- Qu’est-ce qu’un classificateur ?
- Algorithmes de classification
Il était autrefois nécessaire d’avoir une formation en science des données et en ingénierie pour utiliser l’IA et l’apprentissage automatique, mais de nouveaux outils conviviaux et des plateformes SaaS rendent l’apprentissage automatique accessible à tous.
Les classificateurs en apprentissage automatique sont l’une des principales utilisations de la technologie de l’IA – pour analyser automatiquement les données, rationaliser les processus et recueillir des informations précieuses.
- Qu’est-ce qu’un classificateur en apprentissage automatique ?
- Quelle est la différence entre un classificateur et un modèle ?
- Test avec votre propre texte
- Résultats
- 5 types d’algorithmes de classification
- Arbre de décision
- Classificateur Naive Bayes
- K-Voisins les plus proches
- Machines vectorielles de soutien (SVM)
- Les réseaux neuronaux artificiels
- Mettre les classificateurs d’apprentissage automatique à votre service
Qu’est-ce qu’un classificateur en apprentissage automatique ?
Un classificateur en apprentissage automatique est un algorithme qui ordonne ou catégorise automatiquement les données dans une ou plusieurs d’un ensemble de « classes ». L’un des exemples les plus courants est un classificateur d’emails qui analyse les emails pour les filtrer par étiquette de classe : Spam ou Non Spam.
Les algorithmes d’apprentissage automatique sont utiles pour automatiser des tâches qui devaient auparavant être effectuées manuellement. Ils peuvent économiser d’énormes quantités de temps et d’argent et rendre les entreprises plus efficaces.
Quelle est la différence entre un classificateur et un modèle ?
Un classificateur est l’algorithme lui-même – les règles utilisées par les machines pour classer les données. Un modèle de classification, en revanche, est le résultat final de l’apprentissage automatique de votre classificateur. Le modèle est entraîné à l’aide du classificateur, de sorte que le modèle, au final, classe vos données.
Il existe des classificateurs supervisés et non supervisés. Les classificateurs d’apprentissage automatique non supervisés ne reçoivent que des ensembles de données non étiquetés, qu’ils classent en fonction de la reconnaissance des formes ou des structures et anomalies des données. Les classificateurs supervisés et semi-supervisés sont alimentés par des ensembles de données d’entraînement, à partir desquels ils apprennent à classer les données selon des catégories prédéterminées.
L’analyse des sentiments est un exemple d’apprentissage automatique supervisé où les classificateurs sont formés pour analyser le texte pour la polarité de l’opinion et sortir le texte dans la classe : Positive, Neutre, ou Négative. Essayez ce modèle d’analyse de sentiments pré-entraîné pour voir comment il fonctionne.
Test avec votre propre texte
Résultats
Les classificateurs d’apprentissage automatique sont utilisés pour analyser automatiquement les commentaires des clients (comme ceux ci-dessus) provenant des médias sociaux, des courriels, des évaluations en ligne, etc, pour savoir ce que les clients disent de votre marque.
D’autres techniques d’analyse de texte, comme la classification par thème, peuvent trier automatiquement les tickets de service client ou les enquêtes NPS, les classer par thème (prix, fonctionnalités, assistance, etc.) et les acheminer vers le bon service ou employé.
Les plateformes d’analyse de texte en mode SaaS, comme MonkeyLearn, donnent un accès facile à de puissants algorithmes de classification, vous permettant de construire des modèles de classification sur mesure en fonction de vos besoins et de vos critères, généralement en quelques étapes seulement.
Les classificateurs d’apprentissage automatique vont au-delà de la simple cartographie des données, permettant aux utilisateurs de mettre constamment à jour les modèles avec de nouvelles données d’apprentissage et de les adapter à l’évolution des besoins. Les voitures à conduite autonome, par exemple, utilisent des algorithmes de classification pour entrer des données d’image dans une catégorie ; qu’il s’agisse d’un panneau d’arrêt, d’un piéton ou d’une autre voiture, en apprenant et en s’améliorant constamment au fil du temps.
Mais quels sont les principaux algorithmes de classification et comment fonctionnent-ils ?
5 types d’algorithmes de classification
Selon vos besoins et vos données, ces 5 meilleurs algorithmes de classification devraient vous couvrir.
- Arbre de décision
- Classificateur Naive Bayes
- K-Plus proches voisins
- Machines vectorielles de support
- Réseaux neuronaux artificiels
Arbre de décision
Un arbre de décision est un algorithme de classification par apprentissage automatique supervisé utilisé pour construire des modèles comme la structure d’un arbre. Il classe les données en catégories de plus en plus fines : du « tronc de l’arbre », aux « branches », puis aux « feuilles ». Il utilise la règle si-alors des mathématiques pour créer des sous-catégories qui s’insèrent dans des catégories plus larges et permet une catégorisation précise et organique.
Par exemple, voici comment un arbre de décision classerait les sports individuels :
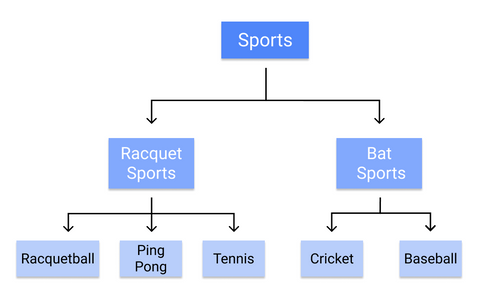
Comme les règles sont apprises de manière séquentielle, du tronc à la feuille, un arbre de décision nécessite des données propres et de haute qualité dès le début de la formation, sinon les branches risquent d’être surajustées ou biaisées.
Classificateur Naive Bayes
Naive Bayes est une famille d’algorithmes probabilistes qui calculent la possibilité qu’un point de données donné puisse entrer dans une ou plusieurs catégories d’un groupe de catégories (ou non). En analyse de texte, Naive Bayes est utilisé pour catégoriser les commentaires des clients, les articles de presse, les courriels, etc, en sujets, thèmes ou » tags » afin de les organiser selon des critères prédéterminés, comme ceci :
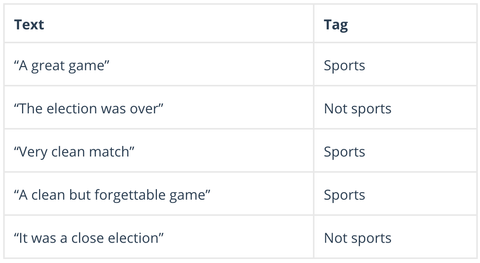
Les algorithmes Naive Bayes calculent la probabilité de chaque tag pour un texte donné, puis sortent pour la probabilité la plus élevée :

Ce qui signifie que la probabilité de A, si B est vrai, est égale à la probabilité de B, si A est vrai, multipliée par la probabilité que A soit vrai, divisée par la probabilité que B soit vrai.
En passant d’une balise à l’autre, on calcule la probabilité qu’un point de données appartienne ou non à une certaine catégorie : Oui/Non.
K-Voisins les plus proches
K-voisins les plus proches (k-NN) est un algorithme de reconnaissance des formes qui stocke et apprend des points de données de formation en calculant comment ils correspondent à d’autres données dans un espace à n dimensions. K-NN vise à trouver les k points de données apparentés les plus proches dans des données futures et non vues.
En analyse de texte, k-NN placerait un mot ou une phrase donnée dans une catégorie prédéterminée en calculant son plus proche voisin : k est décidé par un vote pluriel de ses voisins. Si k = 1, il serait étiqueté dans la classe la plus proche de 1.
Machines vectorielles de soutien (SVM)
Les algorithmes SVM classent les données et forment des modèles dans des degrés super finis de polarité, créant un modèle de classification en 3 dimensions qui va au-delà des simples axes prédictifs X/Y.
Regardez cette représentation visuelle pour comprendre le fonctionnement des algorithmes SVM. Nous avons deux étiquettes : rouge et bleu, avec deux caractéristiques de données : X et Y, et nous entraînons notre classificateur à sortir une coordonnée X/Y comme étant soit rouge, soit bleue.
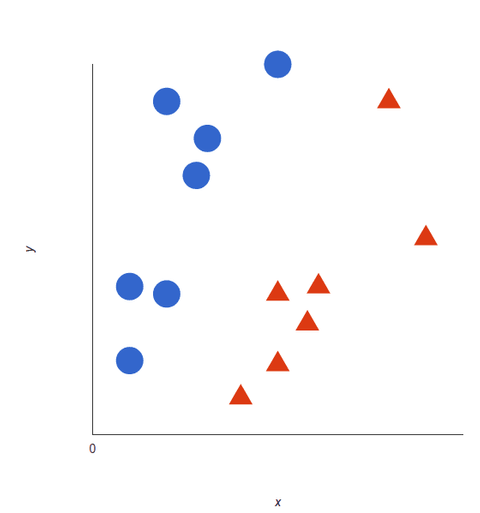
Le SVM attribue un hyperplan qui sépare (distingue) au mieux les balises. En deux dimensions, il s’agit simplement d’une ligne droite. Les tags bleus tombent d’un côté de l’hyperplan et les rouges de l’autre. Dans l’analyse des sentiments, ces balises seraient Positives et Négatives.
Pour maximiser l’apprentissage du modèle d’apprentissage automatique, le meilleur hyperplan est celui qui présente la plus grande distance entre chaque balise :
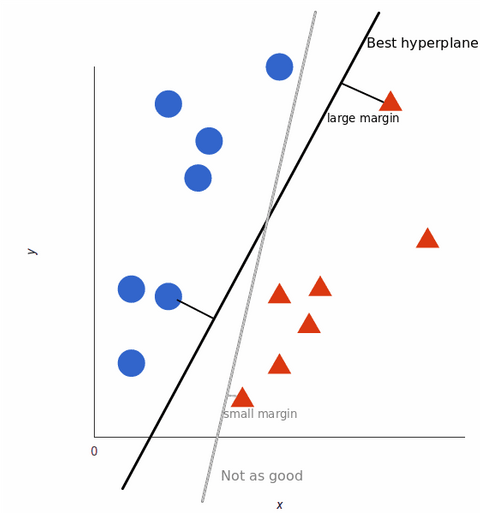
A mesure que nos ensembles de données deviennent plus complexes, il peut être impossible de tracer une ligne unique pour distinguer les deux classes :
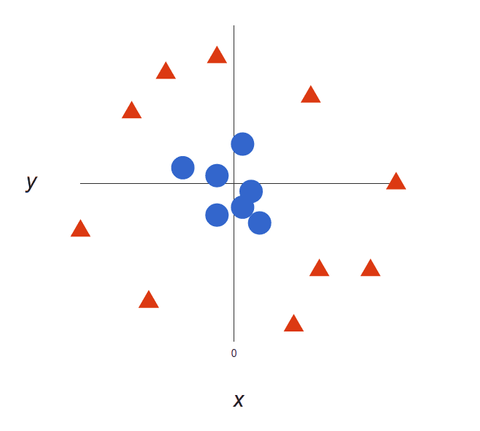
Les algorithmes SVM font d’excellents classificateurs car, plus les données sont complexes, plus la prédiction sera précise. Imaginez ce qui précède comme une sortie tridimensionnelle, avec un axe Z ajouté, de sorte qu’elle devient un cercle.
Remis en 2D, avec le meilleur hyperplan, cela ressemble à ceci :
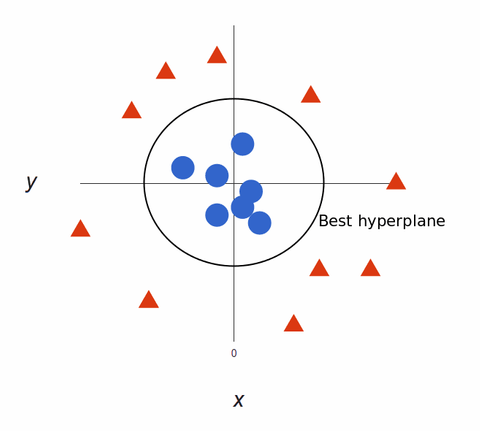
Les algorithmes SVM créent des modèles d’apprentissage automatique super précis parce qu’ils sont multidimensionnels.
Les réseaux neuronaux artificiels
Les réseaux neuronaux artificiels ne sont pas un « type » d’algorithme, autant qu’ils sont une collection d’algorithmes qui travaillent ensemble pour résoudre des problèmes.
Les réseaux neuronaux artificiels sont conçus pour fonctionner un peu comme le cerveau humain. Ils relient les processus de résolution de problèmes dans une chaîne d’événements, de sorte qu’une fois qu’un algorithme ou un processus a résolu un problème, l’algorithme suivant (ou le maillon de la chaîne) est activé.
Les réseaux neuronaux artificiels ou les modèles d' »apprentissage profond » nécessitent de grandes quantités de données d’entraînement parce que leurs processus sont très avancés, mais une fois qu’ils ont été correctement formés, ils peuvent avoir des performances supérieures à celles d’autres algorithmes, individuels.
Il existe une variété de réseaux neuronaux artificiels, notamment les réseaux convolutifs, récurrents, à action directe, etc, et l’architecture d’apprentissage automatique la mieux adaptée à vos besoins dépend du problème que vous cherchez à résoudre.
Mettre les classificateurs d’apprentissage automatique à votre service
Les algorithmes de classification permettent l’automatisation de tâches d’apprentissage automatique qui étaient impensables il y a seulement quelques années. Et, mieux encore, ils vous permettent de former des modèles d’IA aux besoins, à la langue et aux critères de votre entreprise, en réalisant des performances beaucoup plus rapides et avec un plus grand niveau de précision que les humains ne pourraient jamais le faire.
MonkeyLearn est une plateforme d’analyse de texte par apprentissage automatique qui exploite la puissance des classificateurs d’apprentissage automatique avec une interface excessivement conviviale, afin que vous puissiez rationaliser les processus et tirer le meilleur parti de vos données textuelles pour obtenir des informations précieuses.
Essayez ces modèles de classification pré-entraînés pour voir comment cela fonctionne :
- Classificateur de commentaires d’enquête NPS : classez automatiquement les réponses aux enquêtes ouvertes dans les catégories Support client, Facilité d’utilisation, Fonctionnalités et Prix
- Analyseur de sentiments : analysez n’importe quel texte pour la polarité des opinions : Positif, Négatif, Neutre
- Classificateur d’intention d’email : classez automatiquement les réponses d’email comme Intéressé, Pas intéressé, Autorespondeur, Rebond d’email, Désabonnement ou Mauvaise personne
Or planifiez une démo gratuite pour voir tout ce que MonkeyLearn a à offrir.