- Vad är en klassificerare?
- Klassificeringsalgoritmer
Det brukade vara så att man behövde en bakgrund inom datavetenskap och teknik för att använda AI och maskininlärning, men nya användarvänliga verktyg och SaaS-plattformar gör maskininlärning tillgänglig för alla.
Klassificerare för maskininlärning är en av de främsta användningsområdena för AI-teknik – för att automatiskt analysera data, effektivisera processer och samla in värdefulla insikter.
- Vad är en klassificerare inom maskininlärning?
- Vad är skillnaden mellan en klassificerare och en modell?
- Testa med din egen text
- Resultat
- 5 typer av klassificeringsalgoritmer
- Debiteringsträd
- Naive Bayes-klassificerare
- K-nästa grannar
- Support Vector Machines (SVM)
- Konstnärliga neurala nätverk
- Sätt klassificerare för maskininlärning i arbete för dig
Vad är en klassificerare inom maskininlärning?
En klassificerare inom maskininlärning är en algoritm som automatiskt ordnar eller kategoriserar data i en eller flera av en uppsättning ”klasser”. Ett av de vanligaste exemplen är en e-postklassificerare som skannar e-postmeddelanden för att filtrera dem efter klassbeteckning:
Algoritmer för maskininlärning hjälper till att automatisera uppgifter som tidigare var tvungna att göras manuellt. De kan spara enorma mängder tid och pengar och göra företag mer effektiva.
Vad är skillnaden mellan en klassificerare och en modell?
En klassificerare är själva algoritmen – de regler som används av maskiner för att klassificera data. En klassificeringsmodell, å andra sidan, är slutresultatet av din klassificerares maskininlärning. Modellen tränas med hjälp av klassificeraren, så att modellen i slutändan klassificerar dina data.
Det finns både övervakade och oövervakade klassificerare. Oövervakade klassificerare för maskininlärning matas endast med icke-märkta dataset, som de klassificerar enligt mönsterigenkänning eller strukturer och anomalier i data. Övervakade och halvövervakade klassificerare får träningsdatamängder från vilka de lär sig att klassificera data enligt förutbestämda kategorier.
Sentimentanalys är ett exempel på övervakad maskininlärning där klassificerare tränas för att analysera text med avseende på åsiktspolarisering och överföra texten till en klass: Positiv, neutral eller negativ. Prova den här förtränade modellen för sentimentanalys för att se hur den fungerar.
Testa med din egen text
Resultat
Maskininlärningsklassificatorer används för att automatiskt analysera kundkommentarer (som ovan) från sociala medier, e-post, recensioner på nätet osv, för att ta reda på vad kunderna säger om ditt varumärke.
Andra textanalystekniker, som t.ex. ämnesklassificering, kan automatiskt sortera kundtjänstärenden eller NPS-enkäter, kategorisera dem efter ämne (pris, funktioner, support osv.) och dirigera dem till rätt avdelning eller anställd.
SaaS textanalysplattformar, som MonkeyLearn, ger enkel tillgång till kraftfulla klassificeringsalgoritmer, vilket gör att du kan skräddarsy klassificeringsmodeller efter dina behov och kriterier, vanligtvis i bara några få steg.
Maskininlärningsklassificerare går längre än enkel datamappning, vilket gör det möjligt för användarna att ständigt uppdatera modellerna med nya inlärningsdata och skräddarsy dem efter förändrade behov. Självkörande bilar använder till exempel klassificeringsalgoritmer för att mata in bilddata till en kategori, oavsett om det är en stoppskylt, en fotgängare eller en annan bil, och lär sig hela tiden och förbättras med tiden.
Men vilka är de viktigaste klassificeringsalgoritmerna och hur fungerar de?
5 typer av klassificeringsalgoritmer
Avhängigt av dina behov och dina data bör de här fem bästa klassificeringsalgoritmerna täcka dig.
- Debiteringsträd
- Naive Bayes Classifier
- K-Nearest Neighbors
- Support Vector Machines
- Konstnärliga neurala nätverk
Debiteringsträd
Ett beslutsträd är en övervakad klassificeringsalgoritm för maskininlärning som används för att bygga upp modeller som liknar strukturen på ett träd. Den klassificerar data i allt finare kategorier: från ”trädstam” till ”grenar” och ”blad”. Den använder matematikens om-då-regel för att skapa underkategorier som passar in i bredare kategorier och möjliggör en exakt, organisk kategorisering.
Till exempel är hur ett beslutsträd skulle kategorisera enskilda sporter:
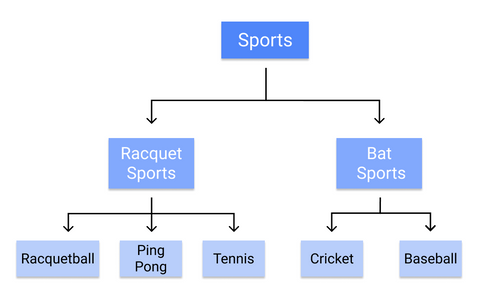
Då reglerna lärs in sekventiellt, från stam till blad, kräver ett beslutsträd rena data av hög kvalitet från början av träningen, annars kan grenarna bli överanpassade eller skeva.
Naive Bayes-klassificerare
Naive Bayes är en familj av sannolikhetsalgoritmer som beräknar möjligheten att en given datapunkt kan falla in i en eller flera av en grupp av kategorier (eller inte). I textanalys används Naive Bayes för att kategorisera kundkommentarer, nyhetsartiklar, e-post osv, i ämnen, ämnen eller ”taggar” för att organisera dem enligt förutbestämda kriterier, som här:
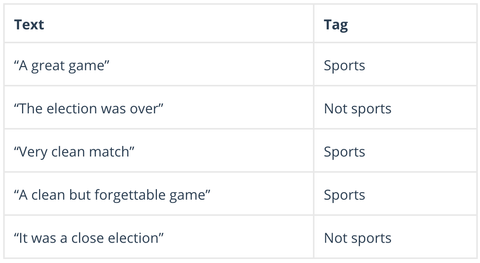
Naive Bayes-algoritmer beräknar sannolikheten för varje tagg för en given text och ger sedan ut för den högsta sannolikheten:

Med detta menas att sannolikheten för att A, om B är sant, är lika med sannolikheten för att B, om A är sant, multiplicerat med sannolikheten för att A är sant, dividerat med sannolikheten för att B är sant.
Om man går från tagg till tagg beräknas sannolikheten för att en datapunkt hör till en viss kategori eller inte: Ja/Nej.
K-nästa grannar
K-nästa grannar (k-NN) är en algoritm för mönsterigenkänning som lagrar och lär sig av träningsdatapunkter genom att beräkna hur de motsvarar andra data i ett n-dimensionellt utrymme. K-NN syftar till att hitta de k närmast besläktade datapunkterna i framtida, ovisade data.
I textanalys skulle k-NN placera ett givet ord eller en fras inom en förutbestämd kategori genom att beräkna dess närmaste granne: k avgörs genom en flerfaldsröstning av dess grannar. Om k = 1, skulle det taggas in i klassen närmast 1.
Support Vector Machines (SVM)
SVM-algoritmer klassificerar data och tränar modeller inom superfinita grader av polaritet, vilket skapar en tredimensionell klassificeringsmodell som går längre än bara X/Y-prediktiva axlar.
Ta en titt på den här visuella representationen för att förstå hur SVM-algoritmer fungerar. Vi har två taggar: röd och blå, med två datafunktioner: X och Y, och vi tränar vår klassificerare att ge ut en X/Y-koordinat som antingen röd eller blå.
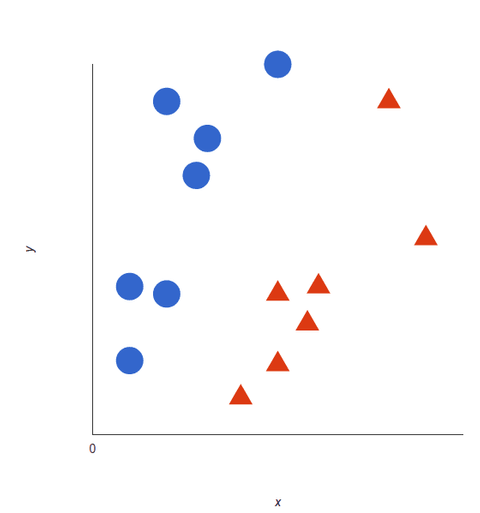
SvM:en tilldelar ett hyperplan som bäst skiljer taggarna åt (skiljer dem åt). I två dimensioner är detta helt enkelt en rak linje. Blå taggar faller på ena sidan av hyperplanet och röda på den andra. I sentimentanalys skulle dessa taggar vara Positiv och Negativ.
För att maximera utbildningen av maskininlärningsmodellen är den bästa hyperplanen den med det största avståndet mellan varje tagg:
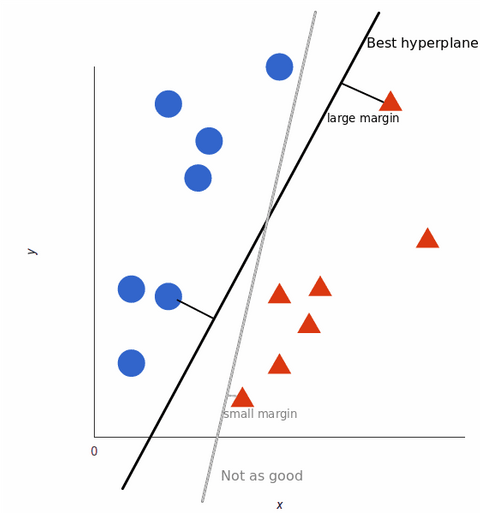
När våra datamängder blir mer komplexa är det kanske inte möjligt att dra en enda linje för att skilja mellan de två klasserna:
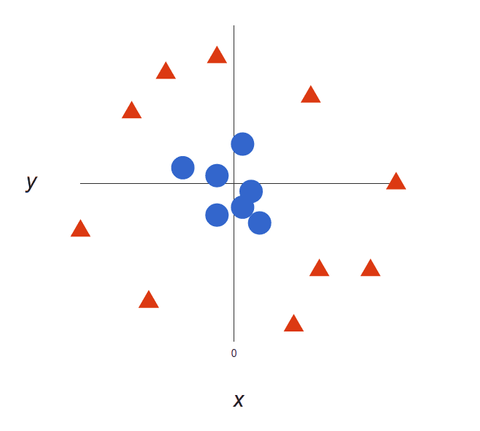
SVM-algoritmer är utmärkta klassificerare, eftersom ju mer komplexa data, desto mer exakt blir förutsägelsen. Föreställ dig ovanstående som ett 3-dimensionellt utdata, med en Z-axel tillagd, så att det blir en cirkel.
Mappad tillbaka till 2D, med det bästa hyperplanet, ser det ut så här:
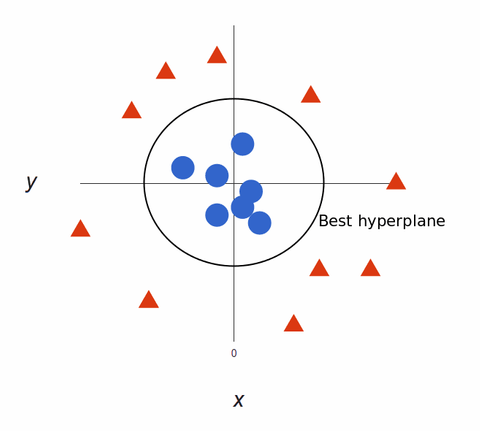
SVM-algoritmer skapar superprecisa modeller för maskininlärning eftersom de är multidimensionella.
Konstnärliga neurala nätverk
Konstnärliga neurala nätverk är inte en ”typ” av algoritm, lika mycket som de är en samling algoritmer som arbetar tillsammans för att lösa problem.
Konstnärliga neurala nätverk är utformade för att fungera ungefär som den mänskliga hjärnan gör. De kopplar samman problemlösningsprocesser i en kedja av händelser, så att när en algoritm eller process har löst ett problem aktiveras nästa algoritm (eller länk i kedjan).
Konstnärliga neurala nätverk eller modeller för ”djupinlärning” kräver stora mängder träningsdata eftersom deras processer är mycket avancerade, men när de väl har tränats på rätt sätt kan de prestera mer än andra, enskilda algoritmer.
Det finns en mängd olika typer av konstgjorda neurala nätverk, bland annat konvolutionella, recurrenta, feed-forward, osv, och vilken arkitektur för maskininlärning som är bäst lämpad för dina behov beror på vilket problem du vill lösa.
Sätt klassificerare för maskininlärning i arbete för dig
Klassificeringsalgoritmer gör det möjligt att automatisera uppgifter för maskininlärning som var otänkbara för bara några år sedan. Och ännu bättre, de gör det möjligt för dig att träna AI-modeller till behoven, språket och kriterierna i din verksamhet, och de presterar mycket snabbare och med större noggrannhet än vad människor någonsin skulle kunna göra.
MonkeyLearn är en plattform för maskininlärning av textanalyser som utnyttjar kraften i maskininlärning av klassificerare med ett ytterst användarvänligt gränssnitt, så att du kan effektivisera processerna och få ut mesta möjliga av dina textdata för att få värdefulla insikter.
Testa dessa förtränade klassificeringsmodeller för att se hur det fungerar:
- NPS Survey Feedback Classifier: klassificera automatiskt öppna enkätsvar i kategorierna Kundsupport, Användarvänlighet, Funktioner och Prissättning
- Sentiment Analyzer: analysera vilken text som helst för åsiktspolaritet: Positiv, negativ, neutral
- Email Intent Classifier: klassificera automatiskt e-postsvar som intresserade, ointresserade, autoresponder, e-postavvisning, avregistrering eller fel person
Och boka in en kostnadsfri demo för att se allt som MonkeyLearn har att erbjuda.