Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
Het perceptron neemt een speciale plaats in in de geschiedenis van neurale netwerken en kunstmatige intelligentie, omdat de aanvankelijke hype over zijn prestaties leidde tot een weerlegging door Minsky en Papert, en een breder verspreide tegenreactie die decennia lang een domper wierp op het neurale netwerkonderzoek, een neurale netwerkwinter die pas helemaal ontdooid werd met het onderzoek van Geoff Hinton in de jaren 2000, waarvan de resultaten sindsdien de machine-learning gemeenschap hebben overspoeld.
Frank Rosenblatt, de peetvader van de perceptron, populariseerde het als een apparaat in plaats van een algoritme. Rosenblatt, een psycholoog die studeerde en later doceerde aan de Cornell University, kreeg geld van het U.S. Office of Naval Research om een machine te bouwen die kon leren. Zijn machine, de Mark I perceptron, zag er als volgt uit.

Een perceptron is een lineaire classificeerder; dat wil zeggen dat het een algoritme is dat invoer classificeert door twee categorieën met een rechte lijn van elkaar te scheiden. Input is meestal een feature vector x vermenigvuldigd met gewichten w en toegevoegd aan een bias by = w * x + b.
Een perceptron produceert een enkele output op basis van verschillende reële inputs door een lineaire combinatie te vormen met behulp van de inputgewichten (en soms de output door een niet-lineaire activeringsfunctie te halen). Zo kun je dat in de wiskunde schrijven:
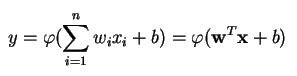
waarbij w de vector van de gewichten is, x de vector van de ingangen, b de bias en phi de niet-lineaire activeringsfunctie.
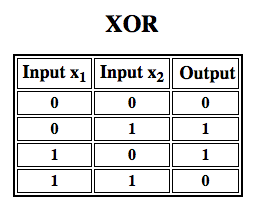
Rosenblatt bouwde een eenlagige perceptron. Dat wil zeggen, zijn hardware-algoritme bevatte geen meervoudige lagen, die neurale netwerken in staat stellen een kenmerkenhiërarchie te modelleren. Het was dus een ondiep neuraal netwerk, waardoor zijn perceptron geen niet-lineaire classificatie kon uitvoeren, zoals de XOR-functie (een XOR-operator treedt in werking wanneer de invoer ofwel de ene eigenschap ofwel de andere vertoont, maar niet beide; het staat voor “exclusive OR”), zoals Minsky en Papert in hun boek laten zien.
Renforcement Learning toepassen op simulaties”
Multilayer Perceptrons (MLP)
Verder werk met multilayer perceptrons heeft aangetoond dat deze in staat zijn een XOR-operator te benaderen, evenals vele andere niet-lineaire functies.
Net zoals Rosenblatt het perceptron baseerde op een McCulloch-Pitts neuron, bedacht in 1943, zo zijn ook perceptrons zelf bouwstenen die pas nuttig blijken te zijn in zulke grotere functies als meerlaagse perceptrons.2)
De meerlaagse perceptron is de hallo-wereld van deep learning: een goede plek om te beginnen als je leert over deep learning.
Een meerlaagse perceptron (MLP) is een diep, kunstmatig neuraal netwerk. Het is samengesteld uit meer dan één perceptron. Ze bestaan uit een inputlaag om het signaal te ontvangen, een outputlaag die een beslissing of voorspelling maakt over de input, en tussen die twee, een willekeurig aantal verborgen lagen die de echte rekenmotor van het MLP zijn. MLP’s met één verborgen laag kunnen elke continue functie benaderen.
Multilayer perceptrons worden vaak toegepast op gesuperviseerde leerproblemen3: zij trainen op een set input-output paren en leren de correlatie (of afhankelijkheden) tussen die inputs en outputs te modelleren. Bij het trainen worden de parameters, of de gewichten en biases, van het model aangepast om de fouten tot een minimum te beperken. Backpropagatie wordt gebruikt om die wegingen en bias-aanpassingen te maken ten opzichte van de fout, en de fout zelf kan op verschillende manieren worden gemeten, onder meer aan de hand van de root mean squared error (RMSE).
Feedforward netwerken zoals MLP’s zijn als tennis, of pingpong. Ze zijn voornamelijk bezig met twee bewegingen, een constante heen en weer. Je kunt deze pingpong van gissingen en antwoorden zien als een soort versnelde wetenschap, want elke gok is een test van wat we denken te weten, en elk antwoord is feedback die ons laat weten hoe fout we zitten.
In de voorwaartse doorgang beweegt de signaalstroom zich van de ingangslaag via de verborgen lagen naar de uitgangslaag, en de beslissing van de uitgangslaag wordt afgemeten aan de labels van de grondwaarheid.
In de achterwaartse doorgang worden, met behulp van backpropagatie en de kettingregel van de calculus, gedeeltelijke afgeleiden van de foutfunctie t.o.v. de verschillende gewichten en biases teruggepageerd door het MLP. Deze differentiatie geeft ons een gradiënt, of een foutenlandschap, waarlangs de parameters kunnen worden aangepast naarmate zij het MLP een stap dichter bij het foutminimum brengen. Dit kan worden gedaan met elk op gradiënten gebaseerd optimalisatiealgoritme, zoals stochastische gradiëntafdaling. Het netwerk blijft dit tennisspel spelen totdat de fout niet lager kan gaan. Deze toestand staat bekend als convergentie.
Voetnoten
1) Het interessante om hier op te wijzen is dat software en hardware op een stroomschema bestaan: software kan worden uitgedrukt als hardware en vice versa. Wanneer chips zoals FPGA’s worden geprogrammeerd, of ASIC’s worden gebouwd om een bepaald algoritme in silicium te bakken, zijn we gewoon software een niveau lager aan het implementeren om het sneller te laten werken. Evenzo kan wat in silicium is gebakken of met lampjes en potentiometers aan elkaar is gekoppeld, zoals Rosenblatt’s Mark I, ook symbolisch in code worden uitgedrukt. Dit is de reden waarom Alan Kay heeft gezegd: “Mensen die echt serieus zijn over software zouden hun eigen hardware moeten maken.” Maar er is geen gratis lunch; d.w.z. wat je wint aan snelheid door algoritmen in silicium te bakken, verlies je aan flexibiliteit, en vice versa. Dit is een reëel probleem met betrekking tot machine learning, aangezien de algoritmen zichzelf veranderen door blootstelling aan gegevens. De uitdaging is om die delen van het algoritme te vinden die stabiel blijven, zelfs als de parameters veranderen; bijvoorbeeld de lineaire algebra-operaties die momenteel het snelst door GPU’s worden verwerkt.
2) Uw gedachten gaan misschien uit naar de volgende stap in steeds complexere en ook nuttigere algoritmen. We gaan van één neuron naar meerdere, een laag genoemd; we gaan van één laag naar meerdere, een multilayer perceptron genoemd. Kunnen we van één MLP naar meerdere gaan, of blijven we gewoon lagen stapelen, zoals Microsoft deed met zijn ImageNet-winnaar, ResNet, dat meer dan 150 lagen had? Of is de juiste combinatie van MLP’s een ensemble van vele algoritmen die in een soort computerdemocratie stemmen over de beste voorspelling? Of is het inbedden van het ene algoritme in het andere, zoals we doen met convolutionele netwerken?
3) Ze worden op grote schaal gebruikt bij Google, waarschijnlijk het meest geavanceerde AI-bedrijf ter wereld, voor een breed scala van taken, ondanks het bestaan van complexere, state-of-the-art methoden.
Verder lezen
- The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, door Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: An Introduction to Computational Geometry, door Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Hebbiaanse Theorie
Andere Pathmind Wiki Posten
- Diepe Neurale Netwerken
- Recurrente Neurale Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning