- 分類器とは何か?
- 分類アルゴリズム
以前は、AI や機械学習を使用するにはデータ サイエンスやエンジニアリングの知識が必要でしたが、新しいユーザーフレンドリーなツールや SaaS プラットフォームにより、機械学習は誰でも利用できるようになりました。
機械学習の分類器は、データを自動的に分析し、プロセスを合理化し、貴重な洞察を収集する、AI テクノロジーの最も重要な用途の 1 つです。
機械学習における分類器とは
機械学習における分類器は、データを一連の「クラス」のうちの 1 つ以上に自動的に注文または分類するアルゴリズムです。 最も一般的な例の 1 つは、電子メールをスキャンしてクラス ラベルでフィルタリングする電子メール分類器です。
機械学習アルゴリズムは、以前は手動で行わなければならなかった作業を自動化するのに便利です。
分類器とモデルの違いは何ですか
分類器はアルゴリズムそのものであり、データを分類するために機械が使用する規則です。 一方、分類モデルは、分類器の機械学習の最終結果です。
教師あり分類器と教師なし分類器の両方があります。 教師なし機械学習分類器は、ラベルの付いていないデータセットのみを与えられ、パターン認識またはデータの構造や異常に従って分類します。
感情分析は、教師あり機械学習の一例で、意見の極性についてテキストを分析し、テキストをクラスに分類して出力するよう分類器を訓練するものです。 肯定的、中立的、または否定的なクラスにテキストを出力します。
Test with your own text
Results
機械学習分類器は、ソーシャルメディア、電子メール、オンライン レビューなどからの顧客のコメント (上記のようなもの) を自動的に分析するために使用されます。
トピック分類などの他のテキスト分析技術は、カスタマー サービス チケットまたは NPS 調査を自動的に分類し、トピック (価格、機能、サポートなど) によって分類し、正しい部署または従業員に転送することが可能です。
MonkeyLearnのようなSaaSテキスト分析プラットフォームでは、強力な分類アルゴリズムに簡単にアクセスでき、通常は数ステップで、ニーズと基準に合わせて分類モデルをカスタム構築できます。
機械学習分類器は、単純なデータマッピングを超えて、ユーザーが常に新しい学習データでモデルを更新して、ニーズの変化に合わせて調整できるようにします。
しかし、主要な分類アルゴリズムにはどのようなものがあり、どのように機能するのでしょうか。
5種類の分類アルゴリズム
ニーズとデータに応じて、これらのトップ5の分類アルゴリズムでカバーすることができます。
- 決定木
- ナイーブ ベイズ分類器
- 最近傍探索
- サポート ベクトル マシン
- Artificial Neural Networks
決定木
決定木は教師あり機械学習分類アルゴリズムで、木の構造のようにモデルを築くために使用されます。 データを「木の幹」から「枝」、そして「葉」へと、より細かいカテゴリに分類します。
たとえば、これは決定木が個々のスポーツを分類する方法です。
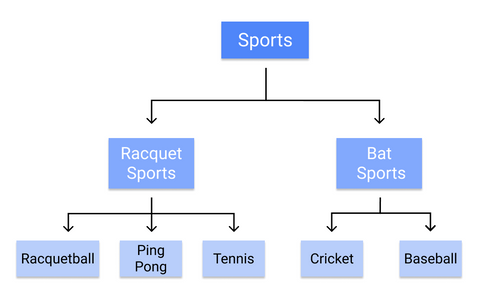
ルールは幹から葉へと順次学習されるので、決定木はトレーニングの最初から高品質でクリーンなデータを必要とし、さもなければ枝は過剰適合したり歪んだりします。
Naive Bayes 分類器
Naive Bayes は、任意のデータ ポイントがカテゴリ グループの 1 つ以上に該当するかしないかを計算する確率的アルゴリズム ファミリーです。 テキスト分析では、顧客のコメント、ニュース記事、電子メールなどを分類するために使用されます。
ナイーブ ベイズ アルゴリズムは、与えられたテキストに対する各タグの確率を計算し、最も高い確率のものを出力します。

意味は、B が真の場合、Aの確率は、Aが真の場合、B の確率の倍、Aが真の確率を B が真の確率で割ったものと等しいということです。
タグからタグに移動して、これは、データ ポイントが特定のカテゴリ内に属するかどうかの確率を計算します。
K-nearest neighbors
K-nearest neighbors (k-NN) はパターン認識アルゴリズムで、学習データ ポイントが n 次元空間内の他のデータにどう対応するかを計算して保存し、学習するものです。
テキスト分析では、k-NN は、与えられた単語または語句を、その最近傍を計算することにより、所定のカテゴリ内に配置します: k は、その近隣住民の複数投票により決定されます。 k = 1 の場合、最も近い 1 のクラスにタグ付けされます。
Support Vector Machines (SVM)
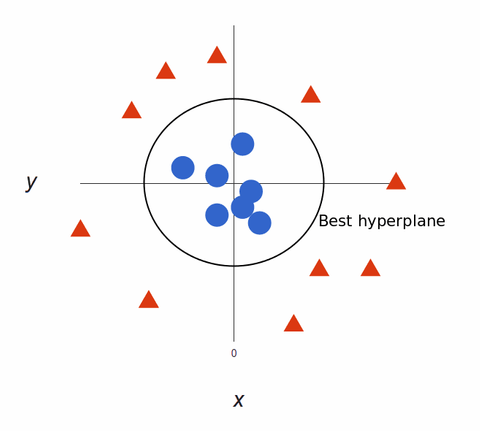
SVMアルゴリズムはデータを分類し、極性の超限度内でモデルを訓練し、単なる X/Y 予測軸を超えた 3 次元の分類モデルを作成します。 赤と青という2つのタグがあり、2つのデータ特徴があります。
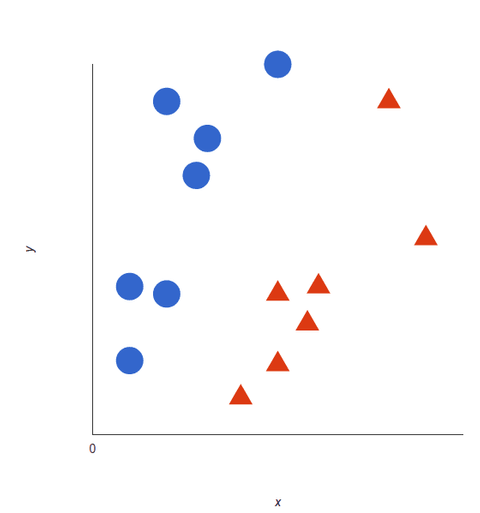
SVM は、タグを最もよく分離する (区別する) 超平面を割り当てます。 2次元では、これは単に直線です。 青いタグは超平面の片側に、赤いタグはもう片側に落ちます。
機械学習モデルのトレーニングを最大化するために、最適な超平面は、各タグ間の距離が最も大きいものです。
データセットがより複雑になると、2 つのクラスを区別するために 1 本の線を引くことができない場合があります。
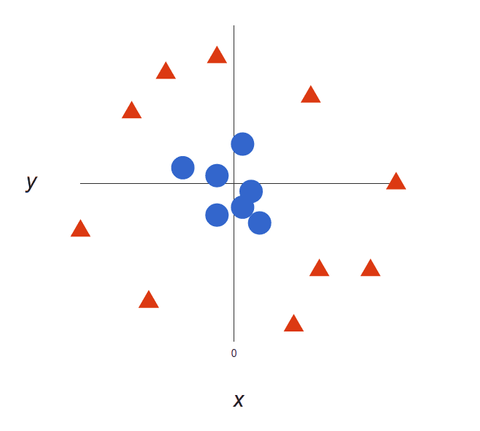
データが複雑になればなるほど、予測の正確さが増すので、SVM アルゴリズムは優れた分類器です。
最適な超平面を使用して 2 次元にマッピングすると、次のようになります:
多次元であるため、SVMアルゴリズムは非常に正確な機械学習モデルを作成できます。
人工ニューラルネットワーク
人工ニューラルネットワークは、アルゴリズムの「種類」ではなく、問題を解決するために一緒に働くアルゴリズムの集合体です。
人工ニューラルネットワークまたは「深層学習」モデルは、そのプロセスが高度であるため、膨大な量のトレーニングデータを必要としますが、いったん適切にトレーニングされると、他の個別のアルゴリズム以上のパフォーマンスを発揮することができます。
機械学習の分類器を活用する
分類アルゴリズムにより、ほんの数年前までは考えられなかったような機械学習タスクの自動化が可能になりました。
MonkeyLearnは、機械学習のテキスト分析プラットフォームで、非常に使いやすいインターフェイスで機械学習分類器のパワーを活用します。
事前に学習された分類モデルを使用して、その機能を確認してください。
- NPS Survey Feedback Classifier: 自由形式のアンケート回答を、カスタマーサポート、使いやすさ、機能、および価格のカテゴリに自動的に分類します
- Sentiment Analyzer: あらゆるテキストについて意見極性を分析します。
- Email Intent Classifier:メールでの回答を、興味あり、興味なし、自動返信、メールバウンス、購読解除、人違いとして自動的に分類
または無料デモを予約して MonkeyLearn が提供するすべてを確認できます。