Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraudcat or not_cat.
Perceptronen har en särskild plats i historien om neurala nätverk och artificiell intelligens, eftersom den inledande hypen om dess prestanda ledde till ett motargument från Minsky och Papert och en mer omfattande motreaktion som kastade en skugga över forskningen om neurala nätverk i flera decennier, en vinter för neurala nätverk som helt och hållet tinades upp först med Geoff Hintons forskning på 2000-talet, vars resultat sedan dess har svept över samhället för maskininlärning.
Frank Rosenblatt, perceptrons gudfader, populariserade den som en anordning snarare än en algoritm. Perceptronen kom först ut i världen som hårdvara.1 Rosenblatt, en psykolog som studerade och senare föreläste vid Cornell University, fick medel från U.S. Office of Naval Research för att bygga en maskin som kunde lära sig. Hans maskin, Mark I-perceptronen, såg ut så här.

En perceptron är en linjär klassificerare, det vill säga en algoritm som klassificerar indata genom att separera två kategorier med en rak linje. Indata är vanligtvis en funktionsvektor x som multipliceras med vikter w och läggs till en bias by = w * x + b.
En perceptron producerar ett enda utdata baserat på flera realvärderade ingångar genom att bilda en linjär kombination med hjälp av ingångsvikterna (och ibland genom att låta utdata passera genom en icke-linjär aktiveringsfunktion). Så här kan du skriva det i matematik:
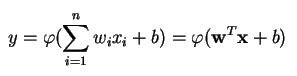
där w betecknar vektorn av vikter, x är vektorn av ingångar, b är förspänningen och phi är den icke-linjära aktiveringsfunktionen.
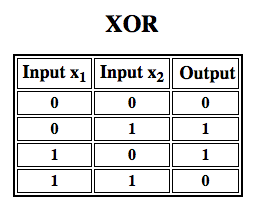
Rosenblatt byggde en perceptron med ett lager. Det innebär att hans hårdvaru-algoritm inte innehöll flera lager, vilket gör det möjligt för neurala nätverk att modellera en funktionshierarki. Det var därför ett ytligt neuralt nätverk, vilket hindrade hans perceptron från att utföra icke-linjär klassificering, t.ex. XOR-funktionen (en XOR-operator utlöses när indata uppvisar antingen en egenskap eller en annan, men inte båda; den står för ”exclusive OR”), vilket Minsky och Papert visade i sin bok.
Applicera förstärkningsinlärning på simuleringar ”
Multilayer Perceptrons (MLP)
Efterföljande arbete med multilayer perceptrons har visat att de kan närma sig en XOR-operator samt många andra icke-linjära funktioner.
Såväl som Rosenblatt baserade perceptronen på en McCulloch-Pitts neuron, som utformades 1943, är perceptroner i sig själva byggstenar som bara visar sig vara användbara i sådana större funktioner som flerskikts-perceptroner2.)
Månglagersperceptronen är djupinlärningens hejduktiga värld: en bra plats att börja på när du lär dig om djupinlärning.
En flerlagersperceptron (MLP) är ett djupt, artificiellt neuralt nätverk. Det består av mer än en perceptron. De består av ett ingångslager som tar emot signalen, ett utgångslager som fattar ett beslut eller gör en förutsägelse om ingången och däremellan ett godtyckligt antal dolda lager som är MLP:s verkliga beräkningsmotor. MLP med ett dolt lager kan approximera vilken kontinuerlig funktion som helst.
Multilayer Perceptrons tillämpas ofta på övervakade inlärningsproblem3: de tränas på en uppsättning inmatnings- och utmatningspar och lär sig att modellera korrelationen (eller beroendet) mellan dessa inmatningar och utmatningar. Träning innebär att man justerar modellens parametrar, eller vikter och bias, för att minimera felet. Backpropagation används för att göra dessa justeringar av vikter och bias i förhållande till felet, och själva felet kan mätas på olika sätt, bland annat genom root mean squared error (RMSE).
Feedforward-nätverk som MLP:s är som tennis, eller ping pong. De är huvudsakligen involverade i två rörelser, en konstant fram och tillbaka. Man kan se denna ping pong av gissningar och svar som ett slags accelererad vetenskap, eftersom varje gissning är ett test av vad vi tror att vi vet, och varje svar är en återkoppling som låter oss veta hur fel vi har.
I det framåtriktade passet rör sig signalflödet från inmatningsskiktet genom de dolda skikten till utmatningsskiktet, och utmatningsskiktets beslut mäts mot de verkliga etiketterna.
I det bakåtriktade passet, med hjälp av backpropagation och kalkylens kedjeledningsregel, återförs partiella derivat av felfunktionen i förhållande till de olika vikterna och förskjutningarna genom MLP:en. Denna differentiering ger oss en gradient, eller ett fellandskap, längs vilket parametrarna kan justeras för att föra MLP ett steg närmare felminimum. Detta kan göras med vilken gradientbaserad optimeringsalgoritm som helst, t.ex. stokastisk gradientnedgång. Nätverket fortsätter att spela detta tennisspel tills felet inte kan sänkas. Detta tillstånd kallas konvergens.
Fotnoter
1) Det intressanta att påpeka här är att mjukvara och hårdvara existerar på ett flödesschema: mjukvara kan uttryckas som hårdvara och vice versa. När chip som FPGA:er programmeras eller ASIC:er konstrueras för att baka in en viss algoritm i kisel, implementerar vi helt enkelt programvara en nivå lägre för att få den att fungera snabbare. På samma sätt kan det som bakas in i kisel eller kopplas ihop med lampor och potentiometrar, som Rosenblatts Mark I, också uttryckas symboliskt i kod. Detta är anledningen till att Alan Kay har sagt: ”Människor som verkligen menar allvar med mjukvara bör göra sin egen hårdvara”. Men det finns ingen gratis lunch, dvs. vad man vinner i snabbhet genom att baka in algoritmer i kisel förlorar man i flexibilitet, och vice versa. Detta råkar vara ett verkligt problem när det gäller maskininlärning, eftersom algoritmerna ändrar sig själva genom att exponeras för data. Utmaningen är att hitta de delar av algoritmen som förblir stabila även när parametrarna ändras; t.ex. de linjära algebraoperationer som för närvarande behandlas snabbast av GPU:er.
2) Dina tankar kanske lutar mot nästa steg i allt mer komplexa och även mer användbara algoritmer. Vi går från en neuron till flera, som kallas lager; vi går från ett lager till flera, som kallas flerskiktsperceptron. Kan vi gå från en MLP till flera, eller måste vi helt enkelt fortsätta att stapla lager på lager, som Microsoft gjorde med sin ImageNet-vinnare, ResNet, som hade mer än 150 lager? Eller är den rätta kombinationen av MLP:er en ensemble av många algoritmer som röstar i ett slags datademokrati om den bästa förutsägelsen? Eller är det att bädda in en algoritm i en annan, som vi gör med grafkonvolutionella nätverk?
3) De används i stor utsträckning på Google, som förmodligen är det mest sofistikerade AI-företaget i världen, för ett brett spektrum av uppgifter, trots att det finns mer komplexa, toppmoderna metoder.
Fördjupad läsning
- Perceptronen: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, av Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: En introduktion till beräkningsgeometri, av Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Hebbian Theory
Andra Pathmind Wiki inlägg
- Deep Neural Networks
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning