Het ontdekken van thema’s in kwalitatieve data kan ontmoedigend en moeilijk zijn. Het samenvatten van een kwantitatief onderzoek is relatief duidelijk: je hebt 25% beter gescoord dan de concurrentie, laten we zeggen. Maar hoe vat je een verzameling kwalitatieve observaties samen?
In de beginfase van een project wordt vaak verkennend onderzoek gedaan. Dit onderzoek levert vaak veel kwalitatieve gegevens op, die kunnen bestaan uit:
Qitatieve attitudinale gegevens, zoals de gedachten, overtuigingen en zelfgerapporteerde behoeften van mensen, verkregen uit gebruikersinterviews, focusgroepen en zelfs dagboekstudies
Qitatieve gedragsgegevens, zoals observaties over het gedrag van mensen, verzameld via contextueel onderzoek en andere etnografische benaderingen
Thematische analyse, die iedereen kan doen, maakt belangrijke aspecten van kwalitatieve data zichtbaar en maakt het blootleggen van thema’s gemakkelijker.
- Wat is een thematische analyse?
- Uitdagingen bij het analyseren van kwalitatieve gegevens
- Tools and Methods for Conducting Thematic Analysis
- Gebruik van software
- Journaling
- Affinity-Diagramming Techniques
- Codes en codering
- Code Types: Beschrijvend en interpreterend
- Stappen om een thematische analyse uit te voeren
- Stap 1: Verzamel al uw gegevens
- Stap 2: Lees al uw gegevens van begin tot eind
- Stap 3: Codeer de tekst op basis van waar het over gaat
- Traditionele methode: Codes maken voor het groeperen
- Snelle methode: Groepeer tekstsegmenten en wijs vervolgens een code toe
- Stap 4: Creëer nieuwe codes die potentiële thema’s omvatten
- Stap 5: Neem een dag pauze en keer dan terug naar de gegevens
- Stap 6: Evalueer uw thema’s op geschiktheid
- Conclusie
Wat is een thematische analyse?
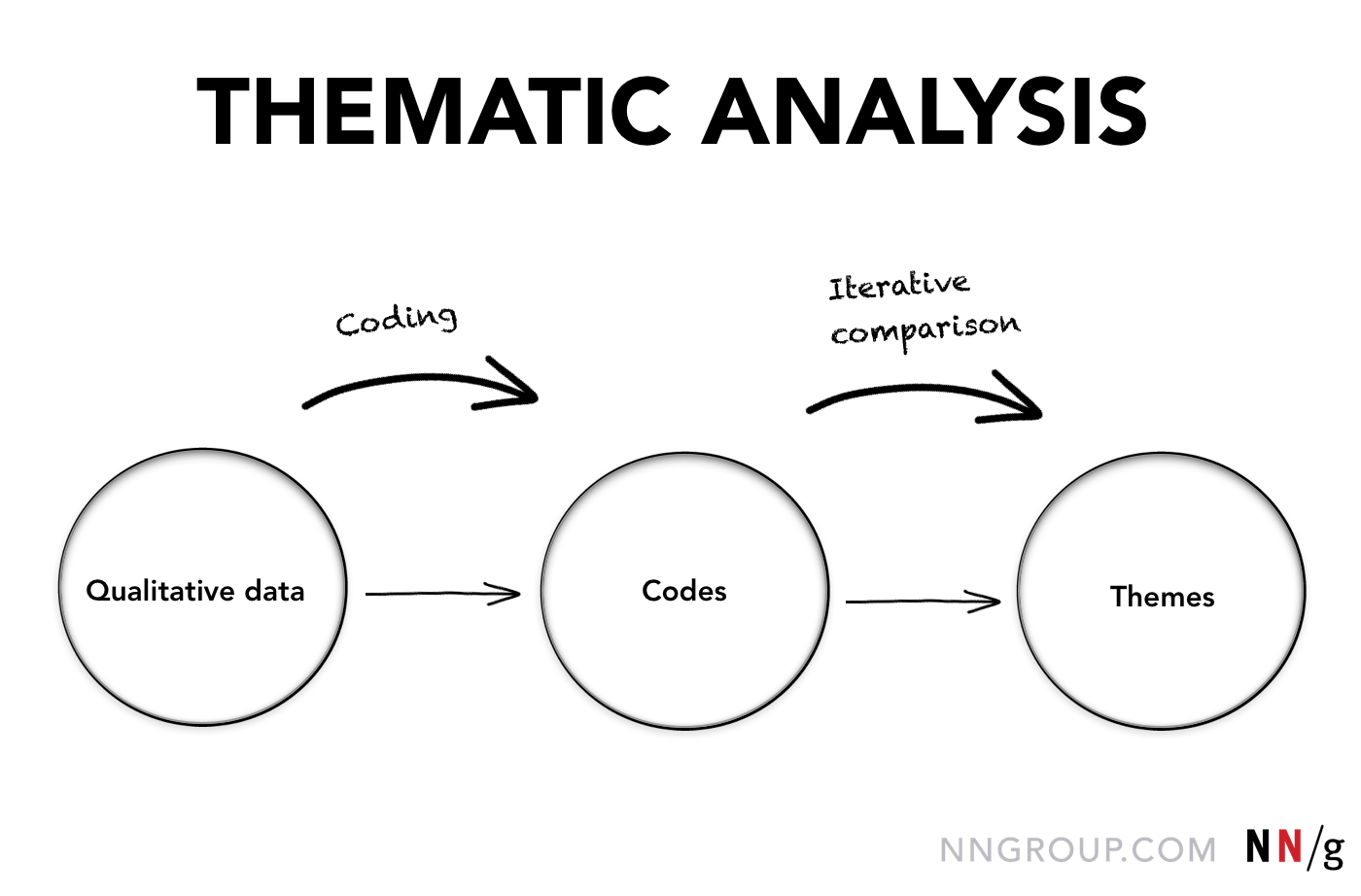
Definitie: Thematische analyse is een systematische methode om rijke gegevens uit kwalitatief onderzoek op te splitsen en te organiseren door individuele observaties en citaten te labelen met passende codes, om de ontdekking van significante thema’s te vergemakkelijken.
Zoals de naam al aangeeft, gaat het bij een thematische analyse om het vinden van thema’s.
Definitie: Een thema:
- is een beschrijving van een overtuiging, praktijk, behoefte, of een ander fenomeen dat uit de gegevens wordt ontdekt
- ontstaat wanneer gerelateerde bevindingen meerdere keren voorkomen bij deelnemers of gegevensbronnen
Uitdagingen bij het analyseren van kwalitatieve gegevens
Veel onderzoekers voelen zich overweldigd door kwalitatieve gegevens uit verkennend onderzoek dat in de vroege stadia van een project wordt uitgevoerd. De tabel hieronder belicht enkele veel voorkomende uitdagingen en daaruit voortvloeiende problemen.
| CHALLENGES | RESULTING ISSUES |
|
Large quantity of data: Qualitative research results in long transcripts and extensive field notes that can be time-consuming to read; you may have a hard time seeing patterns and remembering what’s important. |
Superficial analysis: Analysis is often done very superficially, just skimming topics, focusing on only memorable events and quotes, and missing large sections of notes. |
|
Rich data: There are lots of detail within every sentence or paragraph. It can be hard to see which details are useful and which are superfluous. |
Analysis becomes a description of many details: The analysis simply becomes a regurgitation of what participants’ may have said or done, without any analytical thinking applied to it. |
|
Contradicting data: Soms bevatten de gegevens van verschillende deelnemers of zelfs van dezelfde deelnemer tegenstrijdigheden waar onderzoekers wijs uit moeten worden. |
Vindingen zijn niet definitief: De analyse is niet definitief omdat de feedback van de deelnemers tegenstrijdig is, of erger nog, gezichtspunten die niet passen in de overtuiging van de onderzoeker worden genegeerd. |
Geen doelen gesteld voor de analyse: De doelstellingen van de aanvankelijke gegevensverzameling gaan verloren omdat onderzoekers gemakkelijk te veel opgaan in de details. | Verspilde tijd en verkeerd gerichte analyse: De analyse mist focus en het onderzoek rapporteert over de verkeerde dingen. |
Zonder een vorm van systematisch proces ontstaan de geschetste problemen gemakkelijk bij het analyseren van kwalitatieve data. Thematische analyse houdt onderzoekers georganiseerd en gefocust en geeft hen een algemeen proces om te volgen bij het analyseren van kwalitatieve gegevens.
Tools and Methods for Conducting Thematic Analysis
Een thematische analyse kan op veel verschillende manieren worden uitgevoerd. De beste tool of methode voor dit proces wordt bepaald op basis van de:
- data
- context en beperkingen van de data-analyse fase
- de persoonlijke werkstijl van de onderzoeker
3 veelgebruikte methoden zijn onder andere:
- Gebruik van software
- Journaling
- Gebruik van affinity diagramming technieken
Gebruik van software
Om grote hoeveelheden kwalitatieve data te analyseren, gebruiken kwalitatieve onderzoekers vaak software, bekend als CAQDAS (Computer-Aided Qualitative-Data-Analysis software) – spreek uit als “cak∙das”. Onderzoekers uploaden transcripten en veldnotities in een softwareprogramma en analyseren de tekst vervolgens systematisch door middel van formele codering. De software helpt bij het ontdekken van thema’s door verschillende visualisatiehulpmiddelen aan te bieden, zoals woordbomen of woordwolken, waarmee de gecodeerde gegevens op veel verschillende manieren kunnen worden gemanipuleerd.
Voordelen
- De analyse is zeer grondig.
- Een fysiek projectbestand (dat de ruwe gegevens en de analyse bevat) kan met anderen worden gedeeld. (Deze methode is populair bij studentenprojecten aan academische instellingen.)
Tegenvallers
- Tijdrovend, omdat het resulteert in veel codes die moeten worden gecondenseerd tot een kleine,
- Dure
- Moeilijk om met anderen synchroon te analyseren
- Vereist enige kennis van de software
- Kan beperkend aanvoelen
Journaling
Het opschrijven van gedachteprocessen en ideeën die je hebt over een tekst is gebruikelijk onder onderzoekers die grounded-theory methodologie beoefenen. Journaling as a form of thematic analysis is based on this methodology and involves manual annotation and highlighting of the data, followed by writing down the researchers’ ideas and thought processes. The notes are known as memos (not to be confused with the office memo delivering news to employees).
Benefits
- The process encourages reflection through the writing of detailed notes.
- Researchers have a record of how they arrived at their themes.
- The analysis is cheap and flexible.
Drawbacks
- Hard to do collaboratively
Affinity-Diagramming Techniques
The data is highlighted, cut out physically or digitally, and reassembled into meaningful groups until themes emerge on a physical or digital board. (See a video demonstrating affinity-diagramming.)
Benefits
- Can be done collaboratively
- Quick arriving at themes
- Cheap and flexible
- Visual, en ondersteunt een iteratief-analyseproces
Tegenvallers
- Niet zo grondig als andere methoden, omdat vaak segmenten tekst niet meerdere keren worden gecodeerd
- Hard om te doen als de data erg gevarieerd is, of als er veel gegevens zijn
Codes en codering
Alle methoden van thematische analyse veronderstellen enige mate van codering (niet te verwarren met het schrijven van een programma in een programmeertaal).
Definitie: Een code is een woord of zin die fungeert als een label voor een segment van de tekst.
Een code beschrijft waar de tekst over gaat en is een steno voor meer ingewikkelde informatie. (Een goede analogie is dat een code gegevens beschrijft zoals een trefwoord een artikel beschrijft of zoals een hashtag een tweet beschrijft). Vaak hebben kwalitatieve onderzoekers niet alleen een naam voor elke code, maar ook een beschrijving van wat de code betekent en voorbeelden van teksten die wel of niet bij de code passen. Deze beschrijvingen en voorbeelden zijn vooral nuttig als meer dan één persoon verantwoordelijk is voor het coderen van de gegevens of als het coderen over een langere periode wordt gedaan.
Definitie: Codering verwijst naar het proces van het labelen van segmenten van tekst met de juiste codes.
Als codes eenmaal zijn toegewezen, is het gemakkelijk om segmenten van tekst die over hetzelfde gaan te identificeren en te vergelijken. De codes stellen ons in staat informatie gemakkelijk te sorteren en gegevens te analyseren om overeenkomsten, verschillen en relaties tussen segmenten aan het licht te brengen. Zo kunnen we tot een begrip van de essentiële thema’s komen.
Code Types: Beschrijvend en interpreterend
Codes kunnen zijn:
- Beschrijvend: Ze beschrijven waar de gegevens over gaan
- Interpretatief: Ze zijn een analytische lezing van de data, waarbij de interpretatieve lens van de onderzoeker wordt toegevoegd.
Om voorbeelden van beschrijvende en interpretatieve codes te zien, laten we eens kijken naar een citaat uit een interview dat ik eerder dit jaar heb afgenomen met een UX-beoefenaar (als onderdeel van ons UX Careers onderzoek, dat zal worden gepubliceerd in ons UX Careers rapport).
“Ik was versteend over het faciliteren van een vergadering en mijn bedrijf bood een anderhalve dag durende cursus aan. Dus ik ging erheen en de instructeur deed iets wat ik toen verschrikkelijk vond, maar sindsdien ben ik het echt gaan waarderen. Het eerste wat we deden was een vel papier invullen met onze naam en onze ergste angst opschrijven om te modereren of te faciliteren en we leverden het in en toen zei hij, oké, morgen gaan jullie deze situatie uitbeelden (…) de volgende dag kwamen we terug en ik verliet de kamer terwijl de rest van het team las, zij lazen mijn ergste angst, bedachten hoe ze het zouden uitbeelden, en dan liep ik naar binnen en faciliteerde gedurende 10 minuten met dat. En dat heeft me echt geholpen om te beseffen dat er niets is om bang voor te zijn, dat onze angsten meestal in ons hoofd zitten en als ik daarmee werd geconfronteerd, besefte ik dat ik deze situaties aankan.”
Hierboven staan mogelijke beschrijvende en interpreterende codes voor de tekst:
Descriptieve code: hoe vaardigheden worden verworven
Redenering achter het codenaam: De deelnemers werd gevraagd te beschrijven hoe zij ertoe kwamen bepaalde vaardigheden te bezitten.
Interpretatieve code: zelfreflectie
Redenering achter het codelabel: De deelnemer beschrijft hoe deze ervaring haar opvattingen over faciliteren veranderde en hoe ze reflecteerde op haar angst.
Stappen om een thematische analyse uit te voeren
Of je nu een tool gebruikt (software, journaling, of affiniteitsdiagrammen), het uitvoeren van een thematische analyse kan worden onderverdeeld in 6 stappen.
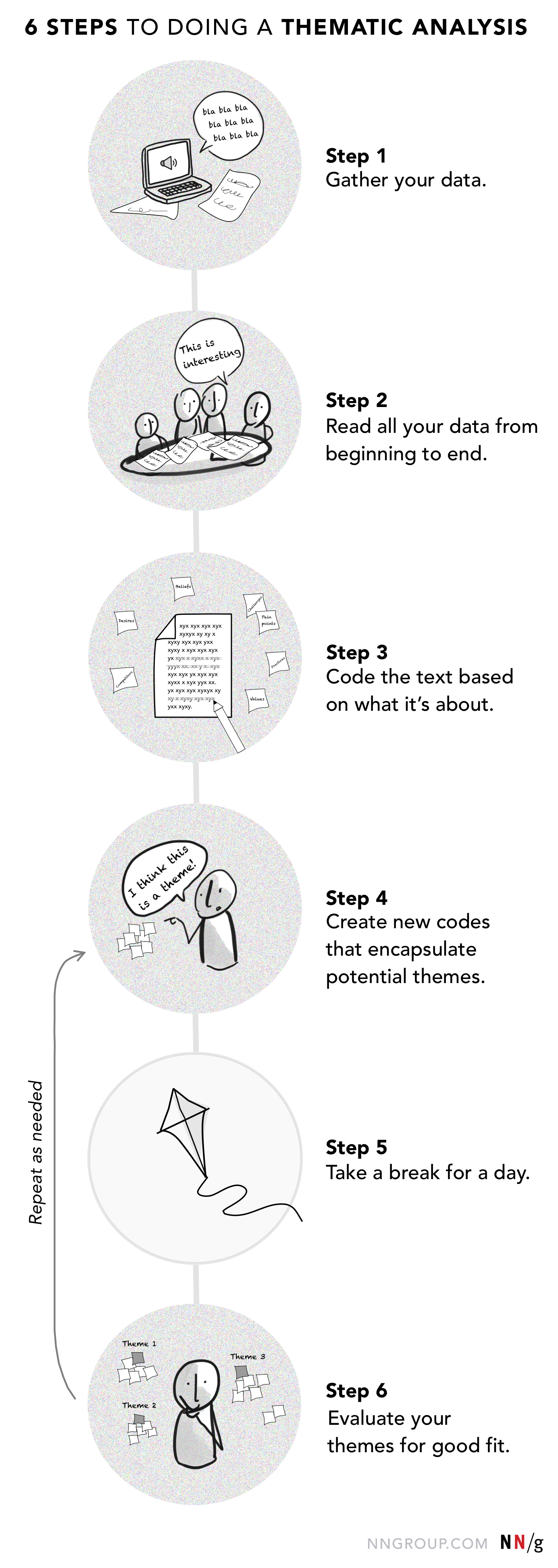
Stap 1: Verzamel al uw gegevens
Begin met de ruwe gegevens, zoals de transcripties van interviews of focusgroepen, veldnotities of dagboekaantekeningen. Ik heb aangeraden de geluidsopnamen van interviews te transcriberen en de transcripties te gebruiken voor de analyse in plaats van te vertrouwen op een gebrekkig geheugen.
Stap 2: Lees al uw gegevens van begin tot eind
Wees vertrouwd met de gegevens voordat u met de analyse begint, zelfs als u degene was die het onderzoek uitvoerde. Lees al uw transcripties, veldnotities en andere gegevensbronnen voordat u ze analyseert. In deze fase kunt u uw team bij het project betrekken. Door je team erbij te betrekken krijg je kennis van gebruikers en empathie voor hen en hun behoeften.
Run een workshop (of een serie workshops als je team erg groot is of als je veel gegevens hebt). Volg deze stappen:
- Voordat je teamleden met de data aan de slag gaan, schrijf je je onderzoeksvragen op een whiteboard of flip-over papier, zodat je de vragen tijdens het werk makkelijk kunt terugvinden.
- Geef elk lid een transcript of één veld- of dagboekaantekening. Zeg dat ze alles wat ze belangrijk vinden moeten markeren.
- Als de teamleden klaar zijn met het lezen van hun aantekeningen, kunnen ze hun transcript of aantekening aan iemand anders geven en krijgen ze een nieuwe van een ander teamlid. Deze stap wordt herhaald totdat alle teamleden zich met alle gegevens hebben beziggehouden.
- Bespreek als groep wat je is opgevallen of verrassend vond.

Hoewel het het beste is als je team al je onderzoekssessies observeert, is dat misschien niet mogelijk als je veel sessies hebt of een groot team. Wanneer individuele teamleden slechts een handvol sessies observeren, komen ze soms weg met een onvolledig begrip van de bevindingen. De workshop kan dat probleem oplossen, omdat iedereen alle sessietranscripten zal lezen.
Stap 3: Codeer de tekst op basis van waar het over gaat
In de coderingsstap moeten gemarkeerde secties worden gecategoriseerd, zodat de gemarkeerde secties gemakkelijk kunnen worden vergeleken.
Houd uzelf in dit stadium aan uw onderzoeksdoelstellingen. Print uw onderzoeksvragen uit. Hang ze op aan de muur of op een whiteboard in de ruimte waar u de analyse uitvoert.
Als u voldoende tijd hebt, kunt u uw team bij deze eerste coderingsstap betrekken. Als de tijd beperkt is en er veel gegevens zijn om door te werken, doe deze stap dan alleen en nodig uw team later uit om uw codes te bekijken en de thema’s verder uit te werken.
Tijdens het coderen bekijkt u elk tekstfragment en vraagt u zich af: “Waar gaat dit over?” Geef het fragment een naam die de gegevens beschrijft (een beschrijvende code). U kunt in dit stadium ook interpreterende codes aan de tekst toevoegen.
De code kan worden gemaakt voor of nadat u de gegevens hebt gegroepeerd. In de volgende twee paragrafen van deze stap wordt beschreven hoe en wanneer u de codes kunt toevoegen.
Traditionele methode: Codes maken voor het groeperen
In de traditionele methode markeert u segmenten van de gegevens, zoals zinnen, alinea’s en zinsdelen, en codeert u deze. Het is nuttig om een lijst bij te houden van alle gebruikte codes en aan te geven wat ze zijn, zodat u naar deze lijst kunt verwijzen bij het coderen van andere delen van de tekst (vooral als meerdere mensen de tekst coderen). Op deze manier voorkomt u dat u meerdere codes voor hetzelfde soort kwestie maakt (die later moeten worden geconsolideerd).
Als alle tekst is gecodeerd, kunt u alle gegevens groeperen die dezelfde code hebben.
Als u CAQDAS voor dit proces gebruikt, registreert de software automatisch de codes die u tijdens het coderen toewijst, zodat u ze opnieuw kunt gebruiken. Vervolgens kunt u alle tekst bekijken die met dezelfde code is gecodeerd.
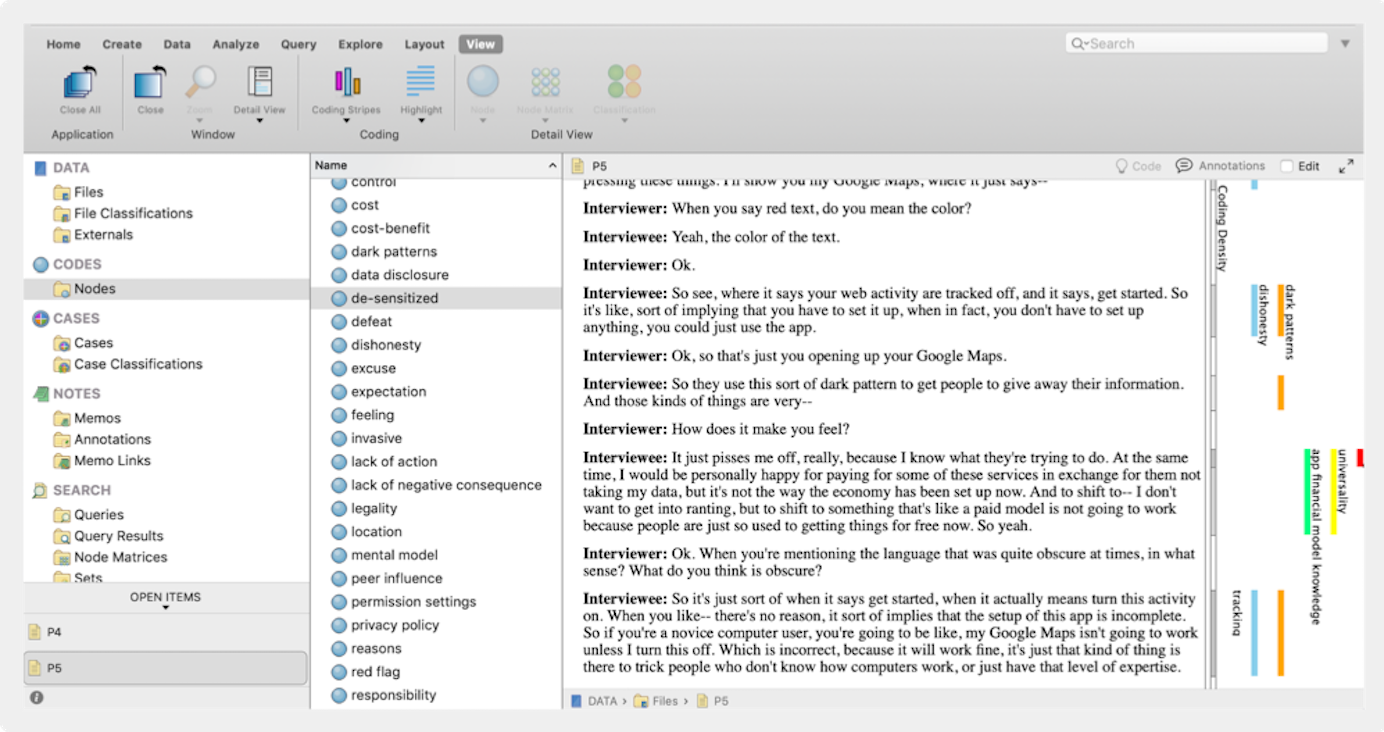
Snelle methode: Groepeer tekstsegmenten en wijs vervolgens een code toe
In plaats van een code te bedenken wanneer u tekst markeert, knipt u (fysiek of digitaal) alle gemarkeerde segmenten die op elkaar lijken in stukken en groepeert deze (vergelijkbaar met de manier waarop verschillende stickies in een affiniteitskaart kunnen worden gegroepeerd). De groeperingen krijgen dan een code. Als je de groepering digitaal doet, kun je de gecodeerde secties in een nieuw document of een visueel samenwerkingsplatform plaatsen.
In de foto’s hieronder is de groepering handmatig gedaan. De transcripten werden in stukken geknipt, op stickies geplakt en rond het bord geschoven tot ze in natuurlijke onderwerpsgroepen vielen. De onderzoeker gaf vervolgens een roze sticky met een beschrijvende code aan de groepering.


Aan het eind van deze stap moet u gegevens hebben gegroepeerd per onderwerp en codes voor elk onderwerp.
Laten we eens naar een voorbeeld kijken. Ik heb 3 mensen geïnterviewd over hun ervaring met thuis koken. In deze interviews spraken de deelnemers over hoe ze ervoor kozen bepaalde dingen wel en andere niet te koken. Ze spraken over specifieke uitdagingen waarmee ze werden geconfronteerd tijdens het koken (bijv,
Na het groeperen van de gemarkeerde knipsels uit mijn interviews per onderwerp, kwam ik uit op 3 brede beschrijvende codes en bijbehorende groeperingen:
- Kookervaringen: memorabele positieve en negatieve ervaringen met betrekking tot koken
- Pijnpunten: alles wat iemand ervan weerhoudt om te koken of wat koken moeilijk maakt (inclusief het navigeren door dieetbeperkingen, beperkte budgetten, etc.)
- Kookervaringen: memorabele positieve en negatieve ervaringen met betrekking tot koken
- Pijnpunten: alles wat iemand ervan weerhoudt om te koken of wat koken moeilijk maakt (inclusief het navigeren door dieetbeperkingen, beperkte budgetten, etc.)Dingen die helpen: wat iemand helpt (of waarvan men denkt dat het mogelijk helpt) om specifieke uitdagingen of pijnpunten te overwinnen
Stap 4: Creëer nieuwe codes die potentiële thema’s omvatten
Bekijk alle codes en onderzoek causale verbanden, overeenkomsten, verschillen of tegenstrijdigheden om te zien of u onderliggende thema’s kunt blootleggen. Terwijl u dit doet, zullen sommige codes terzijde worden geschoven (ofwel gearchiveerd of verwijderd) en zullen nieuwe interpretatieve codes worden gecreëerd. Als u een fysieke methode gebruikt, zoals besproken in stap 3, kunnen sommige van deze aanvankelijke groeperingen in elkaar storten of uitdijen terwijl u naar thema’s zoekt.
Stel uzelf de volgende vragen:
- Wat is er aan de hand in elke groep?
- Hoe zijn deze codes met elkaar verbonden?
- Hoe hangen deze samen met mijn onderzoeksvragen?
Terugkomend op ons kookonderwerp, bij het analyseren van de tekst binnen elke groepering en het zoeken naar verbanden tussen de gegevens, viel het me op dat twee deelnemers zeiden dat ze hielden van ingrediënten die op verschillende manieren kunnen worden bereid en goed samengaan met andere verschillende ingrediënten. Een derde deelnemer zei dat ze liever een set ingrediënten had die ze voor veel verschillende maaltijden in de week kon gebruiken, dan dat ze voor elk maaltijdplan aparte ingrediënten moest kopen. Zo ontstond een nieuw thema over de flexibiliteit van ingrediënten. Voor dit thema bedacht ik de code one ingredient fits all, waarvoor ik vervolgens een gedetailleerde beschrijving schreef.

Stap 5: Neem een dag pauze en keer dan terug naar de gegevens
Het is bijna altijd een goed idee om een pauze te nemen en met een frisse blik naar de gegevens terug te keren. Dat helpt u soms om belangrijke patronen in de gegevens duidelijk te zien en er baanbrekende inzichten uit af te leiden.
Stap 6: Evalueer uw thema’s op geschiktheid
In deze stap kan het nuttig zijn om anderen te vragen u te helpen uw codes en opkomende thema’s te beoordelen. Niet alleen worden zo nieuwe inzichten verkregen, maar ook kunnen uw conclusies met frisse ogen worden bekeken en bekritiseerd. Deze werkwijze vermindert de kans dat uw interpretatie wordt gekleurd door persoonlijke vooroordelen.
Peil uw thema’s. Stel uzelf de volgende vragen:
- Wordt het thema goed ondersteund door de gegevens? Of kun je gegevens vinden die je thema niet ondersteunen?
- Is het thema verzadigd met veel instanties?
- Zijn anderen het eens met de thema’s die je in de gegevens hebt gevonden nadat je de gegevens afzonderlijk hebt geanalyseerd?
Als het antwoord op deze vragen nee is, kan dat betekenen dat je terug moet naar de analyseraad. Ervan uitgaande dat je goede gegevens hebt verzameld, valt er bijna altijd wel iets te leren, dus meer tijd met je team besteden aan het herhalen van de stappen 4-6 is de moeite waard.
Conclusie
Gebruik thematische analyse als een handige gids voor het efficiënt doorworstelen van veel kwalitatieve gegevens. Er is niet één manier om een thematische analyse uit te voeren. Kies een analysemethode die past bij het soort en de hoeveelheid gegevens die je hebt verzameld. Nodig waar mogelijk anderen uit in het analyseproces om zowel de nauwkeurigheid van de analyse als de kennis van uw team over het gedrag, de motivaties en de behoeften van uw gebruikers te vergroten. Analyse kan een langdurig proces zijn, dus een goede vuistregel is om net zoveel tijd te budgetteren als u had voor het verzamelen van de gegevens om de analyse te voltooien.
Lees meer: User Interviews, Geavanceerde technieken om waarden, motivaties en verlangens bloot te leggen, een cursus van een hele dag op de UX Conference.