Det kan vara skrämmande och svårt att upptäcka teman i kvalitativa data. Att sammanfatta en kvantitativ studie är relativt tydligt: du fick 25 % bättre resultat än konkurrenterna, låt oss säga. Men hur sammanfattar man en samling kvalitativa observationer?
I de tidiga skedena av ett projekt utförs ofta explorativ forskning. Denna forskning ger ofta upphov till en mängd kvalitativa data, som kan omfatta följande:
Kvalitativa attityddata, t.ex. människors tankar, övertygelser och självrapporterade behov som erhålls från användarintervjuer, fokusgrupper och till och med dagboksstudier
Kvalitativa beteendedata, som t.ex. observationer om människors beteende som samlas in genom kontextuell undersökning och andra etnografiska metoder
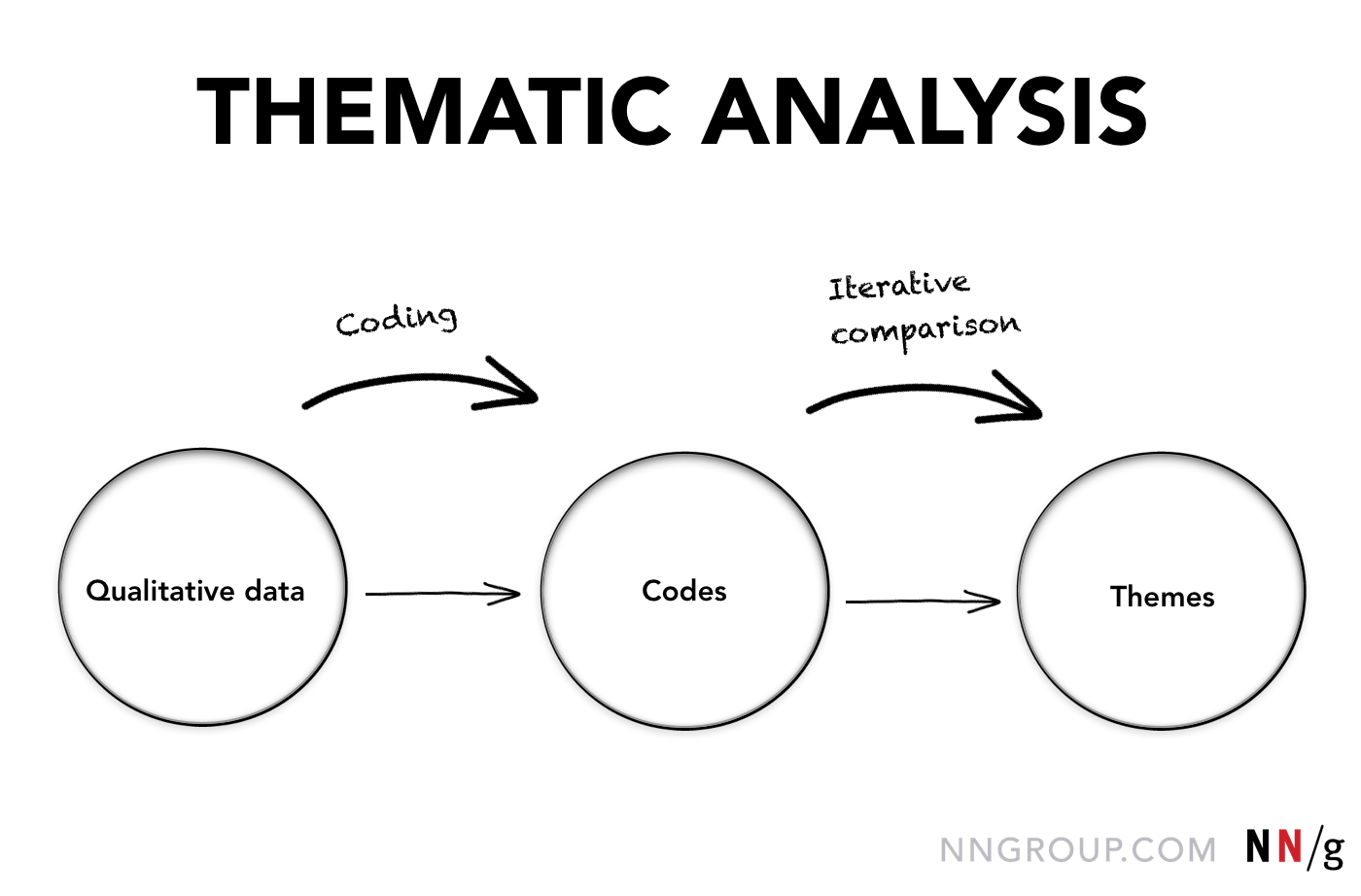
Tematisk analys, som vem som helst kan göra, synliggör viktiga aspekter av kvalitativa data och gör det lättare att upptäcka teman.
- Vad är en tematisk analys?
- Utmaningar med att analysera kvalitativa data
- Verktyg och metoder för att genomföra en tematisk analys
- Användning av programvara
- Journalföring
- Affinity-Diagramming Techniques
- Koder och kodning
- Kodtyper: Beskrivande och tolkande
- Steg för att genomföra en tematisk analys
- Steg 1: Samla in alla dina data
- Steg 2: Läs alla dina data från början till slut
- Steg 3: Kodera texten utifrån vad den handlar om
- Traditionell metod: I den traditionella metoden skapar du koder när du markerar segment av data, t.ex. meningar, stycken, fraser, när du markerar dem. Det är bra att föra ett register över alla koder som används och beskriva vad de är, så att du kan hänvisa till denna lista när du kodar ytterligare avsnitt av texten (särskilt om flera personer kodar texten). På detta sätt undviker man att skapa flera koder (som senare måste konsolideras) för samma typ av fråga.
- Snabbmetod: Gruppera textavsnitt och tilldela sedan en kod
- Steg 4: Skapa nya koder som kapslar in potentiella teman
- Steg 5: Ta en paus en dag och återvänd sedan till uppgifterna
- Steg 6: Utvärdera dina teman för att se om de passar ihop
- Slutsats
Vad är en tematisk analys?
Definition: Tematisk analys är en systematisk metod för att bryta ner och organisera rika data från kvalitativ forskning genom att märka enskilda observationer och citat med lämpliga koder, för att underlätta upptäckten av viktiga teman.
Som namnet antyder innebär en tematisk analys att man hittar teman.
Definition: Ett tema:
- är en beskrivning av en trosuppfattning, en praxis, ett behov eller ett annat fenomen som upptäcks från data
- kommer fram när relaterade resultat dyker upp flera gånger bland deltagare eller datakällor
Utmaningar med att analysera kvalitativa data
Många forskare känner sig överväldigade av kvalitativa data från utforskande forskning som utförs i de tidiga stadierna av ett projekt. Tabellen nedan belyser några vanliga utmaningar och resulterande problem.
| CHALLENGES | RESULTING ISSUES | |
|
Large quantity of data: Qualitative research results in long transcripts and extensive field notes that can be time-consuming to read; you may have a hard time seeing patterns and remembering what’s important. |
Superficial analysis: Analysis is often done very superficially, just skimming topics, focusing on only memorable events and quotes, and missing large sections of notes. |
|
|
Rich data: There are lots of detail within every sentence or paragraph. It can be hard to see which details are useful and which are superfluous. |
Analysis becomes a description of many details: The analysis simply becomes a regurgitation of what participants’ may have said or done, without any analytical thinking applied to it. |
|
|
Contradicting data: Ibland innehåller data från olika deltagare eller till och med från samma deltagare motsägelser som forskarna måste förstå. |
Fynd är inte definitiva: Analysen är inte definitiv eftersom deltagarnas återkoppling är motsägelsefull eller, ännu värre, synpunkter som inte stämmer överens med forskarens övertygelse ignoreras. |
|
| Inga uppsatta mål för analysen: Målen för den första datainsamlingen går förlorade eftersom forskaren lätt kan bli alltför uppslukad av detaljerna. | Slöseri med tid och felriktad analys: Analysen saknar fokus och forskningen rapporterar om fel saker. |
Om det inte finns någon form av systematisk process uppstår de problem som beskrivits lätt vid analys av kvalitativa data. En tematisk analys håller forskarna organiserade och fokuserade och ger dem en allmän process att följa när de analyserar kvalitativa data.
Verktyg och metoder för att genomföra en tematisk analys
En tematisk analys kan göras på många olika sätt. Det bästa verktyget eller den bästa metoden för denna process bestäms utifrån:
- data
- kontext och begränsningar för dataanalysfasen
- forskarens personliga arbetssätt
3 vanliga metoder är bland annat:
- Användning av programvara
- Journalföring
- Användning av affinitetsdiagramtekniker
Användning av programvara
För att analysera stora mängder kvalitativa data använder sig kvalitativa forskare ofta av programvara, känd som CAQDAS (Computer-Aided Qualitative-Data-Analysis software) – uttalas ”cak∙das”. Forskarna laddar upp utskrifter och fältanteckningar i ett program och analyserar sedan texten systematiskt genom formell kodning. Programvaran hjälper till att upptäcka teman genom att erbjuda olika visualiseringsverktyg, t.ex. ordträd eller ordmoln, som gör det möjligt att manipulera de kodade uppgifterna på många olika sätt.
Fördelar
- Analysen är mycket grundlig.
- En fysisk projektfil (som innehåller rådata och analys) kan delas med andra. (Denna metod är populär i studentprojekt vid akademiska institutioner.)
Nackdelar
- Tidskrävande, eftersom det resulterar i många koder som måste kondenseras till en liten, hanterbar lista
- Dyrt
- Svårt att analysera med andra synkront
- Kräver viss inlärning av programvaran
- Kan kännas begränsande
Journalföring
Att skriva ner tankeprocesser och idéer som man har om en text är vanligt bland forskare som praktiserar grounded-theory-metodik. Journaling as a form of thematic analysis is based on this methodology and involves manual annotation and highlighting of the data, followed by writing down the researchers’ ideas and thought processes. The notes are known as memos (not to be confused with the office memo delivering news to employees).
Benefits
- The process encourages reflection through the writing of detailed notes.
- Researchers have a record of how they arrived at their themes.
- The analysis is cheap and flexible.
Drawbacks
- Hard to do collaboratively
Affinity-Diagramming Techniques
The data is highlighted, cut out physically or digitally, and reassembled into meaningful groups until themes emerge on a physical or digital board. (See a video demonstrating affinity-diagramming.)
Benefits
- Can be done collaboratively
- Quick arriving at themes
- Cheap and flexible
- Visual, och stöder en iterativ analysprocess
Nackdelar
- Inte lika grundligt som andra metoder eftersom textsegment ofta inte kodas flera gånger
- Svårt att göra när data är mycket varierande, eller om det finns mycket data
Koder och kodning
Alla metoder för tematisk analys förutsätter ett visst mått av kodning (inte att förväxla med att skriva ett program i ett programmeringsspråk).
Definition: En kod är ett ord eller en fras som fungerar som en etikett för ett textsegment.
En kod beskriver vad texten handlar om och är en förkortning för mer komplicerad information. (En bra analogi är att en kod beskriver data på samma sätt som ett nyckelord beskriver en artikel eller som en hashtag beskriver en tweet). Ofta har kvalitativa forskare inte bara ett namn för varje kod utan också en beskrivning av vad koden betyder och exempel på text som passar eller inte passar koden. Dessa beskrivningar och exempel är särskilt användbara om fler än en person ansvarar för kodningen av data eller om kodningen sker under en längre tidsperiod.
Definition: Kodning: Med kodning avses processen att märka textsegment med lämpliga koder.
När koder har tilldelats är det lätt att identifiera och jämföra textsegment som handlar om samma sak. Med hjälp av koderna kan vi enkelt sortera information och analysera data för att avslöja likheter, skillnader och relationer mellan segmenten. Vi kan då komma fram till en förståelse för de väsentliga temana.
Kodtyper: Beskrivande och tolkande
Koder kan vara:
- Beskrivande: De beskriver vad uppgifterna handlar om
- Tolkande:
För att se exempel på beskrivande och tolkande koder kan vi titta på ett citat från en intervju som jag gjorde med en UX-praktiker tidigare i år (som en del av vår forskning om UX Careers, som kommer att publiceras i vår rapport UX Careers).
”Jag var förstenad när det gällde att underlätta ett möte och mitt företag erbjöd en dag och en halv lång kurs. Så jag gick dit och instruktören gjorde något som jag tyckte var hemskt vid den tidpunkten, men jag har sedan dess verkligen kommit att uppskatta det. Det första vi gjorde var att vi fyllde i ett papper med vårt namn och skrev ner vår värsta rädsla för att moderera eller facilitera, och vi lämnade in det, och sedan sa han: ”Okej, imorgon ska ni spela upp den här situationen (…) nästa dag kom vi tillbaka och jag lämnade rummet medan resten av gruppen läste, de läste min värsta rädsla, kom på hur de skulle spela upp den, och sedan skulle jag gå in och facilitera i 10 minuter med det. Det hjälpte mig verkligen att inse att det inte finns något att vara rädd för, att våra rädslor för det mesta bara finns i vårt huvud och att möta det fick mig att inse att jag kan hantera dessa situationer.”
Här är möjliga beskrivande och tolkande koder för texten ovan:
Beskrivande kod: hur färdigheter förvärvas
Relaterad motivering till kodbeteckningen:
Tolkningskod: Självreflektion
Relation bakom kodbeteckningen: Deltagarna fick beskriva hur de fick vissa färdigheter:
Steg för att genomföra en tematisk analys
Oavsett vilket verktyg du använder (programvara, journalföring eller affinitetsdiagram) kan genomförandet av en tematisk analys delas in i sex steg.
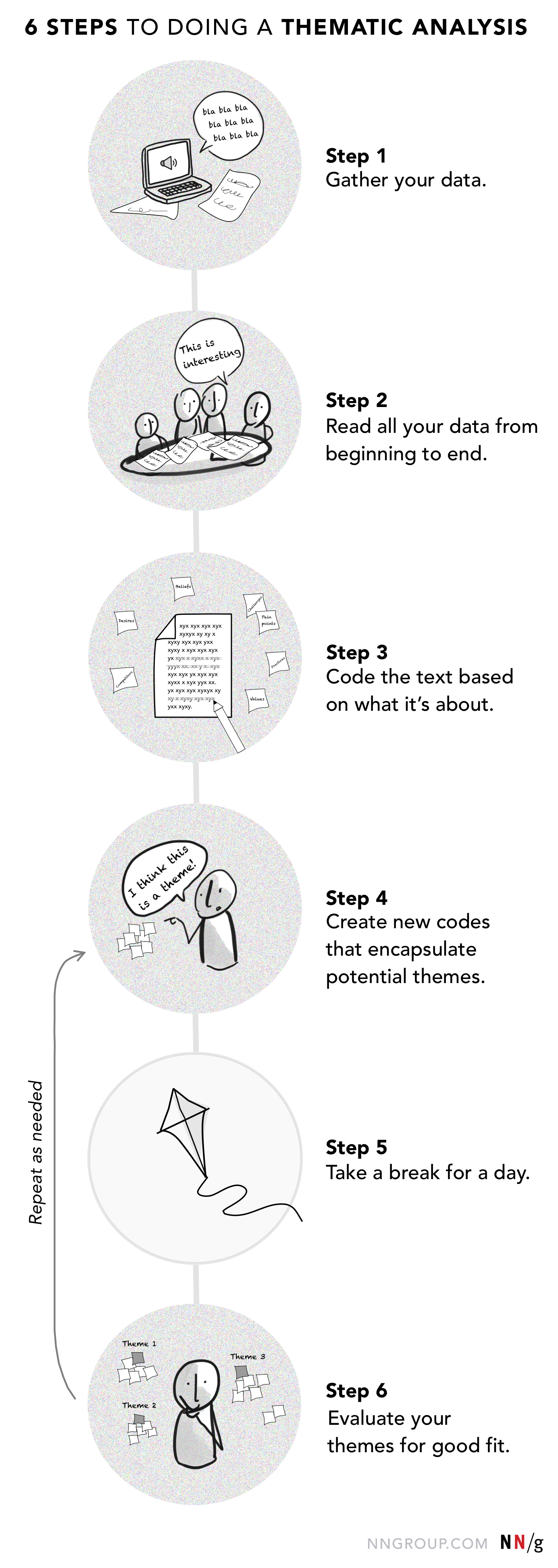
Steg 1: Samla in alla dina data
Start med rådata, till exempel utskrifter av intervjuer eller fokusgrupper, fältanteckningar eller dagboksanteckningar. Jag rekommenderade att du transkriberar ljudinspelningar från intervjuer och använder transkriptionerna för analysen i stället för att förlita dig på ett bristfälligt minne.
Steg 2: Läs alla dina data från början till slut
Färdiggör dig själv med data innan du påbörjar analysen, även om det var du som utförde forskningen. Läs alla dina utskrifter, fältanteckningar och andra datakällor innan du analyserar dem. I det här steget kan du involvera ditt team i projektet. Att involvera ditt team ingjuter kunskap om användarna och empati för dem och deras behov.
Driva en workshop (eller en serie workshops om ditt team är mycket stort eller om du har mycket data). Följ de här stegen:
- För att gruppmedlemmarna ska få ta del av uppgifterna skriver du dina forskningsfrågor på en whiteboard eller ett blädderblock så att det blir lätt att hänvisa till frågorna under arbetet.
- Giv varje medlem en utskrift eller en fält- eller dagboksanteckning. Säg åt folk att markera allt de tycker är viktigt.
- När gruppmedlemmarna har läst färdigt sina inlägg kan de lämna över sin utskrift eller sitt inlägg till någon annan och få ett nytt från en annan gruppmedlem. Detta steg upprepas tills alla gruppmedlemmar har engagerat sig i alla uppgifter.
- Diskutera som grupp vad ni lade märke till eller fann överraskande.

Samtidigt som det är bäst om ditt team observerar alla dina forskningssessioner kanske det inte är möjligt om du har många sessioner eller ett stort team. När enskilda gruppmedlemmar observerar endast en handfull sessioner går de ibland därifrån med en ofullständig förståelse av resultaten. Workshopen kan lösa det problemet, eftersom alla kommer att läsa alla sessionernas utskrifter.
Steg 3: Kodera texten utifrån vad den handlar om
I kodningssteget måste de markerade avsnitten kategoriseras så att de markerade avsnitten lätt kan jämföras.
I det här skedet bör du påminna dig själv om dina forskningsmål. Skriv ut dina forskningsfrågor. Klistra upp dem på en vägg eller på en whiteboard i det rum där du genomför analysen.
Om du har tillräckligt med tid kan du involvera ditt team i detta inledande kodningssteg. Om tiden är begränsad och det finns mycket data att arbeta igenom kan du göra detta steg själv och bjuda in ditt team senare för att granska dina koder och hjälpa till att konkretisera teman.
När du kodar, granska varje textsegment och fråga dig själv ”Vad handlar det här om?”. Ge fragmentet ett namn som beskriver uppgifterna (en beskrivande kod). Du kan också lägga till tolkningskoder till texten i detta skede. Dessa blir dock vanligtvis lättare att tilldela senare.
Koden kan skapas före eller efter att du har grupperat uppgifterna. I de två följande avsnitten i detta steg beskrivs hur och när du kan lägga till koderna.
Traditionell metod: I den traditionella metoden skapar du koder när du markerar segment av data, t.ex. meningar, stycken, fraser, när du markerar dem. Det är bra att föra ett register över alla koder som används och beskriva vad de är, så att du kan hänvisa till denna lista när du kodar ytterligare avsnitt av texten (särskilt om flera personer kodar texten). På detta sätt undviker man att skapa flera koder (som senare måste konsolideras) för samma typ av fråga.
När all text har kodats kan du gruppera alla uppgifter som har samma kod.
Om du använder CAQDAS för denna process loggar programvaran automatiskt de koder som du tilldelar när du kodar, så att du kan använda dem igen. Den tillhandahåller sedan ett sätt för dig att visa all text som kodats med samma kod.
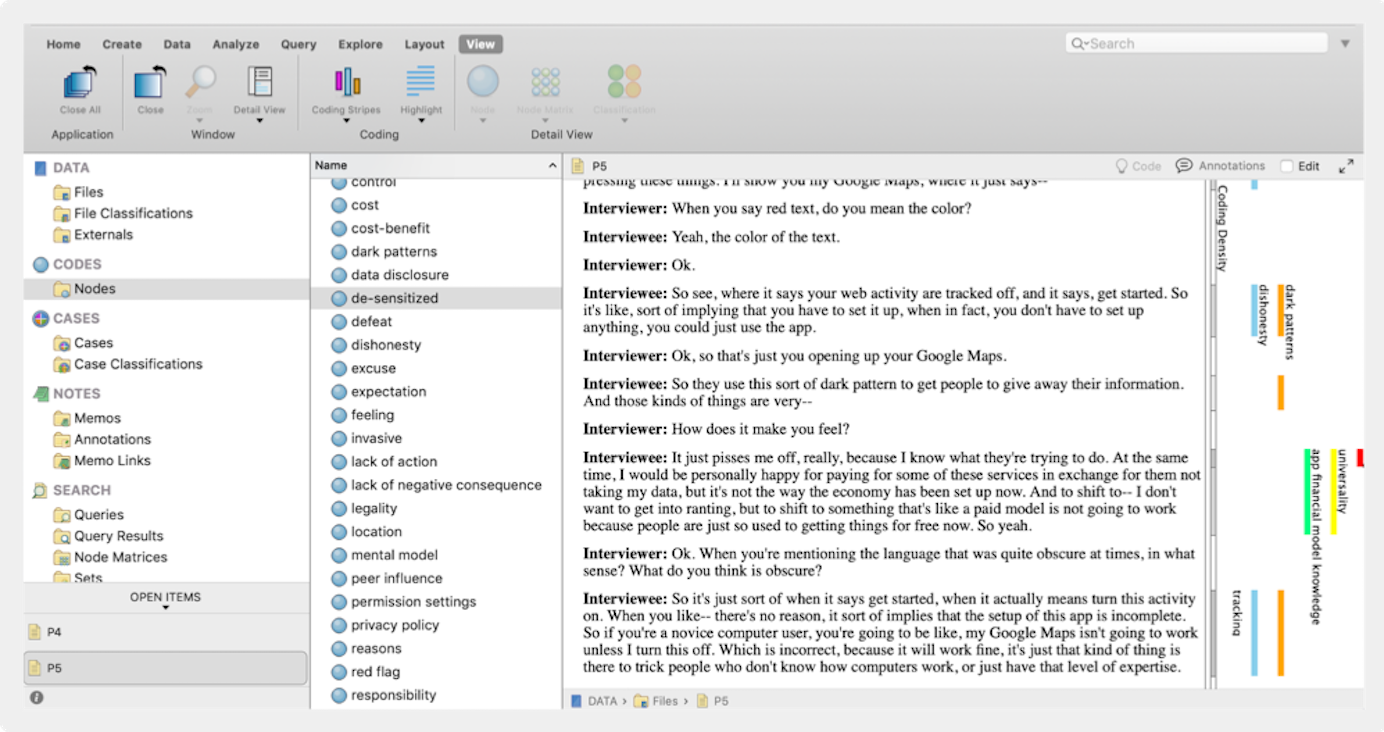
Snabbmetod: Gruppera textavsnitt och tilldela sedan en kod
Istället för att komma på en kod när du markerar text, klipper du upp (fysiskt eller digitalt) och grupperar alla liknande markerade segment (på samma sätt som olika klistermärken kan grupperas i en affinitetskarta). Grupperingarna får sedan en kod. Om du gör grupperingen digitalt kan du kanske dra de kodade avsnitten till ett nytt dokument eller en visuell samarbetsplattform.
I bilderna nedan gjordes grupperingen manuellt. Transkriptioner klipptes upp, fästes på klistermärken och flyttades runt på tavlan tills de föll in i naturliga ämnesgrupper. Forskaren tilldelade sedan ett rosa klistermärke med en beskrivande kod till grupperingen.


I slutet av detta steg bör du ha data grupperade efter ämnen och koder för varje ämne.
Låt oss titta på ett exempel. Jag intervjuade 3 personer om deras erfarenheter av att laga mat hemma. I dessa intervjuer talade deltagarna om hur de valde att laga vissa saker och inte andra. De talade om specifika utmaningar som de ställdes inför när de lagade mat (t.ex, kostkrav, snäva budgetar, brist på tid och fysiskt utrymme) och om lösningar på vissa av dessa utmaningar.
Efter att ha grupperat de markerade urklippen från mina intervjuer efter ämne slutade jag med 3 breda beskrivande koder och motsvarande grupperingar:
- Matlagningsupplevelser: minnesvärda positiva och negativa upplevelser som är relaterade till matlagning
- Smärtepunkter: allt som hindrar någon från att laga mat eller som gör matlagning svår (inklusive att navigera i kostrestriktioner, begränsade budgetar, osv.)
- Saker som hjälper: vad som hjälper (eller tros eventuellt hjälpa) någon att övervinna specifika utmaningar eller smärtpunkter
Steg 4: Skapa nya koder som kapslar in potentiella teman
Se över alla koder och utforska eventuella orsakssamband, likheter, skillnader eller motsägelser för att se om du kan avslöja underliggande teman. Medan du gör detta kommer en del av koderna att läggas åt sidan (antingen arkiveras eller raderas) och nya tolkningskoder kommer att skapas. Om du använder en fysisk kartläggningsmetod som den som diskuterades i steg 3 kan vissa av dessa inledande grupperingar kollapsa eller expandera när du letar efter teman.
Sätt dig själv följande frågor:
- Vad händer i varje grupp?
- Hur hänger dessa koder ihop?
- Hur relaterar dessa till mina forskningsfrågor?
För att återgå till vårt matlagningsämne, när jag analyserade texten inom varje gruppering och letade efter relationer mellan data, märkte jag att två deltagare sa att de gillade ingredienser som kan tillagas på olika sätt och som passar bra ihop med andra olika ingredienser. En tredje deltagare talade om att hon önskade att hon kunde ha en uppsättning ingredienser som kan användas till många olika måltider under veckan, i stället för att behöva köpa separata ingredienser för varje måltidsplan. På så sätt uppstod ett nytt tema om ingrediensernas flexibilitet. För detta tema kom jag fram till koden one ingredient fits all, för vilken jag sedan skrev en detaljerad beskrivning.

Steg 5: Ta en paus en dag och återvänd sedan till uppgifterna
Det är nästan alltid en bra idé att ta en paus och komma tillbaka och titta på uppgifterna med nya ögon. Att göra det hjälper dig ibland att tydligt se viktiga mönster i data och få fram banbrytande insikter.
Steg 6: Utvärdera dina teman för att se om de passar ihop
I det här steget kan det vara användbart att ha andra inblandade som hjälper dig att granska dina koder och framväxande teman. Det är inte bara nya insikter som dras fram, utan dina slutsatser kan utmanas och kritiseras av nya ögon och hjärnor. Denna praxis minskar potentialen för att din tolkning ska färgas av personliga fördomar.
Sätt dina teman under granskning. Ställ dig själv dessa frågor:
- Har temat ett bra stöd av uppgifterna? Eller kan du hitta uppgifter som inte stöder ditt tema?
- Är temat mättat med många exempel?
- Håller andra med om de teman som du har hittat i uppgifterna efter att ha analyserat uppgifterna separat?
Om svaret på dessa frågor är nej kan det betyda att du behöver återvända till analysbordet. Om du antar att du har samlat in bra data finns det nästan alltid något att lära, så det kommer att vara värt att spendera mer tid med ditt team för att upprepa steg 4-6.
Slutsats
Använd tematisk analys som en hjälpsam vägledning för att effektivt vada genom mängder av kvalitativa data. Det finns inte ett enda sätt att göra en tematisk analys. Välj en analysmetod som passar den typ och volym av data som du har samlat in. När det är möjligt, bjud in andra i analysprocessen för att både öka noggrannheten i analysen och teamets kunskap om användarnas beteenden, motivationer och behov. Analysen kan vara en långdragen process, så en bra tumregel är att budgetera lika mycket tid som du hade för datainsamlingen för att slutföra analysen.
Lär dig mer: Användarintervjuer, avancerade tekniker för att avslöja värderingar, motivationer och önskemål, en heldagskurs på UX-konferensen.