Slutet av oktober förra året meddelade Google att ett av dessa chip, kallat Sycamore, hade blivit det första att demonstrera ”kvantöverlägsenhet” genom att utföra en uppgift som skulle vara praktiskt taget omöjlig på en klassisk maskin. Med bara 53 qubits hade Sycamore genomfört en beräkning på några minuter som enligt Google skulle ha tagit världens kraftfullaste befintliga superdator, Summit, 10 000 år. Google framhöll detta som ett stort genombrott och jämförde det med uppskjutningen av Sputnik eller bröderna Wrights första flygning – tröskeln till en ny era av maskiner som skulle få dagens mäktigaste dator att se ut som ett abakus.
På en presskonferens i labbet i Santa Barbara svarade Google-teamet glatt på frågor från journalister i nästan tre timmar. Men deras goda humör kunde inte riktigt dölja en underliggande spänning. Två dagar tidigare hade forskare från IBM, Googles ledande rival inom kvantdatorer, torpederat det stora avslöjandet. De hade publicerat en artikel som i huvudsak anklagade Googler för att ha räknat fel. IBM räknade med att det skulle ha tagit Summit bara dagar, inte årtusenden, att kopiera vad Sycamore hade gjort. På frågan om vad han tyckte om IBM:s resultat undvek Hartmut Neven, chef för Googles team, att ge ett direkt svar.

Du skulle kunna avfärda detta som ett akademiskt gräl – och på sätt och vis var det det. Även om IBM hade rätt hade Sycamore ändå gjort beräkningen tusen gånger snabbare än vad Summit skulle ha gjort. Och det skulle troligen bara dröja några månader innan Google byggde en något större kvantmaskin som bevisade poängen bortom allt tvivel.
IBM:s djupare invändning var dock inte att Googles experiment var mindre lyckat än vad som hävdades, utan att det överhuvudtaget var ett meningslöst test. Till skillnad från de flesta i kvantdatorvärlden tror IBM inte att ”kvantöverlägsenhet” är teknikens Wright brothers-ögonblick; i själva verket tror man inte ens att det kommer att bli ett sådant ögonblick.
IBM jagar i stället ett helt annat mått på framgång, något man kallar ”kvantfördel”. Detta är inte bara en skillnad i ord eller ens i vetenskap, utan ett filosofiskt ställningstagande med rötter i IBM:s historia, kultur och ambitioner – och, kanske, det faktum att IBM:s intäkter och vinst i åtta år har minskat nästan oavbrutet, medan Google och dess moderbolag Alphabet bara har fått se sina siffror öka. Detta sammanhang och dessa olika mål kan påverka vem – om någon av dem – som kommer att vinna i kvantdatorracet.
Världar åtskilda
Den eleganta, svepande kurvan på IBM:s Thomas J. Watson Research Center i förorten norr om New York, ett neofuturistiskt mästerverk av den finländske arkitekten Eero Saarinen, är en kontinent och ett universum bort från Googlegruppens obestämda lokaler. Det färdigställdes 1961 med hjälp av de pengar som IBM tjänade på att bygga stordatorer och har en museal kvalitet, en påminnelse för alla som arbetar där om företagets genombrott inom allt från fraktal geometri till supraledare till artificiell intelligens – och kvantdatorer.
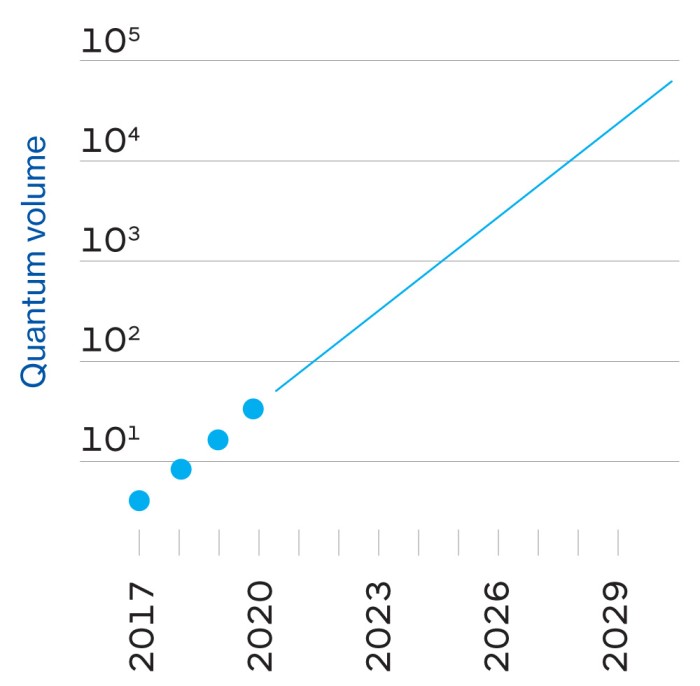
Den som leder den 4 000 personer starka forskningsavdelningen är Dario Gil, en spanjor vars snabba tal är en tävling för att hålla jämna steg med hans nästan evangeliska iver. Båda gångerna jag talade med honom rabblade han upp historiska milstolpar som syftade till att understryka hur länge IBM har varit involverat i kvantdatorrelaterad forskning (se tidslinje till höger).


Ett stort experiment: Kvantteori och praktik
En kvantdators grundläggande byggsten är kvantbiten, eller qubit. I en klassisk dator kan en bit lagra antingen 0 eller 1. En kvantbit kan lagra inte bara 0 eller 1 utan även ett mellanliggande tillstånd som kallas superposition – som kan anta många olika värden. En analogi är att om information vore färg, skulle en klassisk bit kunna vara antingen svart eller vit. En qubit som befinner sig i superposition kan vara vilken färg som helst i spektrumet och kan även variera i ljusstyrka.
Resultatet är att en qubit kan lagra och bearbeta en stor mängd information jämfört med en bit – och kapaciteten ökar exponentiellt när man kopplar ihop qubits med varandra. Att lagra all information i de 53 kvbitarna på Googles Sycamore-chip skulle ta ungefär 72 petabyte (72 miljarder gigabyte) av klassiskt datorminne i anspråk. Det krävs inte många fler qubits innan man skulle behöva en klassisk dator lika stor som planeten.
Men det är inte okomplicerat. Kvittenbitar är känsliga och lätt störda och måste därför vara nästan perfekt isolerade från värme, vibrationer och vilsna atomer – därav kylskåpen i Googles kvantlaboratorium. Även då kan de fungera i högst några hundra mikrosekunder innan de ”dekohererar” och förlorar sin superposition.
Och kvantdatorer är inte alltid snabbare än klassiska datorer. De är bara olika, snabbare på vissa saker och långsammare på andra, och kräver olika typer av programvara. För att jämföra deras prestanda måste man skriva ett klassiskt program som ungefär simulerar kvantdatorn.
För sitt experiment valde Google ett benchmarking-test som kallas ”random quantum circuit sampling”. Det genererar miljontals slumpmässiga tal, men med små statistiska förskjutningar som är ett kännetecken för kvantalgoritmen. Om Sycamore var en fickräknare skulle det motsvara att trycka på slumpmässiga knappar och kontrollera att displayen visade de förväntade resultaten.
Google simulerade delar av detta på sina egna massiva serverfarmar samt på Summit, världens största superdator, vid Oak Ridge National Laboratory. Forskarna uppskattade att slutförandet av hela jobbet, som tog Sycamore 200 sekunder, skulle ha tagit Summit ungefär 10 000 år. Voilà: kvantöverlägsenhet.
Så vad var IBM:s invändning? I grund och botten att det finns olika sätt att få en klassisk dator att simulera en kvantmaskin – och att programvaran du skriver, hur du hackar upp data och lagrar dem, och den hårdvara du använder, alla gör stor skillnad för hur snabbt simuleringen kan köras. IBM sade att Google antog att simuleringen skulle behöva delas upp i många bitar, men Summit, med 280 petabyte lagringsutrymme, är tillräckligt stort för att rymma hela Sycamore-tillståndet på en gång. (Och IBM byggde Summit, så det borde veta.)
Men under årtiondenas lopp har företaget fått ett rykte om sig att kämpa för att omvandla sina forskningsprojekt till kommersiella framgångar. Ta, senast, Watson, den Jeopardy!-spelande AI som IBM försökte omvandla till en medicinsk robotguru. Den var tänkt att ge diagnoser och identifiera trender i oceaner av medicinska data, men trots dussintals partnerskap med vårdgivare har det funnits få kommersiella tillämpningar, och även de som kommit fram har gett blandade resultat.
Vil säger att teamet för kvantdatorer försöker bryta denna cykel genom att bedriva forskning och affärsutveckling parallellt. Nästan så snart de hade fungerande kvantdatorer började de göra dem tillgängliga för utomstående genom att lägga dem i molnet, där de kan programmeras med hjälp av ett enkelt dra-och-släpp-gränssnitt som fungerar i en webbläsare. ”IBM Q Experience”, som lanserades 2016, består nu av 15 allmänt tillgängliga kvantdatorer med en storlek på mellan fem och 53 qubits. Cirka 12 000 personer per månad använder dem, allt från akademiska forskare till skolungdomar. Det är gratis att använda de mindre maskinerna; IBM säger att det redan finns mer än 100 kunder som betalar (företaget vill inte säga hur mycket) för att använda de större maskinerna.
Ingen av dessa enheter – eller någon annan kvantdator i världen, med undantag för Googles Sycamore – har ännu visat att den kan slå en klassisk maskin på något sätt. För IBM är det inte poängen just nu. Genom att göra maskinerna tillgängliga online kan företaget lära sig vad framtida kunder kan tänkas behöva av dem och utomstående programvaruutvecklare kan lära sig att skriva kod för dem. Detta bidrar i sin tur till utvecklingen av dem och gör efterföljande kvantdatorer bättre.
Denna cykel är enligt företaget den snabbaste vägen till den så kallade kvantfördelen, en framtid där kvantdatorer inte nödvändigtvis kommer att överträffa de klassiska datorerna, men där de kommer att göra vissa användbara saker något snabbare eller effektivare – tillräckligt för att göra dem ekonomiskt lönsamma. Medan kvantöverlägsenhet är en enda milstolpe är kvantfördelen ett ”kontinuum”, säger IBM:arna – en gradvis växande värld av möjligheter.
Detta är alltså Gils stora enhetliga teori om IBM: att företaget genom att kombinera sitt arv, sin tekniska expertis, andras hjärnkapacitet och sin hängivenhet för företagskunderna kan bygga användbara kvantdatorer snabbare och bättre än någon annan.
I denna syn på saken ser IBM Googles demonstration av kvantöverlägsenhet som ”ett trick”, säger Scott Aaronson, fysiker vid University of Texas i Austin, som har bidragit till de kvantalgoritmer som Google använder. I bästa fall är det en flashig distraktion från det verkliga arbete som måste utföras. I värsta fall är det vilseledande, eftersom det kan få människor att tro att kvantdatorer kan slå klassiska datorer på vad som helst snarare än på en mycket smal uppgift. ”’Supremacy’ är ett engelskt ord som det kommer att bli omöjligt för allmänheten att inte misstolka”, säger Gil.
Google ser naturligtvis på saken på ett helt annat sätt.
Enter the upstart
Google var ett tidigt åttaårigt företag när det började pyssla med kvantproblem 2006, men det bildade inte ett särskilt kvantlaboratorium förrän 2012 – samma år som John Preskill, fysiker vid Caltech, myntade termen ”quantum supremacy”.”
Labbets chef är Hartmut Neven, en tysk datavetare med en imponerande närvaro och en förkärlek för chic i Burning Man-stil. Jag såg honom en gång i en blå päls och en annan gång i en helt silverfärgad outfit som fick honom att se ut som en grinig astronaut. (”Min fru köper dessa saker åt mig”, förklarade han.) Till en början köpte Neven en maskin byggd av ett externt företag, D-Wave, och tillbringade ett tag med att försöka uppnå kvantöverlägsenhet på den, men utan att lyckas. Han säger att han övertalade Larry Page, Googles dåvarande vd, att investera i att bygga kvantdatorer 2014 genom att lova honom att Google skulle ta sig an Preskills utmaning: ”Vi sa till honom: ’Lyssna, Larry, om tre år kommer vi tillbaka och lägger en prototyp av ett chip på ditt bord som åtminstone kan beräkna ett problem som ligger bortom de klassiska maskinernas förmågor.'”
I avsaknad av IBM:s kvantkompetens anlitade Google ett team utifrån, som leddes av John Martinis, en fysiker vid University of California, Santa Barbara. Martinis och hans grupp var redan bland världens bästa kvantdatortillverkare – de hade lyckats koppla samman upp till nio qubits – och Nevens löfte till Page verkade vara ett värdigt mål för dem att sikta på.
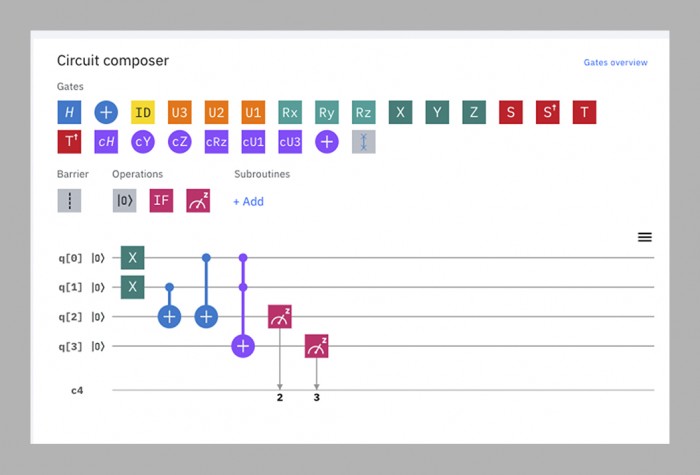
Den treåriga tidsfristen kom och gick medan Martinis grupp kämpade för att tillverka ett chip som var tillräckligt stort och stabilt för utmaningen. År 2018 släppte Google sin största processor hittills, Bristlecone. Med 72 qubits låg den långt före allt som konkurrenterna hade gjort, och Martinis förutspådde att den skulle nå kvantöverlägsenhet samma år. Men några av gruppmedlemmarna hade arbetat parallellt med en annan chiparkitektur, kallad Sycamore, som i slutändan visade sig kunna göra mer med färre qubits. Därför var det ett chip med 53 qubits – ursprungligen 54, men en av dem fungerade dåligt – som i slutändan demonstrerade överlägsenhet i höstas.
För praktiska ändamål är det program som användes i den demonstrationen praktiskt taget värdelöst – det genererar slumpmässiga tal, vilket inte är något man behöver en kvantdator för. Men det genererar dem på ett särskilt sätt som en klassisk dator skulle ha mycket svårt att replikera, och därigenom upprättades beviset för konceptet (se motsatt sida).
Fråga IBM:are vad de tycker om denna bedrift, och du får smärtsamma blickar. ”Jag gillar inte ordet , och jag gillar inte konsekvenserna”, säger Jay Gambetta, en försiktigt talande australiensare som leder IBM:s kvantteam. Problemet, säger han, är att det är praktiskt taget omöjligt att förutsäga om en viss kvantberäkning kommer att vara svår för en klassisk maskin, så att visa det i ett fall hjälper dig inte att hitta andra fall.
För alla jag talade med utanför IBM gränsar denna vägran att betrakta kvantöverlägsenhet som betydelsefull till tjurskallighet. ”Alla som någonsin kommer att ha ett kommersiellt relevant erbjudande – de måste visa överlägsenhet först. Jag tror att det är grundläggande logik”, säger Neven. Till och med Will Oliver, en milt manadrerad fysiker från MIT som har varit en av de mest opartiska observatörerna av bråket, säger: ”Det är en mycket viktig milstolpe att visa att en kvantdator presterar bättre än en klassisk dator på någon uppgift, oavsett vad det är.”
Kvantsprånget
Oavsett om man håller med om Googles eller IBM:s ståndpunkt är nästa mål tydligt, säger Oliver: att bygga en kvantdator som kan göra något användbart. Förhoppningen är att sådana maskiner en dag skulle kunna lösa problem som nu kräver ogenomförbara mängder av brutal datorkraft, som att modellera komplexa molekyler för att hjälpa till att upptäcka nya läkemedel och material, eller att optimera trafikflöden i städer i realtid för att minska trafikstockningar, eller att göra väderprognoser på längre sikt. (Så småningom kanske de kan knäcka de kryptografiska koder som används i dag för att säkra kommunikation och finansiella transaktioner, även om större delen av världen då förmodligen kommer att ha infört kvantresistent kryptografi). Problemet är att det är nästan omöjligt att förutsäga vad den första användbara uppgiften kommer att bli, eller hur stor en dator som kommer att behövas för att utföra den.
Denna osäkerhet har att göra med både hårdvara och mjukvara. På hårdvarusidan räknar Google med att dess nuvarande chippkonstruktioner kan få det till någonstans mellan 100 och 1 000 qubits. Men precis som en bils prestanda inte bara beror på storleken på motorn, bestäms en kvantdators prestanda inte bara av antalet qubits. Det finns en rad andra faktorer att ta hänsyn till, bland annat hur länge de kan hållas från att dekoherera, hur felbenägna de är, hur snabbt de fungerar och hur de är sammankopplade. Detta innebär att varje kvantdator som fungerar i dag endast når en bråkdel av sin fulla potential.
Mjukvaran för kvantdatorer befinner sig under tiden lika mycket i sin linda som själva maskinerna. Inom klassisk databehandling är programmeringsspråken nu flera nivåer bort från den råa ”maskinkod” som tidiga programvaruutvecklare var tvungna att använda, eftersom de små detaljerna i hur data lagras, bearbetas och flyttas runt redan är standardiserade. ”När du programmerar en klassisk dator behöver du inte veta hur en transistor fungerar”, säger Dave Bacon, som leder Google-teamets programvaruarbete. Kvantkod måste å andra sidan vara mycket skräddarsydd för de qubits som den ska köras på, så att man kan få ut det mesta av deras temperamentsfulla prestanda. Det innebär att koden för IBM:s chip inte kommer att fungera på andra företags chip, och även tekniker för att optimera Googles Sycamore med 53 kvbits kommer inte nödvändigtvis att fungera bra på dess framtida syskon med 100 kvbits. Ännu viktigare är att ingen kan förutsäga hur svåra problem som dessa 100 qubits kommer att kunna lösa.
Det mesta man vågar hoppas på är att datorer med några hundra qubits kommer att kunna simulera någon måttligt komplex kemi inom de närmaste åren – kanske till och med tillräckligt för att främja sökandet efter ett nytt läkemedel eller ett effektivare batteri. Men dekoherens och fel kommer att få alla dessa maskiner att stanna innan de kan göra något riktigt svårt som att bryta kryptografi.
För att bygga en kvantdator med kraften hos 1 000 qubits skulle man behöva en miljon verkliga qubits.
Det kommer att kräva en ”feltolerant” kvantdator, en som kan kompensera för fel och hålla sig igång på obestämd tid, precis som klassiska datorer gör. Den förväntade lösningen kommer att vara att skapa redundans: få hundratals qubits att agera som en enda, i ett delat kvanttillstånd. Tillsammans kan de korrigera enskilda qubits fel. Och när varje qubit faller till föga för dekoherens kommer dess grannar att väcka den till liv igen, i en oändlig cykel av ömsesidig återupplivning.
Den typiska förutsägelsen är att det skulle krävas så många som 1 000 sammanfogade qubits för att uppnå den stabiliteten – vilket innebär att för att bygga en dator med kraften hos 1 000 qubits skulle man behöva en miljon verkliga qubits. Google uppskattar ”konservativt” att man kan bygga en processor med en miljon qubits inom tio år, säger Neven, även om det finns några stora tekniska hinder att övervinna, bland annat ett där IBM kan ha ett försprång framför Google (se motsatt sida).
I samband med detta kan mycket ha förändrats. De supraledande qubits som Google och IBM för närvarande använder kan visa sig vara sin tids vakuumrör, ersatta av något mycket stabilare och mer tillförlitligt. Forskare runt om i världen experimenterar med olika metoder för att göra qubits, även om få är tillräckligt avancerade för att bygga fungerande datorer med. Rivaliserande nystartade företag som Rigetti, IonQ eller Quantum Circuits kan utveckla ett försprång i en viss teknik och hoppa över de större företagen.
En berättelse om två transmons
Googles och IBM:s transmon-qubits är nästan identiska, med en liten men potentiellt avgörande skillnad.
I både Googles och IBM:s kvantdatorer styrs själva qubitsen av mikrovågsimpulser. Små tillverkningsfel gör att inte två qubits reagerar på pulser med exakt samma frekvens. Det finns två lösningar på detta: variera frekvensen på pulserna för att hitta varje qubits bästa plats, som att röra på en dåligt utklippt nyckel i ett lås tills den öppnas, eller använda magnetfält för att ”ställa in” varje qubit på rätt frekvens.
IBM använder den första metoden, Google använder den andra. Varje metod har fördelar och nackdelar. Googles avstämbara qubits fungerar snabbare och mer exakt, men de är mindre stabila och kräver mer kretsar. IBM:s qubits med fast frekvens är stabilare och enklare, men fungerar långsammare.
Från en teknisk synvinkel är det ganska mycket en uppgörelse, åtminstone i det här skedet. När det gäller företagsfilosofi är det dock skillnaden mellan Google och IBM i ett nötskal – eller snarare i en qubit.
Google valde att vara smidig. ”I allmänhet går vår filosofi lite mer mot högre kontrollerbarhet på bekostnad av de siffror som folk vanligtvis letar efter”, säger Hartmut Neven.
IBM, å andra sidan, valde tillförlitlighet. ”Det är en stor skillnad mellan att göra ett laboratorieexperiment och publicera en artikel och att sätta upp ett system med en tillförlitlighet på 98 procent där man kan köra det hela tiden”, säger Dario Gil.
Redan nu har Google ett övertag. När maskinerna blir större kan dock fördelen vända till IBM. Varje qubit styrs av sina egna individuella trådar; en inställbar qubit kräver en extra tråd. Att hitta ledningar för tusentals eller miljontals qubits kommer att vara en av de svåraste tekniska utmaningarna för de två företagen; IBM säger att det är en av anledningarna till att de valde en qubit med fast frekvens. Martinis, chef för Google-teamet, säger att han personligen har tillbringat de senaste tre åren med att försöka hitta ledningslösningar. ”Det är ett så viktigt problem att jag arbetade med det”, skämtar han.
Men med tanke på deras storlek och förmögenhet har både Google och IBM en chans att bli seriösa aktörer inom kvantdatorbranschen. Företagen kommer att hyra deras maskiner för att lösa problem på samma sätt som de för närvarande hyr molnbaserad datalagring och processorkraft från Amazon, Google, IBM eller Microsoft. Och det som började som en kamp mellan fysiker och datavetare kommer att utvecklas till en tävling mellan affärstjänstavdelningar och marknadsavdelningar.
Vilket företag har bäst förutsättningar att vinna den tävlingen? IBM, med sina sjunkande intäkter, kanske har en större känsla av brådska än Google. IBM vet av bitter erfarenhet vad det kostar att vara långsam att ta sig in på en marknad: i somras, i sitt dyraste köp någonsin, gav företaget 34 miljarder dollar för Red Hat, en leverantör av molntjänster med öppen källkod, i ett försök att komma ikapp Amazon och Microsoft på det området och vända sin ekonomiska utveckling. Företagets strategi att placera sina kvantmaskiner i molnet och bygga upp en betalande verksamhet från början verkar vara utformad för att ge företaget ett försprång.
Google började nyligen följa IBM:s exempel, och bland dess kommersiella kunder finns nu det amerikanska energidepartementet, Volkswagen och Daimler. Anledningen till att man inte gjorde detta tidigare, säger Martinis, är enkel: ”Vi hade inte resurserna för att lägga det i molnet.” Men det är ett annat sätt att säga att företaget hade lyxen att inte behöva prioritera affärsutveckling.
Om det beslutet ger IBM en fördel är för tidigt att säga, men viktigare är förmodligen hur de två företagen tillämpar sina andra styrkor på problemet under de kommande åren. Enligt Gil kommer IBM att dra nytta av sin expertis inom allt från materialvetenskap och chiptillverkning till att betjäna stora företagskunder. Google, å andra sidan, kan skryta med sin innovationskultur i stil med Silicon Valley och sin erfarenhet av att snabbt skala upp verksamheten.
När det gäller kvantöverlägsenhet i sig självt kommer det att vara ett viktigt ögonblick i historien, men det betyder inte att det kommer att vara avgörande. After all, everyone knows about the Wright brothers’ first flight, but can anybody remember what they did afterwards?
Sign inSubscribe now