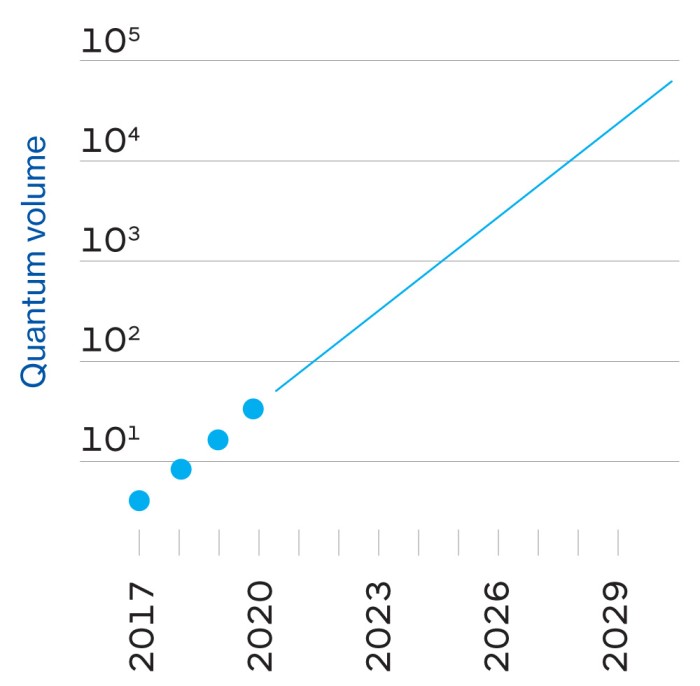
Late October passado, Google anunciou que um desses chips, chamado Sycamore, tinha se tornado o primeiro a demonstrar “supremacia quântica” ao realizar uma tarefa que seria praticamente impossível em uma máquina clássica. Com apenas 53 qubits, o Sycamore completou um cálculo em poucos minutos que, segundo o Google, teria levado o supercomputador existente mais poderoso do mundo, o Summit, 10.000 anos. O Google tocou nisso como um grande avanço, comparando-o ao lançamento do Sputnik ou ao primeiro vôo dos irmãos Wright – o limiar de uma nova era de máquinas que faria o computador mais poderoso de hoje parecer um ábaco.
Em uma conferência de imprensa no laboratório em Santa Bárbara, a equipe do Google colocou alegremente perguntas de jornalistas durante quase três horas. Mas o seu bom humor não conseguia mascarar uma tensão subjacente. Dois dias antes, pesquisadores da IBM, principal rival do Google em computação quântica, haviam torpedeado sua grande revelação. Eles tinham publicado um jornal que essencialmente acusava os Googlers de errar suas somas. A IBM achava que teria levado apenas dias, não milênios, para replicar o que o Sycamore tinha feito. Quando perguntado o que ele achava do resultado da IBM, Hartmut Neven, o chefe da equipe do Google, evitou, pontualmente, dar uma resposta direta.

Poderia descartar isto como apenas uma discussão académica – e de certa forma foi. Mesmo se a IBM estivesse certa, Sycamore ainda assim tinha feito o cálculo mil vezes mais rápido do que Summit teria feito. E provavelmente seriam apenas meses até que o Google construísse uma máquina quântica ligeiramente maior que provasse o ponto sem dúvida.
A objecção mais profunda da IBM, no entanto, não era que a experiência do Google fosse menos bem sucedida do que se alegava, mas que era um teste sem sentido, em primeiro lugar. Ao contrário da maioria do mundo da computação quântica, a IBM não acha que “supremacia quântica” seja o momento dos irmãos Wright da tecnologia; na verdade, nem sequer acredita que haverá tal momento.
IBM está, em vez disso, perseguindo uma medida muito diferente de sucesso, algo a que chama de “vantagem quântica”. Isto não é uma mera diferença de palavras ou mesmo de ciência, mas uma postura filosófica com raízes na história, cultura e ambições da IBM – e, talvez, o fato de que durante oito anos suas receitas e lucros têm estado em declínio quase incessante, enquanto o Google e sua empresa mãe Alphabet apenas viram seus números crescer. Este contexto, e estes objectivos diferentes, podem influenciar o que – se um ou outro – vier à frente na corrida da computação quântica.
Mundos à parte
A curva elegante e arrebatadora do Centro de Investigação Thomas J. Watson da IBM nos subúrbios a norte de Nova Iorque, uma obra-prima neo-futurista do arquitecto finlandês Eero Saarinen, é um continente e um universo distante das escavações sem descrição da equipa do Google. Completada em 1961 com a bonança IBM feita a partir de mainframes, tem uma qualidade semelhante a um museu, um lembrete para todos os que trabalham dentro dela dos avanços da empresa em tudo, desde geometria fractal a supercondutores e inteligência artificial e computação quântica.
O chefe da divisão de pesquisa de 4.000 pessoas é Dario Gil, um espanhol cujo discurso rápido corre para acompanhar o seu zelo quase evangélico. Em ambas as vezes em que falei com ele, ele fez um barulho de marcos históricos com o objetivo de ressaltar há quanto tempo a IBM está envolvida em pesquisas relacionadas à computação quântica (ver linha do tempo à direita).


Uma grande experiência: Teoria e prática quântica
Um bloco básico do computador quântico é o bit quântico, ou qubit. Em um computador clássico, um bit pode armazenar um 0 ou um 1. Um qubit pode armazenar não apenas 0 ou 1, mas também um estado intermediário chamado superposição, que pode assumir muitos valores diferentes. Uma analogia é que se a informação fosse colorida, então um bit clássico poderia ser preto ou branco. Uma bit quando está em superposição pode ser qualquer cor no espectro, e também pode variar em brilho.
O resultado é que uma bit pode armazenar e processar uma grande quantidade de informação comparada com uma bit – e a capacidade aumenta exponencialmente à medida que você conecta qubits juntos. Armazenar todas as informações das 53 qubits no chip Sycamore do Google levaria cerca de 72 petabytes (72 bilhões de gigabytes) da memória clássica do computador. Não é preciso muito mais qubits antes que você precise de um computador clássico do tamanho do planeta.
Mas não é simples. Delicada e facilmente perturbada, as qubits precisam ser quase perfeitamente isoladas do calor, da vibração e dos átomos perdidos – veja o “candelabro” dos frigoríficos do laboratório quântico do Google. Mesmo assim, eles podem funcionar por no máximo algumas centenas de microssegundos antes de “decohere” e perder sua superposição.
E os computadores quânticos nem sempre são mais rápidos do que os clássicos. Eles são apenas diferentes, mais rápidos em algumas coisas e mais lentos em outras, e requerem diferentes tipos de software. Para comparar seu desempenho, você tem que escrever um programa clássico que simula aproximadamente o quantum one.
Para seu experimento, o Google escolheu um teste de benchmarking chamado “amostragem aleatória de circuitos quânticos”. Ele gera milhões de números aleatórios, mas com pequenos vieses estatísticos que são uma marca registrada do algoritmo quântico. Se Sycamore fosse uma calculadora de bolso, seria o equivalente a pressionar botões aleatoriamente e verificar se a tela mostrava os resultados esperados.
Google simulou partes disso em suas próprias fazendas de servidores massivos, bem como em Summit, o maior supercomputador do mundo, no Laboratório Nacional de Oak Ridge. Os pesquisadores estimaram que a conclusão de todo o trabalho, que levou Sycamore 200 segundos, teria levado Summit aproximadamente 10.000 anos. Voilà: quantum supremacy.
Então qual foi a objecção da IBM? Basicamente, que existem diferentes maneiras de conseguir um computador clássico para simular uma máquina quântica – e que o software que você escreve, a maneira como você corta os dados e os armazena, e o hardware que você usa fazem uma grande diferença na rapidez com que a simulação pode ser executada. A IBM disse que o Google assumiu que a simulação precisaria ser cortada em vários pedaços, mas Summit, com 280 petabytes de armazenamento, é grande o suficiente para manter o estado completo do Sycamore de uma só vez. (E a IBM construiu o Summit, então ela deve saber.)
Mas ao longo das décadas, a empresa ganhou a reputação de lutar para transformar seus projetos de pesquisa em sucessos comerciais. Tomemos, mais recentemente, Watson, o Jeopardy!-playing AI que a IBM tentou converter em um guru médico robô. O objetivo era fornecer diagnósticos e identificar tendências em oceanos de dados médicos, mas apesar das dezenas de parcerias com provedores de serviços de saúde, tem havido poucas aplicações comerciais, e até mesmo as que surgiram produziram resultados mistos.
A equipe de computação quântica, no relato de Gil, está tentando quebrar esse ciclo fazendo a pesquisa e o desenvolvimento de negócios em paralelo. Quase logo que teve computadores quânticos funcionando, começou a torná-los acessíveis a estranhos, colocando-os na nuvem, onde podem ser programados por meio de uma simples interface de arrastar e soltar que funciona em um navegador web. A “Experiência IBM Q”, lançada em 2016, consiste agora em 15 computadores quânticos disponíveis publicamente, que variam de cinco a 53 qubits em tamanho. Cerca de 12.000 pessoas por mês os utilizam, desde pesquisadores acadêmicos até crianças em idade escolar. O tempo nas máquinas menores é grátis; a IBM diz que já tem mais de 100 clientes pagando (não diz quanto) para usar as maiores.
Nenhum desses dispositivos – ou qualquer outro computador quântico do mundo, exceto o Sycamore do Google – ainda mostrou que pode bater uma máquina clássica em qualquer coisa. Para a IBM, essa não é a questão neste momento. Tornar as máquinas disponíveis online permite à empresa aprender o que futuros clientes podem precisar delas e permite que desenvolvedores de software externos aprendam como escrever código para elas. Isso, por sua vez, contribui para o seu desenvolvimento, tornando os computadores quânticos subsequentes melhores.
Este ciclo, a empresa acredita, é o caminho mais rápido para a sua chamada vantagem quântica, um futuro em que os computadores quânticos não deixarão necessariamente os clássicos no pó, mas farão algumas coisas úteis um pouco mais rápido ou com mais eficiência – o suficiente para torná-los economicamente rentáveis. Enquanto a supremacia quântica é um único marco, a vantagem quântica é um “contínuo”, dizem os IBMers – um mundo de possibilidades em expansão gradual.
Esta, então, é a grande teoria unificada de Gil sobre a IBM: que ao combinar sua herança, sua experiência técnica, o poder cerebral de outras pessoas e sua dedicação aos clientes empresariais, ele pode construir computadores quânticos úteis mais cedo e melhor do que qualquer outra pessoa.
Nesta visão das coisas, a IBM vê a demonstração de supremacia quântica do Google como “um truque de salão”, diz Scott Aaronson, um físico da Universidade do Texas em Austin, que contribuiu para os algoritmos quânticos que o Google está usando. Na melhor das hipóteses, é uma distração vistosa do trabalho real que precisa acontecer. Na pior das hipóteses, é enganador, porque pode fazer com que as pessoas pensem que os computadores quânticos podem vencer os clássicos em qualquer coisa e não numa tarefa muito restrita. “‘Supremacy’ é uma palavra inglesa que será impossível para o público não interpretar mal”, diz Gil.
p>Google, claro, vê isso de forma diferente.
Introduzir o upstart
Google era uma empresa precoce de oito anos quando começou a mexer com problemas quânticos em 2006, mas não formou um laboratório quântico dedicado até 2012 – o mesmo ano em que John Preskill, um físico da Caltech, cunhou o termo “supremacy quantum”.”
O chefe do laboratório é Hartmut Neven, um cientista informático alemão com uma presença imponente e uma inclinação para o chique estilo Burning Man; vi-o uma vez com um casaco azul peludo e outra vez com uma roupa toda de prata que o fazia parecer um astronauta grunhido. (“Minha esposa compra essas coisas para mim”, explicou ele). Inicialmente, Neven comprou uma máquina construída por uma firma externa, a D-Wave, e passou um tempo tentando alcançar a supremacia quântica sobre ela, mas sem sucesso. Ele diz que convenceu Larry Page, então CEO do Google, a investir na construção de computadores quânticos em 2014, prometendo-lhe que o Google aceitaria o desafio de Preskill: “Dissemos-lhe: ‘Ouve, Larry, daqui a três anos voltaremos e colocaremos na tua mesa um chip protótipo que possa, pelo menos, computar um problema que está para além das capacidades das máquinas clássicas'””
Desprovido dos conhecimentos quânticos da IBM, o Google contratou uma equipa de fora, liderada por John Martinis, um físico da Universidade da Califórnia, em Santa Bárbara. Martinis e seu grupo já estavam entre os melhores fabricantes de computadores quânticos do mundo – eles tinham conseguido juntar até nove qubits – e a promessa de Neven a Page parecia ser um objetivo digno de ser alcançado por eles.
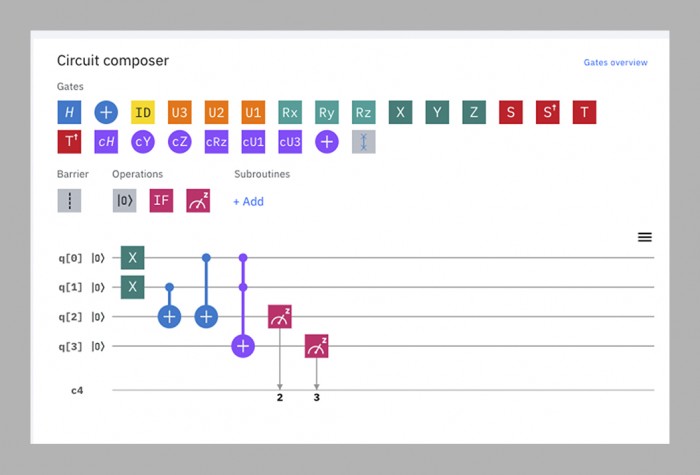
O prazo de três anos chegou e foi quando a equipa do Martinis lutou para fazer um chip suficientemente grande e estável para o desafio. Em 2018 o Google lançou o seu maior processador até agora, Bristlecone. Com 72 qubits, ele estava bem à frente de qualquer coisa que seus rivais tivessem feito, e Martinis previu que iria alcançar a supremacia quântica nesse mesmo ano. Mas alguns dos membros da equipa tinham estado a trabalhar em paralelo numa arquitectura de chips diferente, chamada Sycamore, que acabou por se revelar capaz de fazer mais com menos qubits. Assim, era um chip de 53 qubits -originalmente 54, mas um deles não funcionava bem – que acabou por demonstrar supremacia no outono passado.
Para fins práticos, o programa usado nessa demonstração é virtualmente inútil – ele gera números aleatórios, o que não é algo para o qual você precisa de um computador quântico. Mas ele os gera de uma forma particular que um computador clássico acharia muito difícil de replicar, estabelecendo assim a prova de conceito (ver página oposta).
Ask IBMers o que eles pensam dessa conquista, e você fica com uma aparência dolorosa. “Eu não gosto da palavra , e não gosto das implicações”, diz Jay Gambetta, um australiano cauteloso que lidera a equipe quântica da IBM. O problema, diz ele, é que é virtualmente impossível prever se algum cálculo quântico será difícil para uma máquina clássica, então mostrá-lo em um caso não ajuda a encontrar outros casos.
Para todos com quem falei fora da IBM, esta recusa em tratar a supremacia quântica como sendo uma parte significativa da cabeça de porco. “Qualquer pessoa que tenha uma oferta comercialmente relevante – eles têm que mostrar supremacia primeiro. Eu acho que isso é apenas lógica básica”, diz Neven. Até mesmo Will Oliver, um físico do MIT com um pouco de educação, que tem sido um dos observadores mais equilibrados da discussão, diz: “É um marco muito importante mostrar um computador quântico superando um computador clássico em alguma tarefa, seja ela qual for”
O salto quântico
Independentemente de você concordar com a posição do Google ou da IBM, o próximo objetivo é claro, diz Oliver: construir um computador quântico que possa fazer algo útil. A esperança é que tais máquinas possam um dia resolver problemas que requerem quantidades impraticáveis de poder de computação de força bruta agora, como modelar moléculas complexas para ajudar a descobrir novas drogas e materiais, ou otimizar os fluxos de tráfego da cidade em tempo real para reduzir o congestionamento, ou fazer previsões meteorológicas a longo prazo. (Eventualmente eles podem ser capazes de quebrar os códigos criptográficos usados hoje em dia para garantir comunicações e transações financeiras, embora até lá a maior parte do mundo já tenha provavelmente adotado a criptografia quântica-resistente). O problema é que é quase impossível prever qual será a primeira tarefa útil, ou qual será o tamanho de um computador para realizá-la.
Essa incerteza tem a ver tanto com hardware como com software. No lado do hardware, o Google calcula que seus projetos atuais de chips podem levá-lo a algum lugar entre 100 e 1.000 desistências. No entanto, assim como o desempenho de um carro não depende apenas do tamanho do motor, o desempenho de um computador quântico não é simplesmente determinado pelo seu número de qubits. Há uma série de outros factores a ter em conta, incluindo quanto tempo podem ser impedidos de descodificar, a sua propensão para erros, a rapidez com que operam e a forma como estão interligados. Isto significa que qualquer computador quântico operando hoje em dia atinge apenas uma fração do seu potencial total.
Software para computadores quânticos, entretanto, está tanto em sua infância quanto as próprias máquinas. Na computação clássica, as linguagens de programação são agora vários níveis removidos do “código de máquina” bruto que os primeiros desenvolvedores de software tinham que usar, porque a mesquinhez de como os dados são armazenados, processados e desviados já está padronizada. “Em um computador clássico, quando se programa, não é preciso saber como funciona um transistor”, diz Dave Bacon, que lidera o esforço de software da equipe do Google. O código quântico, por outro lado, tem de ser altamente adaptado às qubits em que vai funcionar, de modo a tirar o máximo partido do seu desempenho temperamental. Isso significa que o código para os chips da IBM não funcionará com os de outras empresas, e mesmo as técnicas para otimizar o Sycamore de 53-qubit do Google não necessariamente funcionarão bem em seu futuro irmão de 100-qubit. Mais importante, isso significa que ninguém pode prever o quão difícil um problema esses 100 qubits serão capazes de resolver.
O mais que alguém ousa esperar é que os computadores com algumas centenas de qubits serão enganados a simular alguma química moderadamente complexa nos próximos anos – talvez até o suficiente para avançar a busca por um novo medicamento ou uma bateria mais eficiente. No entanto, a decoherence e os erros trarão todas estas máquinas a uma parada antes que eles possam fazer qualquer coisa realmente difícil como quebrar a criptografia.
Para construir um computador quântico com a potência de 1.000 qubits, você precisaria de um milhão de qubits reais.
Isso exigirá um computador quântico “tolerante a falhas”, que possa compensar os erros e manter-se em funcionamento indefinidamente, tal como os clássicos. A solução esperada será criar redundância: fazer com que centenas de qubits atuem como um só, em um estado quântico compartilhado. Coletivamente, eles podem corrigir os erros de qubits individuais. E como cada qubit sucumbe à decoherence, seus vizinhos o trarão de volta à vida, em um ciclo interminável de ressuscitação mútua.
A previsão típica é que seriam necessárias até 1.000 qubits conjuntos para atingir essa estabilidade – significando que para construir um computador com o poder de 1.000 qubits, você precisaria de um milhão de qubits reais. O Google estima “conservadoramente” que pode construir um processador de um milhão de qubits dentro de 10 anos, Neven diz, embora existam alguns grandes obstáculos técnicos a ultrapassar, incluindo um em que a IBM pode ainda ter vantagem sobre o Google (ver página oposta).
Por esse tempo, muita coisa pode ter mudado. Os supercondutores que o Google e a IBM usam atualmente podem ser os tubos de vácuo da sua época, substituídos por algo muito mais estável e confiável. Pesquisadores ao redor do mundo estão experimentando vários métodos de fazer qubits, embora poucos sejam avançados o suficiente para construir computadores funcionais. Startups rival como Rigetti, IonQ ou Quantum Circuits podem desenvolver uma vantagem em uma técnica particular e saltar as maiores empresas.
Uma história de duas transmissões
As qubits de transmissão do Google e da IBM são quase idênticas, com uma pequena mas potencialmente crucial diferença.
Nos computadores quânticos do Google e da IBM, as qubits em si são controladas por pulsos de microondas. Pequenos defeitos de fabricação significam que não há duas qubits que respondam a pulsos exatamente da mesma freqüência. Há duas soluções para isso: variar a frequência dos pulsos para encontrar o ponto doce de cada qubit, como sacudir uma chave mal cortada em uma fechadura até abrir; ou usar campos magnéticos para “afinar” cada qubit para a frequência certa.
IBM usa o primeiro método; o Google usa o segundo. Cada abordagem tem valias e máculas. As qubits sintonizáveis do Google funcionam mais rápido e mais precisamente, mas são menos estáveis e requerem mais circuitos. As qubits de frequência fixa da IBM são mais estáveis e mais simples, mas rodam mais lentamente.
Do ponto de vista técnico, é praticamente um toss-up, pelo menos nesta fase. Em termos de filosofia corporativa, no entanto, é a diferença entre o Google e a IBM em poucas palavras – ou melhor, em um qubit.
Google escolheu ser ágil. “Em geral nossa filosofia vai um pouco mais para uma maior controlabilidade em detrimento dos números que as pessoas normalmente procuram”, diz Hartmut Neven.
IBM, por outro lado, optou pela confiabilidade. “Há uma enorme diferença entre fazer uma experiência de laboratório e publicar um artigo, e colocar um sistema com, tipo, 98% de confiabilidade onde você pode executá-lo o tempo todo”, diz Dario Gil.
Direito agora, o Google tem a vantagem. No entanto, à medida que as máquinas vão ficando maiores, a vantagem pode virar para a IBM. Cada qubit é controlado por seus próprios fios individuais; um qubit sintonizável requer um fio extra. A IBM diz que esta é uma das razões pelas quais eles optaram pelo qubit de frequência fixa. Martinis, o chefe da equipa do Google, diz que passou pessoalmente os últimos três anos a tentar encontrar soluções de cablagem. “É um problema tão importante que eu trabalhei nele”, brinca ele.
Mas dado o seu tamanho e riqueza, tanto o Google como a IBM têm uma chance de se tornarem jogadores sérios no negócio da computação quântica. As empresas vão alugar as suas máquinas para resolver problemas da forma como alugam actualmente o armazenamento e o poder de processamento de dados baseado na nuvem da Amazon, Google, IBM ou Microsoft. E o que começou como uma batalha entre físicos e cientistas da computação vai evoluir para um concurso entre divisões de serviços empresariais e departamentos de marketing.
Qual é a empresa melhor colocada para ganhar esse concurso? A IBM, com suas receitas em declínio, pode ter um senso de urgência maior do que o Google. Ela sabe por experiência amarga os custos de ser lento a entrar num mercado: no verão passado, em sua compra mais cara de todos os tempos, ela forçou mais de US$ 34 bilhões para a Red Hat, um provedor de serviços em nuvem de código aberto, numa tentativa de alcançar a Amazon e a Microsoft nesse campo e reverter suas fortunas financeiras. Sua estratégia de colocar suas máquinas quânticas na nuvem e construir um negócio pago desde o início parece ter sido projetada para lhe dar um avanço.
Google recentemente começou a seguir o exemplo da IBM, e seus clientes comerciais agora incluem o Departamento de Energia dos EUA, Volkswagen, e Daimler. A razão pela qual não o fez mais cedo, diz Martinis, é simples: “Não tínhamos os recursos para o colocar na nuvem.” Mas essa é outra forma de dizer que teve o luxo de não ter que fazer do desenvolvimento de negócios uma prioridade.
Se essa decisão dá à IBM uma vantagem é muito cedo para dizer, mas provavelmente mais importante será como as duas empresas aplicarão seus outros pontos fortes ao problema nos próximos anos. A IBM, diz Gil, se beneficiará de sua experiência “full stack” em tudo, desde a ciência dos materiais e fabricação de chips até o atendimento de grandes clientes corporativos. O Google, por outro lado, pode ostentar uma cultura de inovação ao estilo do Vale do Silício e muita prática na rápida ampliação das operações.
Como para a própria supremacia quântica, será um momento importante na história, mas isso não significa que será um momento decisivo. After all, everyone knows about the Wright brothers’ first flight, but can anybody remember what they did afterwards?
Sign inSubscribe now