質的データからテーマを発見することは、気が遠くなるような困難なことです。 定量的な研究を要約することは比較的明確です:たとえば、競合より 25% 良いスコアを出したとします。
プロジェクトの初期段階では、探索的な研究が行われることがよくあります。 この調査では、多くの質的データが得られることが多く、それには次のようなものがあります。
ユーザーインタビュー、フォーカスグループ、さらには日記研究から得られた、人々の考え、信念、自己報告によるニーズなどの定性的な態度データ
質的な行動データです。
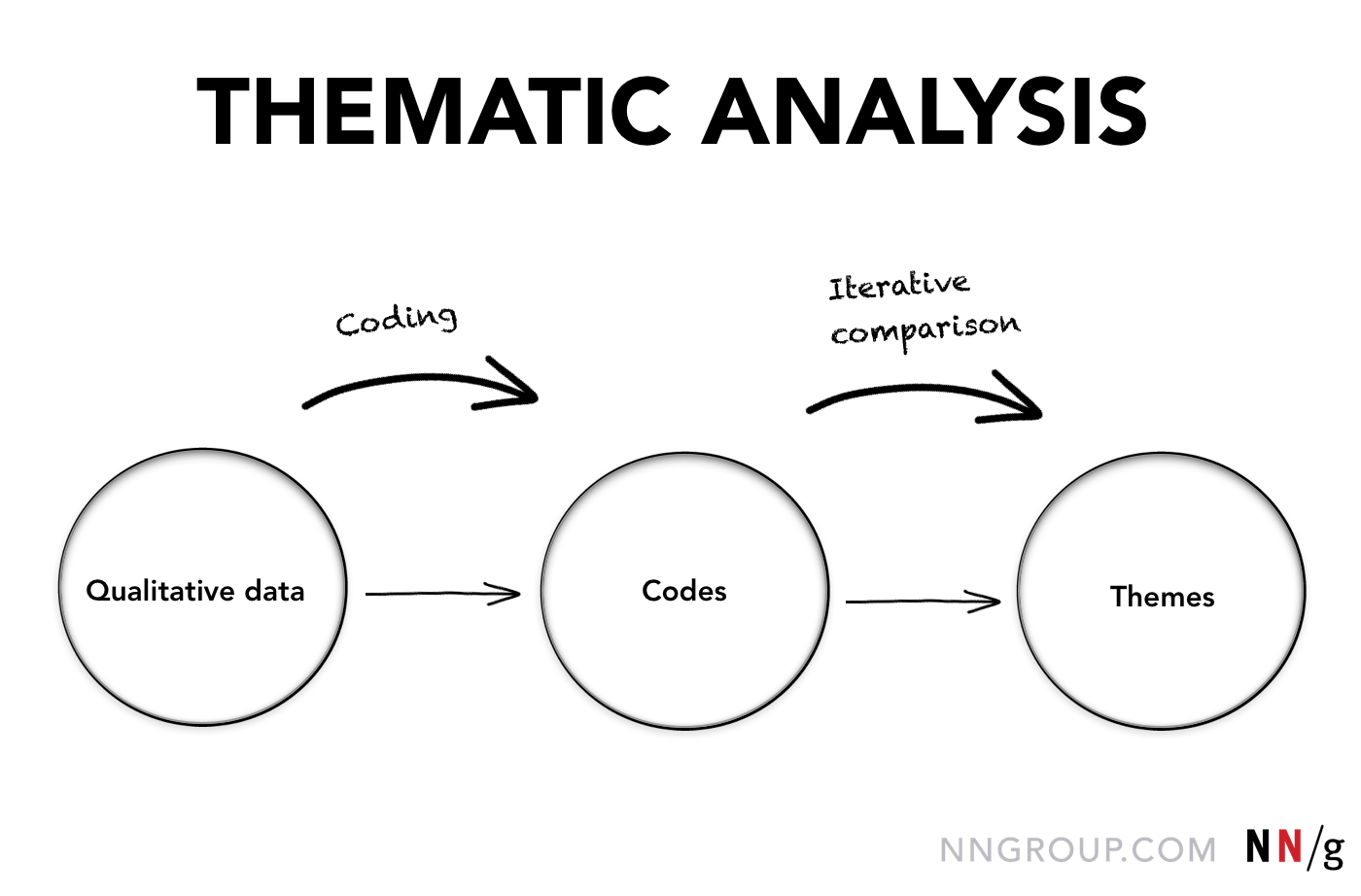
誰でもできるテーマ別分析は、質的データの重要な側面を可視化し、テーマの発見を容易にします。
テーマ別分析とは
定義です。
その名の通り、テーマ分析にはテーマを見つけることが含まれます。
- データから発見された信念、実践、ニーズ、またはその他の現象についての説明
- 関連する発見が参加者やデータソースにわたって複数回現れるときに現れる
定性的データの分析に関する課題
多くの研究者が、プロジェクトの初期段階で行われる探索的研究から得られる定性的データに圧倒されていると感じています。 以下の表は、よくある課題とその結果生じる問題を強調しています。
| CHALLENGES | RESULTING ISSUES | |
|
Large quantity of data: Qualitative research results in long transcripts and extensive field notes that can be time-consuming to read; you may have a hard time seeing patterns and remembering what’s important. |
Superficial analysis: Analysis is often done very superficially, just skimming topics, focusing on only memorable events and quotes, and missing large sections of notes. |
|
|
Rich data: There are lots of detail within every sentence or paragraph. It can be hard to see which details are useful and which are superfluous. |
Analysis becomes a description of many details: The analysis simply becomes a regurgitation of what participants’ may have said or done, without any analytical thinking applied to it. |
|
|
Contradicting data: |
矛盾したデータ:異なる参加者や同じ参加者からのデータでさえ、研究者が意味を理解しなければならないような矛盾を含んでいることがあります |
調査結果は決定的なものではありません。 |
| 分析に目標が設定されていない:参加者のフィードバックが矛盾していたり、もっと悪いことに、研究者の信念に合わない視点は無視されるため、分析は決定的ではありません。 | 分析の目標が設定されていない:研究者が細部にこだわりすぎるあまり、最初のデータ収集の目的が失われてしまう。 |
何らかの系統だったプロセスがないと、定性データの分析時に上記のような問題が発生しやすくなります。
テーマ別分析を実施するためのツールと方法
テーマ別分析は、さまざまな方法で行うことができます。
- データ
- データ分析段階の文脈と制約
- 研究者個人の仕事のスタイル
よくある3つの方法は以下の通りです。
- ソフトウェアの使用
- ジャーナリング
- 親和性図法の使用
ソフトウェアの使用
大量の定性データを分析するために、定性研究者はしばしばCAQDAS (Computer-Aided Qualitative-Data-Analysis software) – 「カクダス」と発音されます-のような、ソフトウェアを使用することがよくあります。 研究者は、トランスクリプトやフィールドノートをソフトウェアプログラムにアップロードし、正式なコーディングを通してテキストを体系的に分析します。
メリット
- 分析は非常に綿密です。
- 物理プロジェクト ファイル (生データおよび分析を含む) は、他の人と共有することができます。 (この方法は、学術機関の学生プロジェクトで人気があります。
欠点
- 小さいものに凝縮する必要がある多くのコードが生じるので、時間がかかる。 管理しやすいリスト
- 高価
- 他の人と同期して分析するのが難しい
- ソフトウェアの学習が必要
- 制限的と感じられる
ジャーナリング
テキストについての思考プロセスやアイデアを書くことは、基礎理論方法論の研究者にはよくあることです。 Journaling as a form of thematic analysis is based on this methodology and involves manual annotation and highlighting of the data, followed by writing down the researchers’ ideas and thought processes. The notes are known as memos (not to be confused with the office memo delivering news to employees).
Benefits
- The process encourages reflection through the writing of detailed notes.
- Researchers have a record of how they arrived at their themes.
- The analysis is cheap and flexible.
Drawbacks
- Hard to do collaboratively
Affinity-Diagramming Techniques
The data is highlighted, cut out physically or digitally, and reassembled into meaningful groups until themes emerge on a physical or digital board. (See a video demonstrating affinity-diagramming.)
Benefits
- Can be done collaboratively
- Quick arriving at themes
- Cheap and flexible
- Visual,
欠点
- テキストのセグメントが複数回コード化されないことが多いので、他の方法ほど完全ではない
- データが非常に多様な場合に行うのは困難である。 またはデータがたくさんある
コードとコーディング
テーマ分析のすべてのメソッドは、ある程度のコーディング (プログラミング言語でプログラムを書くことと混同しないように) を前提としています。
定義。
コードは、テキストが何について書かれているかを説明し、より複雑な情報の省略記法となります。 (良い例えに、コードは、キーワードが記事を説明するように、またはハッシュタグがツイートを説明するように、データを説明するというものがあります)。 多くの場合、質的研究者は各コードの名前だけでなく、そのコードが意味することの説明や、そのコードに合うテキストや合わないテキストの例も持っています。 これらの説明や例は、複数の人がデータのコーディングを担当する場合や、コーディングが長期間にわたって行われる場合に特に役立ちます。
定義
一度コードが割り当てられると、同じものについてのテキストのセグメントを識別し、比較することが容易になります。
一度コードが割り当てられると、同じ事柄に関するテキスト セグメントを識別して比較することが容易になります。コードによって、情報を簡単に分類し、データを分析して、セグメント間の類似性、相違、および関係を明らかにすることができます。
Code Types(コードの種類)
- 記述的なもの。 データが何であるかを記述します
- 解釈的。
記述的コードと解釈的コードの例を見るために、今年の初めに行った UX 実務家とのインタビューからの引用を見てみましょう (UX Careers レポートで発表される、UX Careers リサーチの一環として)。
「私は、会議の進行について茫然としていましたが、私の会社は1日半のコースを提供していました。 そこで、私はそこに行き、講師は当時はひどいと感じたことをしましたが、それ以来、本当に感謝するようになりました。 最初にやったのは、自分の名前を書いた紙に、司会やファシリテーションをするときに一番恐れていることを書いて提出したんです。そして、「よし、明日はこの状況を演じてみよう」と言われました(…)次の日に戻ってくると、私は部屋を出て、他のメンバーは私の最悪の恐怖を読んで、それをどう演じるかを考え、そして私が部屋に入って10分間その状況を使ってファシリテーションするんです。
以下は、上記のテキストに対する可能な記述的および解釈的コードです
Descriptive code: how skills are acquired
Rationale behind the code label.は、スキルの獲得方法を示すコードです。
Interpretive code: self-reflection
Rationaleason behind the code label:
テーマ別分析の実施手順
どのツール(ソフトウェア、ジャーナリング、親和性ダイアグラム)を使用するにせよ、テーマ別分析を実施する行為は、6 つのステップに分けることができます。
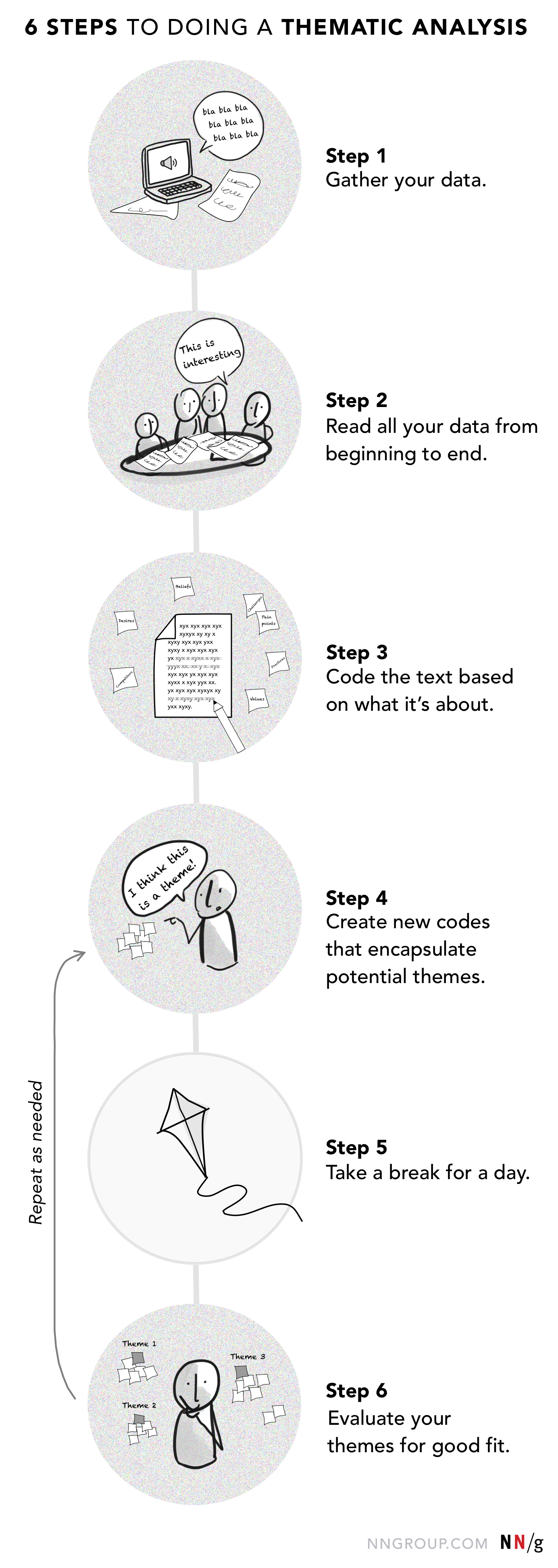
ステップ 1: すべてのデータを集める
インタビューやフォーカス グループの記録、フィールド ノート、または日記などの生のデータから始めましょう。
ステップ2: 最初から最後まですべてのデータを読む
調査を行ったのが自分であっても、分析を始める前にデータに慣れ親しんでください。 トランスクリプト、フィールドノート、その他のデータソースは、分析する前にすべて読みましょう。 このステップでは、チームをプロジェクトに参加させることができます。
ワークショップを実施します(チームが非常に大きい場合やデータが大量にある場合は、一連のワークショップを実施します)。
- チームメンバーがデータを扱う前に、リサーチクエスチョンをホワイトボードまたはフリップチャート用紙に書き、作業中に質問を参照しやすくします。
- チームメンバーが自分のエントリを読み終えたら、自分の記録またはエントリを他の人に渡し、別のチームメンバーから新しいものを受け取ることができる。
- 気づいたこと、驚いたことをグループ内で議論する。

チームがすべての研究セッションを観察するのがベストですが、セッション数が多い場合やチームが大きい場合は、そうもいかないかもしれません。 個々のチームメンバーがほんの一握りのセッションしか観察しなかった場合、調査結果を不完全に理解したまま帰ってしまうことがあります。
ステップ 3: 何について書かれたかに基づいてテキストをコーディングする
コーディングのステップでは、ハイライトした部分を簡単に比較できるように、ハイライトした部分を分類する必要があります。 リサーチクエスチョンをプリントアウトします。
十分な時間がある場合は、この最初のコーディングのステップにチームを参加させることができます。
コーディングしているときに、テキストの各セグメントを確認し、「これは何についてですか」と自問してください。 データを説明する名前(記述的コード)を断片に付けます。 また、この段階でテキストに解釈的なコードを追加することができます。
コードは、データをグループ化する前または後に作成することができます。 このステップの次の 2 つのセクションでは、コードを追加する方法とタイミングを説明します。
従来の方法。
従来の方法: グループ化の前にコードを作成する
従来の方法では、文、段落、フレーズなど、データのセグメントを強調表示すると、それらにコードを付けます。 使用したすべてのコードを記録し、それらが何であるかを概説しておくと、テキストのさらなるセクションをコーディングするときに、このリストを参照できるので便利です (特に、複数の人がテキストをコーディングする場合)。
すべてのテキストがコーディングされたら、同じコードを持つすべてのデータをグループ化できます。
このプロセスに CAQDAS を使用している場合、コーディング中に割り当てたコードをソフトウェアが自動的に記録するので、それらを再度使用することができます。 また、同じコードでコーディングされたすべてのテキストを表示する方法も提供されます。
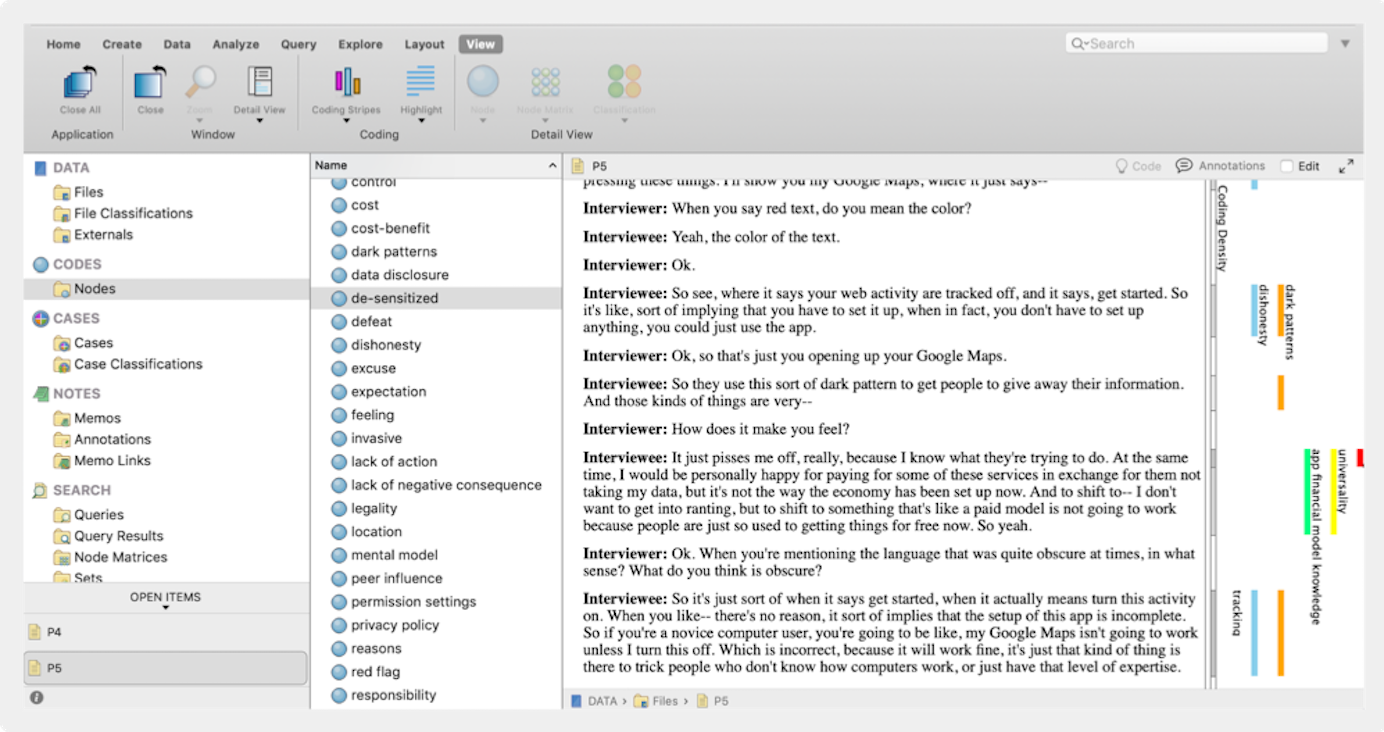
Quick Method: テキストのセグメントをグループ化し、コードを割り当てる
テキストを強調表示するときにコードを考え出すのではなく、(物理的またはデジタル的に)切り取り、類似した強調表示のセグメントをすべてまとめてください(異なる付箋をアフィニティ マップでグループ化する方法と同様です)。 グループ化された部分にはコードが付与されます。
下の写真では、グループ化を手作業で行っています。
下の写真では、グループ化は手作業で行われました。トランスクリプトを切り取り、付箋に固定し、自然なトピックグループに入るまでボード上を移動させました。


この手順の最後に、トピックごとにグループ化されたデータと、各トピックに対するコードを用意します。
例を見てみましょう。 私は、家庭での料理の経験について3人にインタビューしました。 これらのインタビューでは、参加者は、特定のものを調理し、他のものを調理しないことを選択した方法について話しました。 また、料理中に直面した具体的な課題についても話してくれました(例,
トピックごとにインタビューからハイライトされた切り抜きをグループ化した後、最終的に 3 つの広範な記述コードと対応するグループ分けを行いました:
- Cooking experiences: 調理に関連する印象深いポジティブおよびネガティブ体験
- Pain points: 誰かが料理をするのを止める、または料理を困難にするもの (食事制限、限られた予算などの回避を含む)。
- 役に立つこと
: 特定の課題または痛みのポイントを克服するのを助ける (または助けると考えられる) もの
ステップ 4: 潜在的なテーマをカプセル化する新しいコードを作成する
すべてのコードを見渡して、因果関係、類似点、差異、矛盾を調べ、根本的なテーマを明らかにできるかどうかを確認します。 そうしている間に、いくつかのコードは脇に置かれ (アーカイブされるか削除されます)、新しい解釈的なコードが作成されます。 ステップ 3 で説明したような物理的なマッピングのアプローチを使用している場合、これらの初期のグループ化のいくつかは、テーマを探すときに崩れたり広がったりすることがあります。
料理の話題に戻り、各グループ内のテキストを分析し、データ間の関係を探しているときに、2 人の参加者が、さまざまな方法で調理でき、他の異なる材料とよく合う材料が好きだと言っていることに気づきました。 また、3人目の参加者は、食事プランごとに別々の食材を購入するのではなく、1週間を通してさまざまな食事に使える食材があればいいと話していました。 このように、「食材の柔軟性」という新たなテーマが生まれました。

Step 5: 一日休んでからデータに戻る
ほとんど常に、一休みして戻って、新しい目でデータを見るのはよい考えです。
ステップ 6 :テーマがうまく適合しているか評価する
このステップでは、コードと新たに現れたテーマをレビューするために、他の人に協力してもらうと便利でしょう。 新しい洞察が引き出されるだけでなく、あなたの結論は、新鮮な目や頭脳によって挑戦され、批評される可能性があります。
テーマを精査してください。
- そのテーマはデータによって十分に裏付けられているか。 あるいは、テーマをサポートしないデータを見つけることができるか?
- テーマは多くのインスタンスで飽和しているか?
- データを個別に分析した後、他の人はあなたがデータで見つけたテーマに同意するか?
これらの質問への答えがノーなら、それはあなたが分析ボードに戻る必要があることを意味するかもしれません。 健全なデータを収集したと仮定すると、ほとんどの場合、学ぶべきことがあるので、ステップ 4 ~ 6 を繰り返すためにチームとより多くの時間を費やすことは価値があるでしょう。
結論
多くの定性データを効率的にかき分けるための役に立つガイドとして主題分析を使用します。 テーマ別分析のやり方は一つではありません。 収集したデータの種類や量に応じた分析方法を選びましょう。 可能であれば、分析の精度を高め、ユーザーの行動、動機、ニーズに関するチームの知識を高めるために、分析プロセスに他の人を招きましょう。 分析は長いプロセスになる可能性があるので、データ収集に費やした時間と同じだけ、分析を完了させるための予算を立てるのがよい経験則です。 ユーザーインタビュー、価値、動機、および欲求を明らかにする高度なテクニック、UXカンファレンスの1日コース
。