- O que é um Classificador?
- Algoritmos de Classificação
Era necessário ter uma formação em ciências de dados e engenharia para usar a IA e a aprendizagem de máquinas, mas novas ferramentas de fácil utilização e plataformas SaaS tornam a aprendizagem de máquinas acessível a todos.
Os classificadores de aprendizagem de máquinas são um dos principais usos da tecnologia de IA – para analisar dados automaticamente, agilizar processos e reunir insights valiosos.
- O que é um classificador na aprendizagem de máquinas?
- Qual é a diferença entre um Classificador e um Modelo?
- Teste com seu próprio texto
- Resultados
- 5 Tipos de Algoritmos de Classificação
- Árvore de Decisões
- Naive Bayes Classifier
- K-Nearest Neighbors
- Support Vector Machines (SVM)
- Artificial Neural Networks
- Put Machine Learning Classifiers to Work for You
O que é um classificador na aprendizagem de máquinas?
Um classificador na aprendizagem de máquinas é um algoritmo que automaticamente ordena ou categoriza dados em um ou mais de um conjunto de “classes”. Um dos exemplos mais comuns é um classificador de e-mail que escaneia e-mails para filtrá-los por etiqueta de classe: Spam or Not Spam.
Os algoritmos de aprendizagem de máquinas são úteis para automatizar tarefas que anteriormente tinham de ser feitas manualmente. Eles podem poupar muito tempo e dinheiro e tornar os negócios mais eficientes.
Qual é a diferença entre um Classificador e um Modelo?
Um classificador é o próprio algoritmo – as regras usadas pelas máquinas para classificar os dados. Um modelo de classificação, por outro lado, é o resultado final da aprendizagem da sua máquina classificadora. O modelo é treinado usando o classificador, para que o modelo, em última instância, classifique seus dados.
Existem classificadores supervisionados e não supervisionados. Os classificadores de aprendizagem de máquina não supervisionados são alimentados apenas com conjuntos de dados não etiquetados, que eles classificam de acordo com o reconhecimento de padrões ou estruturas e anomalias nos dados. Classificadores supervisionados e semi-supervisionados são alimentados com conjuntos de dados de treinamento, a partir dos quais eles aprendem a classificar os dados de acordo com categorias pré-determinadas.
Análise de sentimento é um exemplo de aprendizagem de máquina supervisionada onde classificadores são treinados para analisar textos para a polaridade de opinião e emitir o texto para a classe: Positivo, Neutro, ou Negativo. Experimente este modelo de análise de sentimentos pré-treinado para ver como ele funciona.
Teste com seu próprio texto
Resultados
Os classificadores de aprendizagem da máquina são usados para analisar automaticamente os comentários dos clientes (como os acima mencionados) das redes sociais, e-mails, revisões online, etc, para descobrir o que os clientes estão dizendo sobre sua marca.
Outras técnicas de análise de texto, como classificação de tópicos, podem classificar automaticamente através de tickets de atendimento ao cliente ou pesquisas NPS, categorizá-los por tópico (Preços, Recursos, Suporte, etc.), e encaminhá-los para o departamento ou funcionário correto.
Plataformas de análise de texto de SaaS, como o MonkeyLearn, dão fácil acesso a poderosos algoritmos de classificação, permitindo que você personalize modelos de classificação de acordo com suas necessidades e critérios, geralmente em apenas alguns passos.
Os classificadores de aprendizagem de máquinas vão além do simples mapeamento de dados, permitindo que os usuários atualizem constantemente os modelos com novos dados de aprendizagem e os adaptem às necessidades em mudança. Automobilistas, por exemplo, utilizam algoritmos de classificação para introduzir dados de imagem numa categoria; quer seja um sinal de paragem, um peão ou outro carro, aprendendo e melhorando constantemente ao longo do tempo.
Mas quais são os principais algoritmos de classificação e como funcionam?
5 Tipos de Algoritmos de Classificação
Dependente das suas necessidades e dos seus dados, estes 5 principais algoritmos de classificação devem tê-lo coberto.
- Árvore de Decisões
- Classificador Bayes ingênuo
- K-Nearest Neighbors
- Máquinas Vetoriais de Apoio
- Redes Neurais Artificiais
Árvore de Decisões
Uma árvore de decisão é um algoritmo de classificação de aprendizagem supervisionada de máquinas utilizado para construir modelos como a estrutura de uma árvore. Ele classifica os dados em categorias mais finas e mais finas: de “tronco de árvore”, para “ramos”, para “folhas”. Ele usa a regra if-then da matemática para criar sub-categorias que se encaixam em categorias mais amplas e permite uma categorização precisa e orgânica.
Por exemplo, é assim que uma árvore de decisão categorizaria esportes individuais:
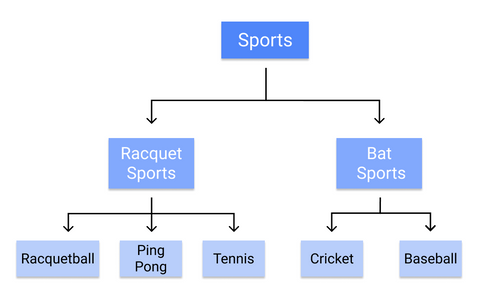
Como as regras são aprendidas sequencialmente, do tronco à folha, uma árvore de decisão requer dados limpos e de alta qualidade desde o início do treinamento, ou os ramos podem se tornar excessivamente ajustados ou inclinados.
Naive Bayes Classifier
Naive Bayes é uma família de algoritmos probabilísticos que calcula a possibilidade de que qualquer dado ponto de dados possa cair em um ou mais de um grupo de categorias (ou não). Na análise de texto, Naive Bayes é utilizado para categorizar comentários de clientes, artigos de notícias, e-mails, etc, em assuntos, tópicos ou “tags” para organizá-los de acordo com critérios pré-determinados, como este:
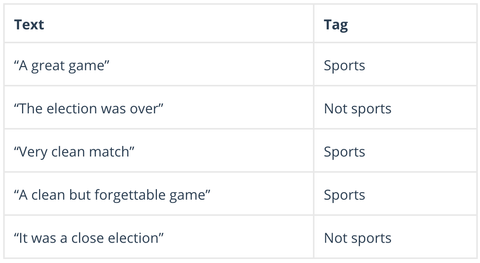
Algoritmos Bayes ingênuos calculam a probabilidade de cada tag para um determinado texto, e depois emitem para a maior probabilidade:

Meaning, a probabilidade de A, se B for verdadeiro, é igual à probabilidade de B, se A for verdadeiro, vezes a probabilidade de A ser verdadeiro, dividida pela probabilidade de B ser verdadeiro.
Movendo de tag para tag, isto calcula a probabilidade de que um ponto de dados pertença ou não a uma determinada categoria: Sim/Não.
K-Nearest Neighbors
K-nearest Neighbors (k-NN) é um algoritmo de reconhecimento de padrões que armazena e aprende com os pontos de dados de treinamento, calculando como eles correspondem a outros dados no espaço n-dimensional. K-NN visa encontrar os k pontos de dados relacionados mais próximos no futuro, dados não vistos.
Na análise de texto, k-NN colocaria uma determinada palavra ou frase dentro de uma categoria pré-determinada calculando o seu vizinho mais próximo: k é decidido por um voto de pluralidade dos seus vizinhos. Se k = 1, ele seria marcado na classe mais próxima 1.
Support Vector Machines (SVM)
Algoritmos SVM classificam dados e treinam modelos dentro de graus super finitos de polaridade, criando um modelo de classificação tridimensional que vai além de apenas eixos preditivos X/Y.
Dê uma olhada nessa representação visual para entender como os algoritmos SVM funcionam. Temos duas tags: vermelho e azul, com duas características de dados: X e Y, e treinamos o nosso classificador para emitir uma coordenada X/Y como vermelho ou azul.
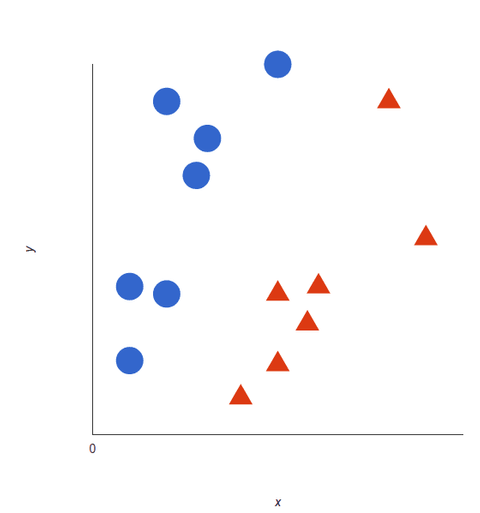
O SVM atribui um hiperplano que melhor separa (distingue entre) as tags. Em duas dimensões isto é simplesmente uma linha reta. As etiquetas azuis caem de um lado do hiperplano e vermelhas do outro. Na análise dos sentimentos estas tags seriam Positivas e Negativas.
Para maximizar o treinamento do modelo de aprendizagem da máquina, o melhor hiperplano é aquele com a maior distância entre cada tag:
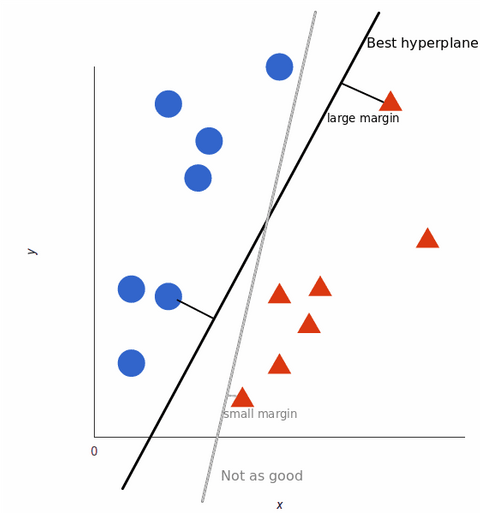
Como nossos conjuntos de dados se tornam mais complexos, pode não ser possível traçar uma única linha para distinguir entre as duas classes:
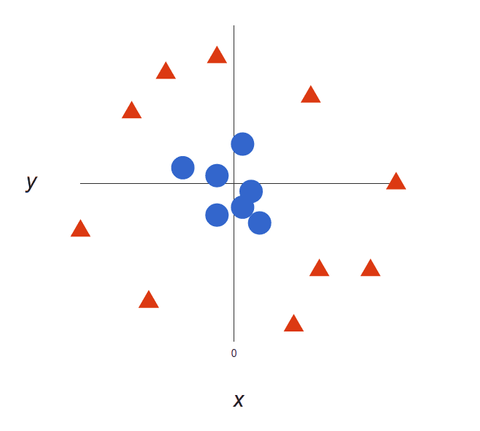
Algoritmos SVM fazem excelentes classificadores porque, quanto mais complexos os dados, mais precisa será a previsão. Imagine o acima como uma saída tridimensional, com um eixo Z adicionado, de modo que se torne um círculo.
Mapa de volta a 2D, com o melhor hiperplano, parece assim:
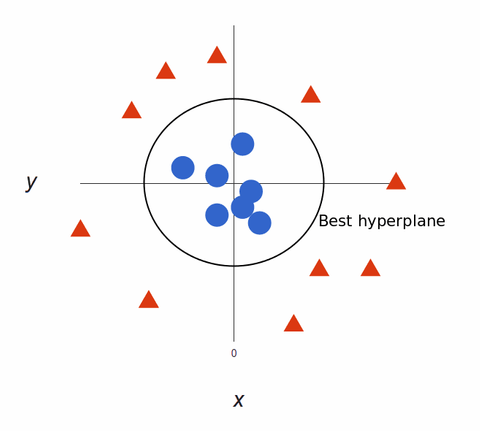
algoritmos SVM criam modelos de aprendizagem de máquina super precisos porque são multidimensionais.
Artificial Neural Networks
As redes neurais artificiais não são um “tipo” de algoritmo, tanto quanto são uma coleção de algoritmos que trabalham em conjunto para resolver problemas.
As redes neurais artificiais são projetadas para funcionar muito como o cérebro humano faz. Elas conectam processos de solução de problemas em uma cadeia de eventos, de modo que uma vez que um algoritmo ou processo tenha resolvido um problema, o próximo algoritmo (ou elo na cadeia) é ativado.
Redes neurais artificiais ou modelos de “aprendizagem profunda” requerem grandes quantidades de dados de treinamento, pois seus processos são altamente avançados, mas uma vez que tenham sido adequadamente treinados, eles podem executar além de outros algoritmos individuais.
Existem uma variedade de redes neurais artificiais, incluindo redes convolucionais, recorrentes, feed-forward, etc, e a arquitectura de aprendizagem da máquina mais adequada às suas necessidades depende do problema que pretende resolver.
Put Machine Learning Classifiers to Work for You
Os algoritmos de classificação permitem a automatização de tarefas de aprendizagem da máquina que eram impensáveis há poucos anos. E, melhor ainda, eles permitem que você treine modelos de IA para as necessidades, linguagem e critérios do seu negócio, executando muito mais rápido e com um nível de precisão maior do que os humanos jamais poderiam.
MonkeyLearn é uma plataforma de análise de texto de aprendizagem de máquina que aproveita o poder dos classificadores de aprendizagem de máquina com uma interface extremamente amigável, para que você possa agilizar processos e obter o máximo dos seus dados de texto para valiosos insights.
Execute esses modelos de classificação pré-treinados para ver como funciona:
- NPS Survey Feedback Classifier: classifique automaticamente as respostas de questionários abertos em categorias Suporte ao cliente, Facilidade de uso, Recursos e Preço
- Sentiment Analyzer: analise qualquer texto para polaridade de opinião: Positivo, Negativo, Neutro
- Classificador de intenção de email: classifique automaticamente as respostas de email como Interessado, Não Interessado, Respostas automáticas, Respostas por email, Cancelamento de assinatura ou Pessoa errada
Arrume uma demonstração grátis para ver tudo o que o MonkeyLearn tem para oferecer.