Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
Perceptron zajmuje szczególne miejsce w historii sieci neuronowych i sztucznej inteligencji, ponieważ początkowy szum wokół jego wydajności doprowadził do kontrargumentów Minsky’ego i Paperta, a także do szerszego rozgłosu, który rzucił cień na badania nad sieciami neuronowymi na dziesięciolecia, zimę sieci neuronowych, która w pełni odwilżyła się dopiero dzięki badaniom Geoffa Hintona w latach 2000, których wyniki od tego czasu wstrząsnęły społecznością uczących się maszyn.
Frank Rosenblatt, ojciec chrzestny perceptronu, spopularyzował go jako urządzenie, a nie algorytm. Rosenblatt, psycholog, który studiował, a później wykładał na Cornell University, otrzymał fundusze z U.S. Office of Naval Research na zbudowanie maszyny, która mogłaby się uczyć. Jego maszyna, perceptron Mark I, wyglądała tak.

Perceptron jest klasyfikatorem liniowym; to znaczy, jest algorytmem, który klasyfikuje dane wejściowe, oddzielając dwie kategorie linią prostą. Dane wejściowe to zazwyczaj wektor cech x pomnożony przez wagi w i dodany do skosu by = w * x + b.
A perceptron produkuje pojedyncze wyjście na podstawie kilku wejść o rzeczywistej wartości, tworząc kombinację liniową przy użyciu swoich wag wejściowych (i czasami przepuszczając wyjście przez nieliniową funkcję aktywacji). Oto jak można to zapisać matematycznie:
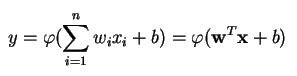
gdzie w oznacza wektor wag, x to wektor wejść, b to skos, a phi to nieliniowa funkcja aktywacji.
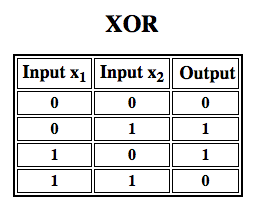
Rosenblatt zbudował perceptron jednowarstwowy. Oznacza to, że jego algorytm sprzętowy nie zawierał wielu warstw, które pozwalają sieciom neuronowym modelować hierarchię cech. Była to więc płytka sieć neuronowa, co uniemożliwiło jego perceptronowi przeprowadzenie nieliniowej klasyfikacji, takiej jak funkcja XOR (operator XOR uruchamia się, gdy dane wejściowe wykazują albo jedną cechę, albo drugą, ale nie obie; skrót od „exclusive OR”), jak wykazali Minsky i Papert w swojej książce.
Zastosuj Reinforcement Learning do symulacji”
Wielowarstwowe perceptrony (MLP)
Późniejsze prace z wielowarstwowymi perceptronami pokazały, że są one w stanie aproksymować operator XOR, jak również wiele innych funkcji nieliniowych.
Tak jak Rosenblatt oparł perceptron na neuronie McCullocha-Pittsa, wymyślonym w 1943 roku, tak i same perceptrony są blokami konstrukcyjnymi, które okazują się przydatne tylko w takich większych funkcjach jak perceptrony wielowarstwowe.2)
Perceptron wielowarstwowy to prawdziwy świat głębokiego uczenia się: dobre miejsce na początek, gdy uczysz się o głębokim uczeniu.
Perceptron wielowarstwowy (MLP) to głęboka, sztuczna sieć neuronowa. Składa się z więcej niż jednego perceptronu. Składają się one z warstwy wejściowej, która odbiera sygnał, warstwy wyjściowej, która podejmuje decyzję lub prognozę na temat danych wejściowych, a pomiędzy tymi dwiema warstwami znajduje się dowolna liczba warstw ukrytych, które są prawdziwym silnikiem obliczeniowym MLP. MLP z jedną warstwą ukrytą są w stanie aproksymować dowolną funkcję ciągłą.
Perceptrony wielowarstwowe są często stosowane do problemów uczenia nadzorowanego3: trenują na zestawie par wejście-wyjście i uczą się modelować korelację (lub zależności) między tymi wejściami i wyjściami. Trening polega na dostosowaniu parametrów, czyli wag i biasów modelu w celu zminimalizowania błędu. Backpropagacja jest używana do dokonywania tych dostosowań wag i biasów w stosunku do błędu, a sam błąd można mierzyć na różne sposoby, w tym za pomocą błędu średniokwadratowego (RMSE).
Sieci o działaniu bezpośrednim, takie jak MLP, są jak tenis lub ping pong. Są one głównie zaangażowane w dwa ruchy, ciągłe tam i z powrotem. Można myśleć o tym ping pongu domysłów i odpowiedzi jako o rodzaju przyspieszonej nauki, ponieważ każdy domysł jest testem tego, co myślimy, że wiemy, a każda odpowiedź jest informacją zwrotną dającą nam znać, jak bardzo się mylimy.
W przejściu do przodu przepływ sygnału odbywa się z warstwy wejściowej przez warstwy ukryte do warstwy wyjściowej, a decyzja warstwy wyjściowej jest mierzona względem etykiet prawdy podstawowej.
W przejściu wstecz, wykorzystując propagację wsteczną i zasadę łańcuchową rachunku, częściowe pochodne funkcji błędu w odniesieniu do różnych wag i uprzedzeń są wstecznie propagowane przez MLP. Ten akt różnicowania daje nam gradient, czyli krajobraz błędu, wzdłuż którego można regulować parametry, przybliżając MLP o jeden krok do minimum błędu. Można to zrobić za pomocą dowolnego algorytmu optymalizacji opartego na gradiencie, takiego jak stochastyczne zejście gradientowe. Sieć kontynuuje grę w tenisa do momentu, gdy błąd nie może spaść niżej. Ten stan jest znany jako konwergencja.
Przypisy
1) Interesującą rzeczą, na którą należy zwrócić uwagę jest to, że oprogramowanie i sprzęt istnieją na schemacie blokowym: oprogramowanie może być wyrażone jako sprzęt i vice versa. Kiedy chipy takie jak FPGA są programowane lub ASIC są konstruowane, by upiec pewien algorytm w krzemie, po prostu implementujemy oprogramowanie o jeden poziom niżej, by działało szybciej. Podobnie to, co jest zapieczone w krzemie lub połączone razem z lampkami i potencjometrami, jak Mark I Rosenblatta, może być również wyrażone symbolicznie w kodzie. To dlatego Alan Kay powiedział: „Ludzie, którzy naprawdę poważnie myślą o oprogramowaniu, powinni tworzyć swój własny sprzęt”. Ale nie ma darmowego lunchu; tzn. to, co zyskujecie na szybkości poprzez zapiekanie algorytmów w krzemie, tracicie na elastyczności, i vice versa. Jest to prawdziwy problem w odniesieniu do uczenia maszynowego, ponieważ algorytmy zmieniają się pod wpływem danych. Wyzwaniem jest znalezienie tych części algorytmu, które pozostają stabilne, nawet gdy zmieniają się parametry; np. operacje algebry liniowej, które są obecnie najszybciej przetwarzane przez procesory graficzne.
2) Twoje myśli mogą skłaniać się ku kolejnemu krokowi w coraz bardziej złożonych, a także bardziej użytecznych algorytmach. Przechodzimy od jednego neuronu do kilku, zwanych warstwami; przechodzimy od jednej warstwy do kilku, zwanych perceptronami wielowarstwowymi. Czy możemy przejść od jednego MLP do kilku, czy też po prostu ciągle zwiększamy liczbę warstw, jak to zrobił Microsoft ze swoim zwycięzcą ImageNet, ResNet, który miał ponad 150 warstw? A może właściwa kombinacja MLP to zespół wielu algorytmów głosujących w swoistej demokracji obliczeniowej nad najlepszym przewidywaniem? Czy też jest to osadzenie jednego algorytmu w drugim, jak to ma miejsce w przypadku sieci konwolucyjnych?
3) Są one szeroko stosowane w Google, które jest prawdopodobnie najbardziej zaawansowaną firmą zajmującą się sztuczną inteligencją na świecie, do szerokiego zakresu zadań, pomimo istnienia bardziej złożonych, najnowocześniejszych metod.
Dalsza lektura
- The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, by Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: Wprowadzenie do geometrii obliczeniowej, Marvina Minsky’ego & Seymoura Paperta
- Multi-Layer Perceptrons (MLP).Layer Perceptrons (MLP)
- Hebbian Theory
Inne posty Pathmind Wiki
- Głębokie sieci neuronowe
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning