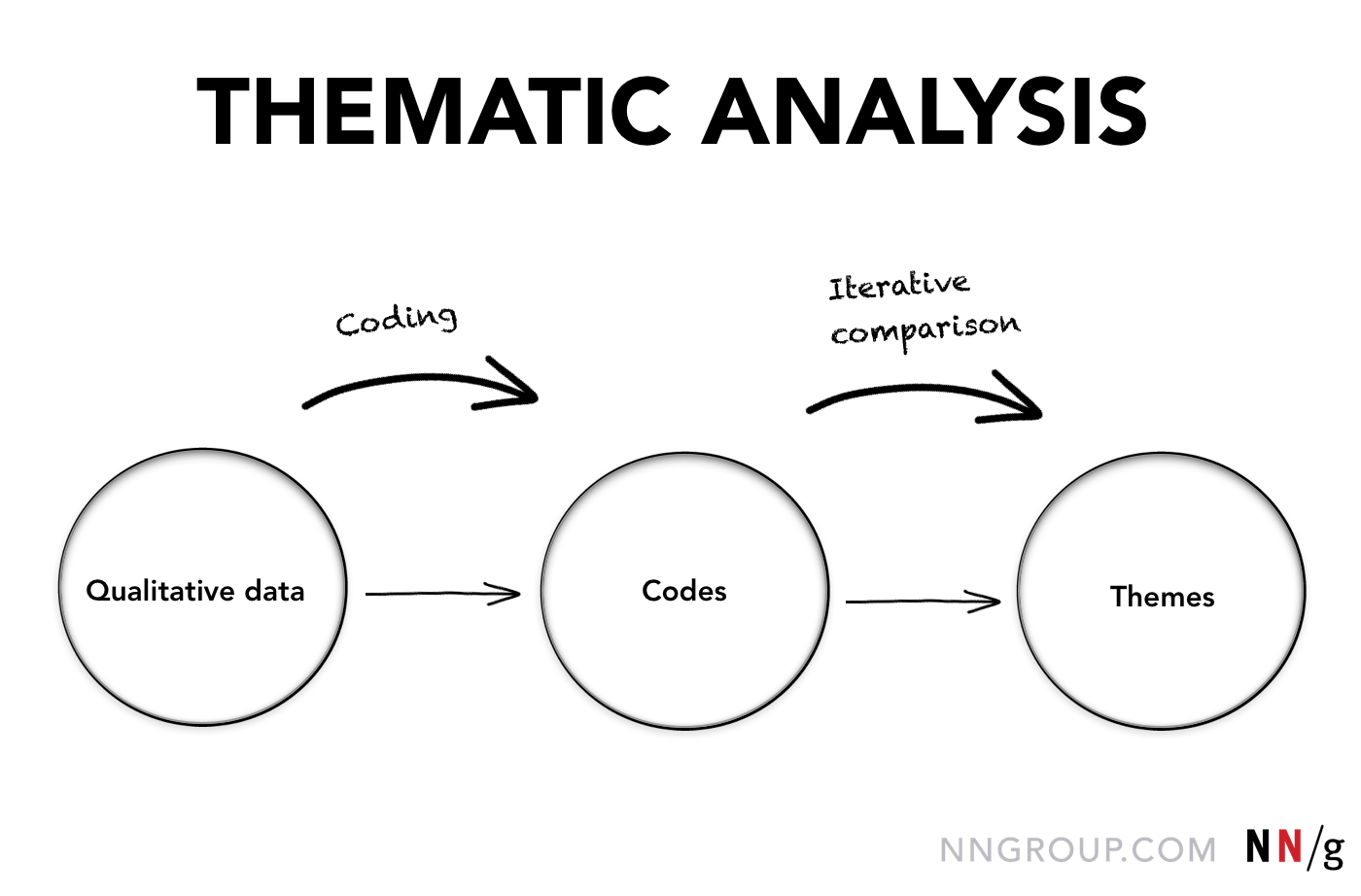
Codetypen: Beschreibend und interpretierend
Codes können sein:
- Beschreibend: Sie beschreiben, worum es in den Daten geht
- Interpretativ: Sie sind eine analytische Lesart der Daten und fügen die interpretative Linse des Forschers hinzu.
Um Beispiele für deskriptive und interpretative Codes zu sehen, sehen wir uns ein Zitat aus einem Interview an, das ich Anfang des Jahres mit einem UX-Praktiker geführt habe (als Teil unserer UX-Karriereforschung, die in unserem UX-Karrierebericht veröffentlicht wird).
„Ich hatte Angst davor, ein Meeting zu moderieren, und mein Unternehmen bot einen anderthalbtägigen Kurs an. Ich ging also hin, und der Kursleiter tat etwas, das ich damals fürchterlich fand, aber inzwischen weiß ich es wirklich zu schätzen. Als Erstes füllten wir ein Blatt Papier mit unserem Namen aus und schrieben unsere schlimmsten Ängste vor der Moderation auf. Dann gaben wir es ab und er sagte: „Okay, morgen werdet ihr diese Situation nachspielen (…) am nächsten Tag kamen wir zurück und ich verließ den Raum, während der Rest des Teams meine schlimmsten Ängste las, sich überlegte, wie sie sie nachspielen würden, und dann ging ich rein und moderierte 10 Minuten lang damit. Und das hat mir wirklich geholfen zu erkennen, dass es nichts gibt, wovor man Angst haben muss, dass unsere Ängste die meiste Zeit nur in unserem Kopf sind, und dadurch habe ich gemerkt, dass ich mit diesen Situationen umgehen kann.“
Hier sind mögliche beschreibende und interpretierende Codes für den obigen Text:
Beschreibender Code: wie Fähigkeiten erworben werden
Grundlage für die Codebezeichnung: Die Teilnehmer wurden gebeten zu beschreiben, wie sie zu bestimmten Fähigkeiten gekommen sind.
Interpretationscode: Selbstreflexion
Begründung für die Codebezeichnung: Die Teilnehmerin beschreibt, wie diese Erfahrung ihre Überzeugungen über Moderation verändert hat und wie sie über ihre Angst reflektiert hat.
Schritte zur Durchführung einer thematischen Analyse
Unabhängig davon, welches Werkzeug Sie verwenden (Software, Journaling oder Affinitätsdiagramm), kann die Durchführung einer thematischen Analyse in 6 Schritte unterteilt werden.
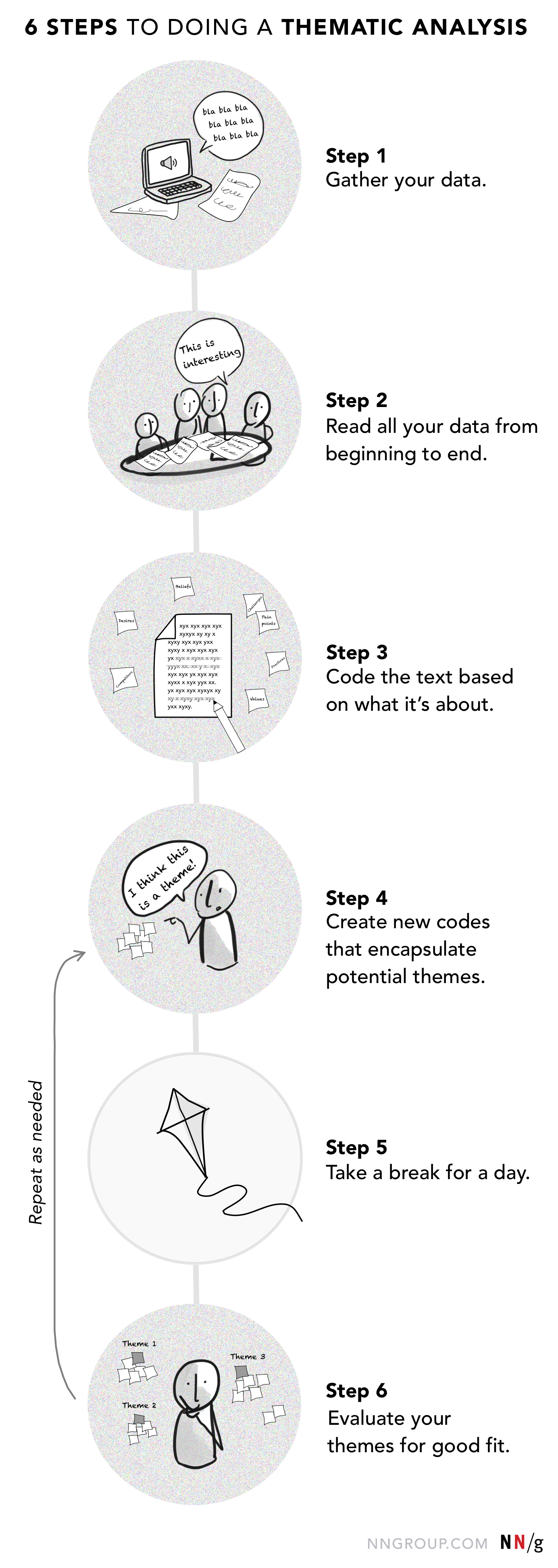
Schritt 1: Sammeln Sie alle Ihre Daten
Beginnen Sie mit den Rohdaten, z. B. Interview- oder Fokusgruppentranskripte, Feldnotizen oder Tagebucheinträge. Ich empfehle, Audioaufnahmen von Interviews zu transkribieren und die Transkriptionen für die Analyse zu verwenden, anstatt sich auf lückenhafte Erinnerungen zu verlassen.
Schritt 2: Lesen Sie alle Ihre Daten von Anfang bis Ende
Machen Sie sich mit den Daten vertraut, bevor Sie mit der Analyse beginnen, auch wenn Sie die Forschung durchgeführt haben. Lesen Sie alle Protokolle, Feldnotizen und andere Datenquellen, bevor Sie sie analysieren. In diesem Schritt können Sie Ihr Team in das Projekt einbeziehen. Durch die Einbindung Ihres Teams erwerben Sie Wissen über die Nutzer und Einfühlungsvermögen für sie und ihre Bedürfnisse.
Leiten Sie einen Workshop (oder eine Reihe von Workshops, wenn Ihr Team sehr groß ist oder Sie über eine große Datenmenge verfügen). Gehen Sie dabei folgendermaßen vor:
- Bevor sich Ihre Teammitglieder mit den Daten befassen, schreiben Sie Ihre Forschungsfragen auf eine Tafel oder ein Flipchartpapier, damit Sie sich während der Arbeit leicht auf die Fragen beziehen können.
- Geben Sie jedem Mitglied eine Abschrift oder einen Feld- oder Tagebucheintrag. Sagen Sie den Teilnehmern, dass sie alles markieren sollen, was sie für wichtig halten.
- Wenn die Teammitglieder ihre Einträge fertig gelesen haben, können sie ihre Mitschrift oder ihren Eintrag an jemand anderen weitergeben und erhalten von einem anderen Teammitglied einen neuen Eintrag. Dieser Schritt wird so lange wiederholt, bis sich alle Teammitglieder mit allen Daten beschäftigt haben.
- Diskutieren Sie in der Gruppe, was Ihnen aufgefallen ist oder was Sie überraschend fanden.

Auch wenn es am besten ist, wenn Ihr Team alle Ihre Forschungssitzungen beobachtet, ist dies bei vielen Sitzungen oder einem großen Team vielleicht nicht möglich. Wenn einzelne Teammitglieder nur eine Handvoll Sitzungen beobachten, gehen sie manchmal mit einem unvollständigen Verständnis der Ergebnisse nach Hause. Der Workshop kann dieses Problem lösen, da alle Teilnehmer alle Sitzungsprotokolle lesen.
Schritt 3: Kodieren des Textes auf der Grundlage des Themas
Im Schritt des Kodierens müssen die hervorgehobenen Abschnitte kategorisiert werden, damit die hervorgehobenen Abschnitte leicht verglichen werden können.
Erinnern Sie sich in dieser Phase an Ihre Forschungsziele. Drucken Sie Ihre Forschungsfragen aus. Hängen Sie sie an einer Wand oder einem Whiteboard in dem Raum auf, in dem Sie die Analyse durchführen.
Wenn Sie genügend Zeit haben, können Sie Ihr Team in diesen ersten Kodierungsschritt einbeziehen. Wenn Sie nur wenig Zeit haben und viele Daten durcharbeiten müssen, sollten Sie diesen Schritt allein durchführen und Ihr Team später einladen, Ihre Codes zu überprüfen und bei der Ausarbeitung der Themen zu helfen.
Während Sie codieren, überprüfen Sie jedes Textsegment und fragen Sie sich: „Worum geht es hier?“ Geben Sie dem Fragment einen Namen, der die Daten beschreibt (einen deskriptiven Code). Sie können in dieser Phase auch interpretierende Codes in den Text einfügen. Diese lassen sich jedoch in der Regel später leichter zuordnen.
Der Code kann vor oder nach der Gruppierung der Daten erstellt werden. Die nächsten beiden Abschnitte dieses Schrittes beschreiben, wie und wann Sie die Codes hinzufügen können.
Traditionelle Methode: Codes vor der Gruppierung erstellen
Bei der traditionellen Methode markieren Sie Segmente der Daten, wie Sätze, Absätze oder Phrasen, und codieren sie. Es ist hilfreich, alle verwendeten Codes zu notieren und zu erläutern, worum es sich dabei handelt, damit Sie bei der Codierung weiterer Textabschnitte auf diese Liste zurückgreifen können (insbesondere, wenn mehrere Personen den Text codieren). Auf diese Weise wird vermieden, dass mehrere Codes für dieselbe Art von Problem erstellt werden (die später konsolidiert werden müssen).
Wenn der gesamte Text kodiert wurde, können Sie alle Daten, die denselben Code haben, gruppieren.
Wenn Sie CAQDAS für diesen Prozess verwenden, protokolliert die Software automatisch die Codes, die Sie während der Kodierung vergeben, so dass Sie sie wieder verwenden können. Sie bietet Ihnen dann eine Möglichkeit, alle mit demselben Code codierten Texte zu sehen.
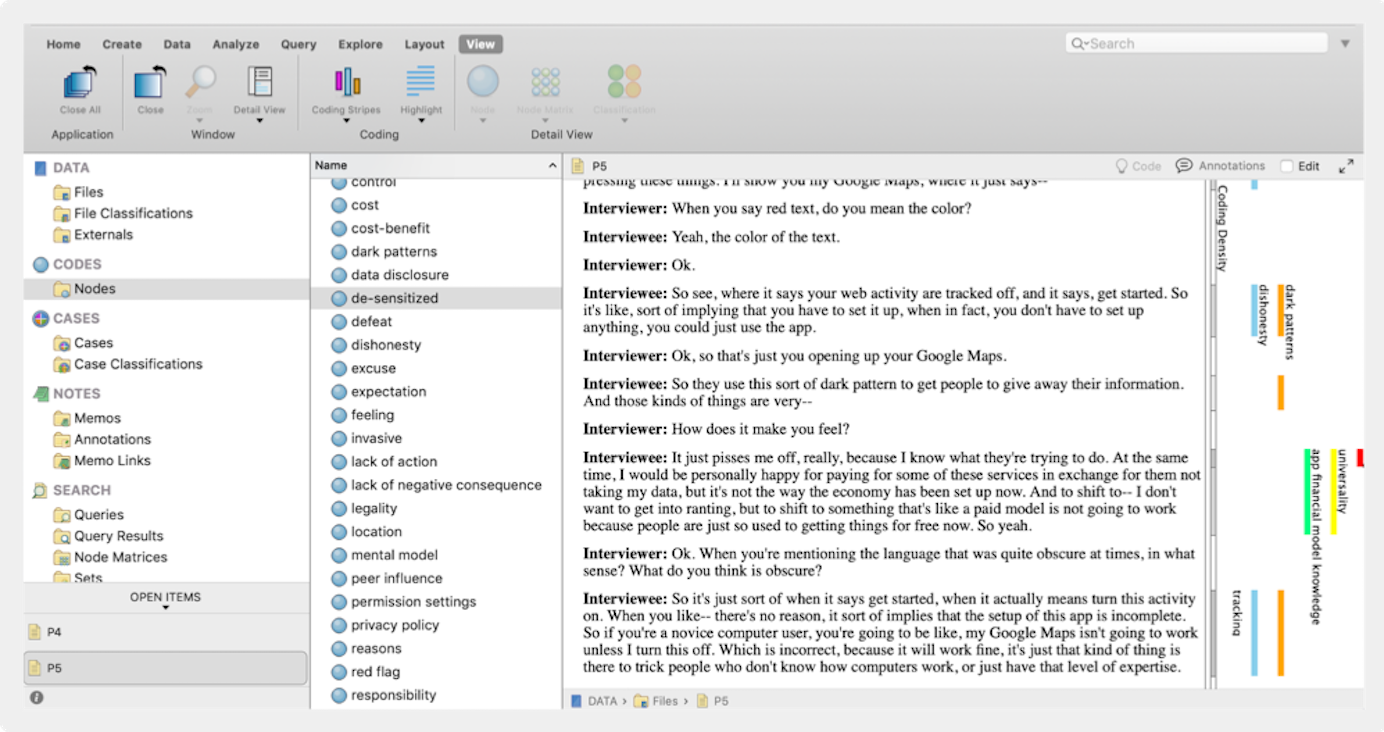
Schnelle Methode: Gruppieren von Textsegmenten und Zuweisen eines Codes
Anstatt beim Hervorheben von Text einen Code zu finden, zerschneiden Sie (physisch oder digital) alle ähnlichen hervorgehobenen Segmente und gruppieren sie (ähnlich wie verschiedene Stickies in einer Affinitätskarte gruppiert werden können). Die Gruppierungen werden dann mit einem Code versehen. Wenn Sie die Gruppierung digital vornehmen, können Sie die kodierten Abschnitte in ein neues Dokument oder eine Plattform für visuelle Zusammenarbeit ziehen.
In den folgenden Bildern wurde die Gruppierung manuell vorgenommen. Die Transkripte wurden zerschnitten, auf Klebezettel geklebt und auf der Tafel verschoben, bis sie in natürliche Themengruppen fielen. Der Forscher ordnete dann der Gruppierung einen rosafarbenen Aufkleber mit einem beschreibenden Code zu.


Am Ende dieses Schritts sollten Sie Daten haben, die nach Themen und Codes für jedes Thema gruppiert sind.
Lassen Sie uns ein Beispiel betrachten. Ich habe 3 Personen über ihre Erfahrungen beim Kochen zu Hause befragt. In diesen Interviews sprachen die Teilnehmer darüber, warum sie sich entschieden haben, bestimmte Dinge zu kochen und andere nicht. Sie sprachen über spezifische Herausforderungen, denen sie beim Kochen begegneten (z. B.,
Nachdem ich die hervorgehobenen Ausschnitte aus meinen Interviews nach Themen gruppiert hatte, kam ich zu drei allgemeinen beschreibenden Codes und den entsprechenden Gruppierungen:
- Kocherfahrungen: erinnerungswürdige positive und negative Erfahrungen im Zusammenhang mit dem Kochen
- Schmerzpunkte: alles, was jemanden vom Kochen abhält oder das Kochen erschwert (einschließlich des Umgangs mit Ernährungseinschränkungen, begrenzten Budgets usw.))
- Dinge, die helfen: was jemandem hilft (oder wovon man glaubt, dass es ihm helfen könnte), bestimmte Herausforderungen oder Schmerzpunkte zu überwinden
Schritt 4: Erstellen Sie neue Codes, die potenzielle Themen einschließen
Schauen Sie sich alle Codes an und untersuchen Sie alle kausalen Beziehungen, Ähnlichkeiten, Unterschiede oder Widersprüche, um zu sehen, ob Sie zugrunde liegende Themen aufdecken können. Dabei werden einige der Codes beiseite gelegt (entweder archiviert oder gelöscht) und neue Interpretationscodes erstellt. Wenn Sie einen physischen Mapping-Ansatz verwenden, wie er in Schritt 3 besprochen wurde, können sich einige dieser anfänglichen Gruppierungen bei der Suche nach Themen auflösen oder ausweiten.
Stellen Sie sich die folgenden Fragen:
- Was passiert in jeder Gruppe?
- Wie hängen diese Codes zusammen?
- Wie hängen diese Codes mit meinen Forschungsfragen zusammen?
Zurück zu unserem Kochthema: Als ich den Text innerhalb jeder Gruppierung analysierte und nach Beziehungen zwischen den Daten suchte, fiel mir auf, dass zwei Teilnehmerinnen sagten, dass sie Zutaten mögen, die auf verschiedene Weise zubereitet werden können und gut zu anderen Zutaten passen. Eine dritte Teilnehmerin sprach davon, dass sie sich wünschte, eine Reihe von Zutaten zu haben, die für viele verschiedene Mahlzeiten in der Woche verwendet werden können, anstatt für jeden Speiseplan separate Zutaten kaufen zu müssen. So entstand ein neues Thema über die Flexibilität von Zutaten. Für dieses Thema habe ich den Code one ingredient fits all gewählt und eine ausführliche Beschreibung verfasst.

Schritt 5: Einen Tag Pause machen und dann zu den Daten zurückkehren
Es ist fast immer eine gute Idee, eine Pause zu machen und die Daten mit neuen Augen zu betrachten. Dies hilft Ihnen manchmal dabei, signifikante Muster in den Daten klar zu erkennen und bahnbrechende Erkenntnisse zu gewinnen.
Schritt 6: Bewerten Sie Ihre Themen auf gute Passung
In diesem Schritt kann es nützlich sein, andere Personen hinzuzuziehen, die Ihnen bei der Überprüfung Ihrer Codes und aufkommenden Themen helfen. So können Sie nicht nur neue Erkenntnisse gewinnen, sondern auch Ihre Schlussfolgerungen mit neuen Augen und Köpfen hinterfragen und kritisieren. Auf diese Weise wird verhindert, dass Ihre Interpretation durch persönliche Vorurteile gefärbt wird.
Unterziehen Sie Ihre Themen einer genauen Prüfung. Stellen Sie sich folgende Fragen:
- Wird das Thema durch die Daten gut unterstützt? Oder konnten Sie Daten finden, die Ihr Thema nicht stützen?
- Ist das Thema mit vielen Instanzen gesättigt?
- Stimmen andere mit den Themen überein, die Sie in den Daten gefunden haben, nachdem Sie die Daten separat analysiert haben?
Wenn die Antwort auf diese Fragen nein lautet, könnte das bedeuten, dass Sie zum Analyseboard zurückkehren müssen. Vorausgesetzt, Sie haben solide Daten gesammelt, gibt es fast immer etwas zu lernen, so dass es sich lohnt, mehr Zeit mit Ihrem Team zu verbringen und die Schritte 4-6 zu wiederholen.
Fazit
Nutzen Sie die thematische Analyse als hilfreichen Leitfaden, um sich effizient durch eine große Menge qualitativer Daten zu wühlen. Es gibt nicht den einen Weg, eine thematische Analyse durchzuführen. Wählen Sie eine Analysemethode, die zu Art und Umfang der von Ihnen gesammelten Daten passt. Wenn möglich, sollten Sie andere Personen in den Analyseprozess einbeziehen, um sowohl die Genauigkeit der Analyse als auch das Wissen Ihres Teams über das Verhalten, die Motivationen und die Bedürfnisse Ihrer Nutzer zu erhöhen. Die Analyse kann ein langwieriger Prozess sein, daher ist es eine gute Faustregel, so viel Zeit einzuplanen, wie Sie für die Datenerfassung hatten, um die Analyse abzuschließen.
Weiteres erfahren: User Interviews, Advanced techniques to uncover values, motivations, and desires, a full-day course at the UX Conference.