In oktober vorig jaar kondigde Google aan dat een van die chips, Sycamore genaamd, de eerste was geworden die “quantum suprematie” had gedemonstreerd door een taak uit te voeren die op een klassieke machine praktisch onmogelijk zou zijn. Met slechts 53 qubits had Sycamore in een paar minuten een berekening uitgevoerd waar de krachtigste bestaande supercomputer ter wereld, Summit, volgens Google 10.000 jaar over zou hebben gedaan. Google noemde dit een grote doorbraak en vergeleek het met de lancering van de Spoetnik of de eerste vlucht van de gebroeders Wright – de drempel van een nieuw machinetijdperk dat de machtigste computer van vandaag op een telraam zou doen lijken.
Op een persconferentie in het lab in Santa Barbara beantwoordde het Google-team bijna drie uur lang opgewekt vragen van journalisten. Maar hun goede humeur kon een onderliggende spanning niet helemaal maskeren. Twee dagen eerder hadden onderzoekers van IBM, Google’s grootste concurrent op het gebied van quantumcomputing, de grote onthulling van Google getorpedeerd. Ze hadden een artikel gepubliceerd waarin ze de Googlers er in wezen van beschuldigden hun berekeningen verkeerd te hebben. IBM schatte dat het Summit slechts dagen, en geen millennia, zou hebben gekost om te repliceren wat Sycamore had gedaan. Op de vraag wat hij van het resultaat van IBM vond, vermeed Hartmut Neven, het hoofd van het Google-team, een direct antwoord te geven.

Je zou dit kunnen afdoen als slechts een academische ruzie, en in zekere zin was dat ook zo. Zelfs als IBM gelijk had, dan nog had Sycamore de berekening duizend keer sneller uitgevoerd dan Summit dat zou hebben gedaan. En het zou waarschijnlijk nog maanden duren voordat Google een iets grotere kwantummachine zou bouwen die het punt onomstotelijk zou bewijzen.
Het diepere bezwaar van IBM was echter niet dat Google’s experiment minder succesvol was dan werd beweerd, maar dat het in de eerste plaats een zinloze test was. In tegenstelling tot het grootste deel van de wereld van quantumcomputing denkt IBM niet dat “quantum suprematie” het Wright Brothers-moment van de technologie is; sterker nog, het gelooft niet eens dat er zo’n moment zal komen.
IBM jaagt in plaats daarvan een heel andere maatstaf voor succes na, iets wat het “quantumvoordeel” noemt. Dit is niet louter een verschil van woorden of zelfs van wetenschap, maar een filosofische houding met wortels in de geschiedenis, cultuur en ambities van IBM – en misschien ook het feit dat de inkomsten en winst van het bedrijf al acht jaar lang bijna onafgebroken dalen, terwijl Google en zijn moederbedrijf Alphabet hun cijfers alleen maar hebben zien groeien. Deze context, en deze verschillende doelstellingen, zouden van invloed kunnen zijn op wie – als een van beide – voorop komt te liggen in de kwantumcomputerwedloop.
Werelden verschillen
De strakke, vloeiende curve van IBM’s Thomas J. Watson Research Center in de buitenwijken ten noorden van New York City, een neo-futuristisch meesterwerk van de Finse architect Eero Saarinen, is een continent en een universum verwijderd van de onopvallende kotten van het Google-team. Het gebouw, dat in 1961 werd voltooid met de miljarden die IBM met mainframes verdiende, heeft iets museaals, en herinnert iedereen die er werkt aan de doorbraken van het bedrijf op het gebied van fractale geometrie, supergeleiders, kunstmatige intelligentie en quantumcomputing.
Het hoofd van de 4000 medewerkers tellende onderzoeksdivisie is Dario Gil, een Spanjaard wiens vlotte spraak gelijke tred houdt met zijn bijna evangelische ijver. Beide keren dat ik hem sprak, ratelde hij historische mijlpalen af om te onderstrepen hoe lang IBM al betrokken is bij onderzoek op het gebied van quantumcomputing (zie tijdlijn rechts).


Een groot experiment: Quantumtheorie en -praktijk
De basisbouwsteen van een quantumcomputer is de quantumbit, of qubit. In een klassieke computer kan een bit een 0 of een 1 bevatten. Een qubit kan niet alleen een 0 of een 1 bevatten, maar ook een tussenliggende toestand, superpositie genaamd, die een groot aantal verschillende waarden kan aannemen. Een analogie is dat als informatie kleur zou zijn, een klassiek bit zwart of wit zou kunnen zijn. Een qubit in superpositie kan elke kleur van het spectrum zijn, en kan ook variëren in helderheid.
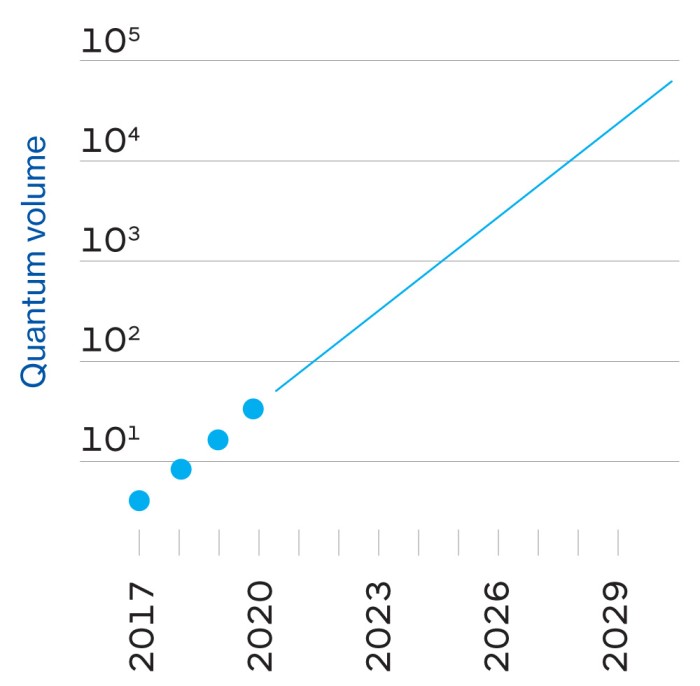
Het resultaat is dat een qubit een enorme hoeveelheid informatie kan opslaan en verwerken in vergelijking met een bit – en de capaciteit neemt exponentieel toe naarmate je qubits met elkaar verbindt. Het opslaan van alle informatie in de 53 qubits op de Sycamore-chip van Google zou ongeveer 72 petabytes (72 miljard gigabytes) aan klassiek computergeheugen vergen. Er zijn niet veel meer qubits nodig voordat je een klassieke computer ter grootte van de planeet nodig zou hebben.
Maar het is niet eenvoudig. Qubits zijn kwetsbaar en gemakkelijk te verstoren, en moeten bijna perfect worden geïsoleerd van warmte, trillingen en rondzwervende atomen – vandaar de “kroonluchter”-koelkasten in Google’s kwantumlaboratorium. Zelfs dan kunnen ze hooguit een paar honderd microseconden functioneren voordat ze “decoheren” en hun superpositie verliezen.
En kwantumcomputers zijn niet altijd sneller dan klassieke computers. Ze zijn gewoon anders, sneller in sommige dingen en langzamer in andere, en ze vereisen verschillende soorten software. Om hun prestaties te vergelijken, moet je een klassiek programma schrijven dat het kwantumprogramma bij benadering simuleert.
Voor zijn experiment koos Google een benchmarkingtest die “random quantum circuit sampling” wordt genoemd. Deze genereert miljoenen willekeurige getallen, maar met lichte statistische afwijkingen die een kenmerk zijn van het kwantumalgoritme. Als Sycamore een zakrekenmachine zou zijn, zou het neerkomen op het willekeurig indrukken van toetsen en controleren of het display de verwachte resultaten laat zien.
Google simuleerde delen van deze test op zijn eigen enorme server farms en op Summit, ’s werelds grootste supercomputer, in het Oak Ridge National Laboratory. De onderzoekers schatten dat het voltooien van de hele klus, die Sycamore 200 seconden kostte, Summit ongeveer 10.000 jaar zou hebben gekost. Voilà: quantum suprematie.
Dus wat was het bezwaar van IBM? Dat er verschillende manieren zijn om een klassieke computer een kwantummachine te laten simuleren, en dat de software die je schrijft, de manier waarop je gegevens versnippert en opslaat, en de hardware die je gebruikt allemaal een groot verschil maken in hoe snel de simulatie kan worden uitgevoerd. IBM zei dat Google ervan uitging dat de simulatie in een groot aantal brokken zou moeten worden opgedeeld, maar Summit, met 280 petabytes aan opslagruimte, is groot genoeg om de complete staat van Sycamore in één keer te bevatten. (En IBM heeft Summit gebouwd, dus het zou het moeten weten.)
Maar in de loop der decennia heeft het bedrijf de reputatie gekregen moeite te hebben zijn onderzoeksprojecten om te zetten in commerciële successen. Neem nu Watson, de Jeopardy- spelende AI die IBM probeerde om te vormen tot een medische robotgoeroe. Het was de bedoeling dat Watson diagnoses zou stellen en trends zou herkennen in zeeën van medische gegevens, maar ondanks tientallen samenwerkingsverbanden met zorgaanbieders zijn er maar weinig commerciële toepassingen gekomen, en zelfs de toepassingen die er wel zijn, hebben gemengde resultaten opgeleverd.
Het kwantumcomputing-team probeert volgens Gil die cyclus te doorbreken door onderzoek en bedrijfsontwikkeling parallel te laten verlopen. Vrijwel meteen nadat het werkende kwantumcomputers had, begon het ze toegankelijk te maken voor buitenstaanders door ze in de cloud te zetten, waar ze kunnen worden geprogrammeerd door middel van een eenvoudige drag-and-drop interface die werkt in een webbrowser. De “IBM Q Experience”, gelanceerd in 2016, bestaat nu uit 15 publiek beschikbare kwantumcomputers variërend van vijf tot 53 qubits in grootte. Zo’n 12.000 mensen per maand maken er gebruik van, variërend van academische onderzoekers tot schoolkinderen. Tijd op de kleinere machines is gratis; IBM zegt dat het al meer dan 100 klanten heeft die betalen (het wil niet zeggen hoeveel) om de grotere te gebruiken.
Geen van deze apparaten – of enige andere kwantumcomputer in de wereld, met uitzondering van Google’s Sycamore – heeft tot nu toe aangetoond dat het een klassieke machine kan verslaan in alles. Voor IBM is dat op dit moment niet het punt. Door de machines online beschikbaar te stellen kan het bedrijf leren wat toekomstige klanten ervan zouden kunnen verwachten en kunnen externe softwareontwikkelaars leren hoe ze er code voor kunnen schrijven. Dat draagt weer bij aan hun ontwikkeling, waardoor volgende kwantumcomputers beter worden.
Deze cyclus is volgens het bedrijf de snelste weg naar zijn zogenaamde kwantumvoordeel, een toekomst waarin kwantumcomputers de klassieke niet per se in het stof zullen laten verdwijnen, maar sommige nuttige dingen iets sneller of efficiënter zullen doen – genoeg om ze economisch lonend te maken. Terwijl quantum suprematie een enkele mijlpaal is, is quantum voordeel een “continuüm”, zeggen de IBMers – een geleidelijk groeiende wereld van mogelijkheden.
Dit is dus Gil’s grand unified theory van IBM: dat door het combineren van zijn erfgoed, zijn technische expertise, andermans denkkracht, en zijn toewijding aan zakelijke klanten, het sneller en beter dan wie dan ook bruikbare quantum computers kan bouwen.
In deze visie ziet IBM de demonstratie van Google’s kwantumovermacht als “een goocheltruc”, zegt Scott Aaronson, een natuurkundige aan de University of Texas in Austin, die heeft meegewerkt aan de kwantumalgoritmen die Google gebruikt. In het beste geval is het een opzichtige afleiding van het echte werk dat nog moet gebeuren. In het slechtste geval is het misleidend, omdat het mensen zou kunnen laten denken dat kwantumcomputers klassieke computers kunnen verslaan in alles in plaats van in één zeer beperkte taak. “Supremacy’ is een Engels woord dat het publiek wel eens verkeerd zou kunnen interpreteren,” zegt Gil.
Google ziet dat natuurlijk anders.
Enter the upstart
Google was een vroegrijp acht jaar oud bedrijf toen het in 2006 voor het eerst begon te sleutelen aan kwantumproblemen, maar het vormde pas een speciaal kwantumlab in 2012 – hetzelfde jaar waarin John Preskill, een natuurkundige van Caltech, de term “kwantum suprematie” bedacht.”
Het hoofd van het lab is Hartmut Neven, een Duitse computerwetenschapper met een indrukwekkende aanwezigheid en een voorliefde voor Burning Man-achtige chic; ik zag hem een keer in een harige blauwe jas en een andere keer in een volledig zilveren outfit die hem deed lijken op een grungy astronaut. (“Mijn vrouw koopt die dingen voor me,” legde hij uit.) In eerste instantie kocht Neven een machine die was gebouwd door een extern bedrijf, D-Wave, en hij heeft een tijdje geprobeerd er quantum suprematie mee te bereiken, maar zonder succes. Hij zegt dat hij Larry Page, de toenmalige CEO van Google, ervan overtuigde om in 2014 te investeren in de bouw van kwantumcomputers door hem te beloven dat Google de uitdaging van Preskill zou aangaan: “We zeiden tegen hem: ‘Luister, Larry, over drie jaar komen we terug en leggen we een prototype-chip op je tafel die op zijn minst een probleem kan berekenen dat de mogelijkheden van klassieke machines te boven gaat.’
Mits kwantumexpertise van IBM ontbrak, huurde Google een team van buiten in, geleid door John Martinis, een natuurkundige aan de University of California, Santa Barbara. Martinis en zijn groep behoorden al tot de beste kwantumcomputers ter wereld – ze waren erin geslaagd om tot negen qubits aan elkaar te knopen – en de belofte van Neven aan Page leek hen een waardig doel om na te streven.
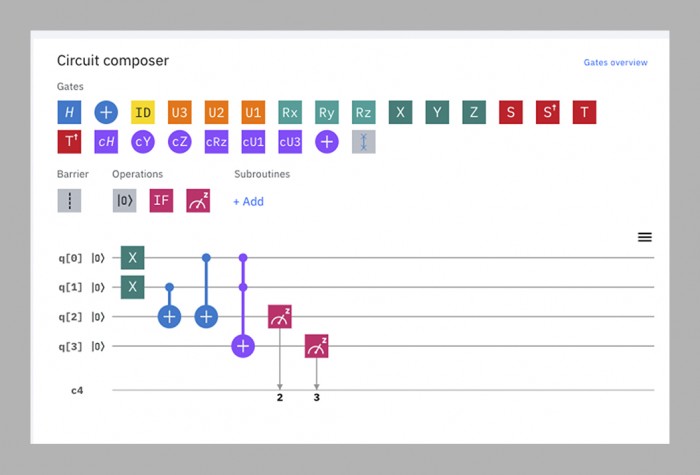
De deadline van drie jaar kwam en ging, terwijl het team van Martinis worstelde om een chip te maken die zowel groot als stabiel genoeg was voor de uitdaging. In 2018 bracht Google zijn grootste processor tot nu toe uit, Bristlecone. Met 72 qubits lag hij ver voor op alles wat zijn rivalen hadden gemaakt, en Martinis voorspelde dat hij nog datzelfde jaar de kwantumsuprematie zou bereiken. Maar een paar teamleden hadden parallel gewerkt aan een andere chiparchitectuur, Sycamore genaamd, die uiteindelijk meer bleek te kunnen doen met minder qubits. Het was dus een chip met 53 qubits – oorspronkelijk 54, maar een ervan werkte niet goed – die afgelopen herfst uiteindelijk de suprematie bewees.
Voor praktische doeleinden is het programma dat bij die demonstratie werd gebruikt vrijwel onbruikbaar – het genereert willekeurige getallen, iets waarvoor je geen quantumcomputer nodig hebt. Maar het genereert ze op een bepaalde manier die voor een klassieke computer heel moeilijk te repliceren zou zijn, waarmee het bewijs van het concept is geleverd (zie de pagina hiernaast).
Vraag IBM’ers wat ze van deze prestatie vinden, en je krijgt gepijnigde blikken. “Ik hou niet van het woord , en ik hou niet van de implicaties,” zegt Jay Gambetta, een voorzichtig sprekende Australiër die aan het hoofd staat van IBM’s quantumteam. Het probleem is, zegt hij, dat het vrijwel onmogelijk is te voorspellen of een bepaalde kwantumberekening moeilijk zal zijn voor een klassieke machine, dus als je het in één geval laat zien, helpt dat je niet om andere gevallen te vinden.
Voor iedereen die ik buiten IBM sprak, grenst deze weigering om kwantumovermacht als significant te behandelen aan eigenwijsheid. “Iedereen die ooit een commercieel relevant aanbod zal hebben – die moet eerst suprematie aantonen. Ik denk dat dat gewoon basislogica is,” zegt Neven. Zelfs Will Oliver, een milde natuurkundige van MIT die een van de meest onpartijdige waarnemers van het gekibbel is geweest, zegt: “Het is een zeer belangrijke mijlpaal om te laten zien dat een kwantumcomputer beter presteert dan een klassieke computer bij een of andere taak, wat die ook is.”
De kwantumsprong
Of je het nu eens bent met het standpunt van Google of dat van IBM, het volgende doel is duidelijk, zegt Oliver: een kwantumcomputer bouwen die iets nuttigs kan doen. De hoop is dat dergelijke machines op een dag problemen kunnen oplossen waarvoor nu nog onhaalbare hoeveelheden brute rekenkracht nodig zijn, zoals het modelleren van complexe moleculen om nieuwe medicijnen en materialen te helpen ontdekken, of het optimaliseren van verkeersstromen in steden in realtime om files te verminderen, of het maken van weersvoorspellingen op de langere termijn. (Uiteindelijk zullen ze misschien in staat zijn de cryptografische codes te kraken die nu worden gebruikt om communicatie en financiële transacties te beveiligen, hoewel tegen die tijd waarschijnlijk het grootste deel van de wereld zal zijn overgegaan op kwantumbestendige cryptografie). Het probleem is dat het vrijwel onmogelijk is te voorspellen wat de eerste nuttige taak zal zijn, of hoe groot de computer zal moeten zijn om die uit te voeren.
Die onzekerheid heeft te maken met zowel hardware als software. Wat de hardware betreft, denkt Google dat de huidige chipontwerpen tussen de 100 en 1.000 qubits kunnen bereiken. Maar net zoals de prestaties van een auto niet alleen afhangen van de grootte van de motor, worden de prestaties van een quantumcomputer niet alleen bepaald door het aantal qubits. Er is nog een hele reeks andere factoren waarmee rekening moet worden gehouden, zoals hoe lang ze kunnen worden bewaard voor decohering, hoe foutgevoelig ze zijn, hoe snel ze werken en hoe ze onderling zijn verbonden. Dit betekent dat een quantumcomputer die nu werkt slechts een fractie van zijn volledige potentieel bereikt.
De software voor kwantumcomputers staat intussen net zo goed in de kinderschoenen als de machines zelf. In de klassieke informatica zijn programmeertalen nu verschillende niveaus verwijderd van de ruwe “machinecode” die vroege softwareontwikkelaars moesten gebruiken, omdat de details van hoe gegevens worden opgeslagen, verwerkt en rondgerangeerd al gestandaardiseerd zijn. “Als je een klassieke computer programmeert, hoef je niet te weten hoe een transistor werkt”, zegt Dave Bacon, die de leiding heeft over de software van het Google-team. Kwantumcode moet daarentegen sterk worden afgestemd op de qubits waarop het zal draaien, om het maximale uit hun temperamentvolle prestaties te halen. Dat betekent dat de code voor IBM’s chips niet zal werken op die van andere bedrijven, en dat zelfs technieken om Google’s 53-qubit Sycamore te optimaliseren niet noodzakelijk goed zullen werken op zijn toekomstige 100-qubit broertje. Nog belangrijker is dat niemand kan voorspellen hoe moeilijk de problemen zullen zijn die met die 100 qubits kunnen worden opgelost.
Het hoogste waarop iemand durft te hopen is dat computers met een paar honderd qubits binnen een paar jaar zo ver zullen zijn dat ze een redelijk complexe scheikunde kunnen simuleren – misschien zelfs genoeg om de zoektocht naar een nieuw medicijn of een efficiëntere batterij te bevorderen. Maar decoherentie en fouten zullen al deze machines tot stilstand brengen voordat ze iets echt moeilijks kunnen doen, zoals het breken van cryptografie.
Om een quantumcomputer te bouwen met de kracht van 1000 qubits, heb je een miljoen echte qubits nodig.
Dat vereist een “fouttolerante” quantumcomputer, een computer die fouten kan compenseren en zichzelf voor onbepaalde tijd aan de gang kan houden, net zoals klassieke computers dat doen. De verwachte oplossing is het creëren van redundantie: honderden qubits als één geheel laten werken, in een gedeelde quantumtoestand. Gezamenlijk kunnen ze de fouten van individuele qubits corrigeren. En als elke qubit bezwijkt aan decoherentie, brengen zijn buren hem weer tot leven, in een eindeloze cyclus van wederzijdse reanimatie.
De gangbare voorspelling is dat er wel 1000 qubits nodig zijn om die stabiliteit te bereiken – wat betekent dat er een miljoen qubits nodig zijn om een computer te bouwen met de kracht van 1000 qubits. Google schat “voorzichtig” dat het een miljoen-qubit processor kan bouwen binnen 10 jaar, zegt Neven, hoewel er een aantal grote technische hindernissen te overwinnen zijn, waaronder een waarin IBM nog een voorsprong kan hebben op Google (zie de pagina hiernaast).
Tegen die tijd kan er veel veranderd zijn. De supergeleidende qubits die Google en IBM nu gebruiken, zouden wel eens de vacuümbuizen van hun tijd kunnen blijken te zijn, vervangen door iets veel stabielers en betrouwbaarders. Onderzoekers over de hele wereld experimenteren met verschillende methoden om qubits te maken, maar slechts weinigen zijn ver genoeg gevorderd om er werkende computers mee te bouwen. Rivaliserende startups zoals Rigetti, IonQ, of Quantum Circuits kunnen een voorsprong ontwikkelen in een bepaalde techniek en de grotere bedrijven voorbijstreven.
Een verhaal van twee transmons
De transmon-qubits van Google en IBM zijn bijna identiek, met één klein maar potentieel cruciaal verschil.
In zowel de quantumcomputers van Google als die van IBM worden de qubits zelf bestuurd door microgolfpulsen. Door kleine fabricagefouten reageren geen twee qubits op pulsen van precies dezelfde frequentie. Er zijn twee oplossingen: de frequentie van de pulsen variëren om de “sweet spot” van elke qubit te vinden, zoals je een slecht afgesneden sleutel in een slot net zolang heen en weer beweegt tot hij opengaat, of magnetische velden gebruiken om elke qubit op de juiste frequentie “af te stemmen”.
IBM gebruikt de eerste methode; Google gebruikt de tweede. Elke aanpak heeft plus- en minpunten. De afstembare qubits van Google werken sneller en preciezer, maar ze zijn minder stabiel en vereisen meer schakelingen. IBM’s qubits met een vaste frequentie zijn stabieler en eenvoudiger, maar ze werken langzamer.
Technisch gezien is het een tweestrijd, althans in dit stadium. Maar in termen van bedrijfsfilosofie is het het verschil tussen Google en IBM in een notendop – of liever, in een qubit.
Google heeft ervoor gekozen om wendbaar te zijn. “In het algemeen gaat onze filosofie iets meer in de richting van hogere beheersbaarheid ten koste van de cijfers waar mensen doorgaans naar zoeken,” zegt Hartmut Neven.
IBM, aan de andere kant, koos voor betrouwbaarheid. “Er is een groot verschil tussen het uitvoeren van een laboratoriumexperiment en het publiceren van een artikel, en het opzetten van een systeem met een betrouwbaarheid van bijvoorbeeld 98%, zodat je het de hele tijd kunt gebruiken”, zegt Dario Gil.
Op dit moment heeft Google een streepje voor. Maar als de machines groter worden, kan het voordeel omslaan naar IBM. Elke qubit wordt aangestuurd door zijn eigen individuele draden; voor een afstembare qubit is één extra draad nodig. Het uitdokteren van de bedrading voor duizenden of miljoenen qubits zal een van de moeilijkste technische uitdagingen zijn waar de twee bedrijven voor staan; IBM zegt dat dit een van de redenen is waarom ze voor de qubit met vaste frequentie hebben gekozen. Martinis, het hoofd van het Google-team, zegt dat hij persoonlijk de afgelopen drie jaar heeft geprobeerd om bedradingsoplossingen te vinden. “Het is zo’n belangrijk probleem dat ik eraan heb gewerkt,” grapt hij.
Maar gezien hun omvang en rijkdom hebben zowel Google als IBM een kans om serieuze spelers te worden op het gebied van quantumcomputing. Bedrijven zullen hun machines huren om problemen aan te pakken, net zoals ze nu cloud-gebaseerde dataopslag en verwerkingskracht huren van Amazon, Google, IBM of Microsoft. En wat begon als een strijd tussen natuurkundigen en computerwetenschappers zal zich ontwikkelen tot een wedstrijd tussen zakelijke dienstendivisies en marketingafdelingen.
Welk bedrijf is het best geplaatst om die wedstrijd te winnen? IBM, met zijn dalende inkomsten, heeft misschien een groter gevoel van urgentie dan Google. Het weet uit bittere ervaring wat het kost om traag een markt te betreden: afgelopen zomer heeft het, in zijn duurste aankoop ooit, 34 miljard dollar neergeteld voor Red Hat, een leverancier van open-source clouddiensten, in een poging om Amazon en Microsoft op dat gebied in te halen en zijn financiële fortuin te keren. Zijn strategie om zijn kwantummachines in de cloud te zetten en vanaf het begin een betalende business op te bouwen, lijkt ontworpen om het een voorsprong te geven.
Google is onlangs begonnen het voorbeeld van IBM te volgen, en tot zijn commerciële klanten behoren nu het Amerikaanse ministerie van Energie, Volkswagen en Daimler. De reden dat het dit niet eerder heeft gedaan, zegt Martinis, is simpel: “We hadden niet de middelen om het in de cloud te zetten.” Maar dat is een andere manier om te zeggen dat het de luxe had om van business development geen prioriteit te maken.
Of dat besluit IBM een voorsprong geeft, is te vroeg om te zeggen, maar waarschijnlijk belangrijker zal zijn hoe de twee bedrijven hun andere sterke punten de komende jaren op het probleem toepassen. IBM, zegt Gil, zal profiteren van zijn “full stack”-expertise in alles van materiaalwetenschap en chipfabricage tot het bedienen van grote zakelijke klanten. Google, daarentegen, kan bogen op een Silicon Valley-achtige innovatiecultuur en veel ervaring met het snel opschalen van activiteiten.
Wat de kwantumovermacht zelf betreft, dit zal een belangrijk moment in de geschiedenis zijn, maar dat wil niet zeggen dat het ook een beslissend moment zal zijn. After all, everyone knows about the Wright brothers’ first flight, but can anybody remember what they did afterwards?
Sign inSubscribe now