- Cos’è un classificatore?
- Algoritmi di classificazione
Un tempo era necessario avere un background di scienza dei dati e ingegneria per usare l’IA e il machine learning, ma nuovi strumenti facili da usare e piattaforme SaaS rendono il machine learning accessibile a tutti.
I classificatori di machine learning sono uno degli usi principali della tecnologia AI – per analizzare automaticamente i dati, ottimizzare i processi e raccogliere informazioni preziose.
- Che cos’è un classificatore nel machine learning?
- Qual è la differenza tra un classificatore e un modello?
- Test con il tuo testo
- Risultati
- 5 tipi di algoritmi di classificazione
- Albero di decisione
- Classificatore di Bayes ingenuo
- K-Nearest Neighbors
- Support Vector Machines (SVM)
- Reti neurali artificiali
- Metti i classificatori di machine learning a lavorare per te
Che cos’è un classificatore nel machine learning?
Un classificatore nel machine learning è un algoritmo che ordina o categorizza automaticamente i dati in una o più di una serie di “classi”. Uno degli esempi più comuni è un classificatore di email che analizza le email per filtrarle in base all’etichetta della classe: Spam o Not Spam.
Gli algoritmi di machine learning sono utili per automatizzare compiti che prima dovevano essere fatti manualmente. Possono far risparmiare enormi quantità di tempo e denaro e rendere le aziende più efficienti.
Qual è la differenza tra un classificatore e un modello?
Un classificatore è l’algoritmo stesso – le regole usate dalle macchine per classificare i dati. Un modello di classificazione, invece, è il risultato finale dell’apprendimento automatico del classificatore. Il modello viene addestrato utilizzando il classificatore, in modo che il modello, alla fine, classifichi i tuoi dati.
Ci sono sia classificatori supervisionati che non supervisionati. I classificatori di apprendimento automatico non supervisionati sono alimentati solo da set di dati non etichettati, che classificano in base al riconoscimento di modelli o strutture e anomalie nei dati. I classificatori supervisionati e semi-supervisionati sono alimentati con set di dati di addestramento, dai quali imparano a classificare i dati secondo categorie predeterminate.
L’analisi del sentimento è un esempio di apprendimento automatico supervisionato dove i classificatori sono addestrati ad analizzare il testo per la polarità dell’opinione e ad emettere il testo nella classe: Positivo, Neutro o Negativo. Prova questo modello di analisi del sentimento pre-addestrato per vedere come funziona.
Test con il tuo testo
Risultati
I classificatori di apprendimento automatico sono utilizzati per analizzare automaticamente i commenti dei clienti (come quello sopra) da social media, e-mail, recensioni online, ecc,
Altre tecniche di analisi del testo, come la classificazione per argomenti, possono ordinare automaticamente i ticket del servizio clienti o i sondaggi NPS, categorizzarli per argomento (prezzi, caratteristiche, supporto, ecc.) e indirizzarli al dipartimento o al dipendente corretto.
Le piattaforme di analisi del testo SaaS, come MonkeyLearn, danno facile accesso a potenti algoritmi di classificazione, permettendovi di costruire modelli di classificazione personalizzati in base alle vostre esigenze e criteri, di solito in pochi passaggi.
I classificatori di machine learning vanno oltre la semplice mappatura dei dati, permettendo agli utenti di aggiornare costantemente i modelli con nuovi dati di apprendimento e adattarli alle mutevoli esigenze. Le auto a guida autonoma, per esempio, usano algoritmi di classificazione per inserire i dati delle immagini in una categoria; che sia un segnale di stop, un pedone o un’altra auto, imparando costantemente e migliorando nel tempo.
Ma quali sono i principali algoritmi di classificazione e come funzionano?
5 tipi di algoritmi di classificazione
A seconda delle tue esigenze e dei tuoi dati, questi 5 principali algoritmi di classificazione ti dovrebbero coprire.
- Albero di decisione
- Classificatore di Bayes ingenuo
- K-Nearest Neighbors
- Support Vector Machines
- Reti neurali artificiali
Albero di decisione
Un albero di decisione è un algoritmo di classificazione supervisionato usato per costruire modelli come la struttura di un albero. Classifica i dati in categorie sempre più fini: dal “tronco dell’albero”, ai “rami”, alle “foglie”. Utilizza la regola if-then della matematica per creare sottocategorie che si inseriscono in categorie più ampie e permette una categorizzazione precisa e organica.
Per esempio, ecco come un albero decisionale classificherebbe i singoli sport:
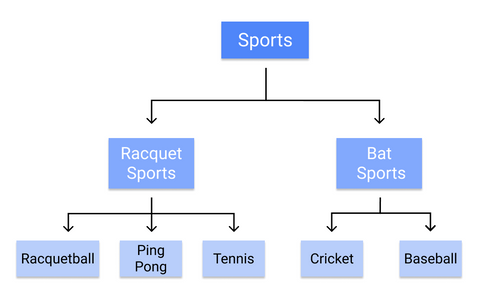
Poiché le regole vengono apprese in modo sequenziale, dal tronco alla foglia, un albero decisionale richiede dati di alta qualità e puliti fin dall’inizio dell’addestramento, o i rami potrebbero diventare troppo adattati o distorti.
Classificatore di Bayes ingenuo
Naive Bayes è una famiglia di algoritmi probabilistici che calcolano la possibilità che ogni dato punto possa rientrare in una o più di un gruppo di categorie (oppure no). Nell’analisi del testo, Naive Bayes è usato per categorizzare i commenti dei clienti, articoli di notizie, e-mail, ecc, in soggetti, argomenti o “tag” per organizzarli secondo criteri predeterminati, come questo:
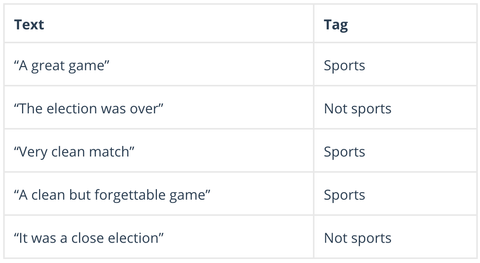
Gli algoritmi di Bayes ingenuo calcolano la probabilità di ogni tag per un dato testo, poi producono l’output per la probabilità più alta:

Significa che la probabilità di A, se B è vero, è uguale alla probabilità di B, se A è vero, per la probabilità che A sia vero, diviso la probabilità che B sia vero.
Muovendosi di tag in tag, questo calcola la probabilità che un punto di dati appartenga o meno a una certa categoria: Sì/No.
K-Nearest Neighbors
K-nearest neighbors (k-NN) è un algoritmo di riconoscimento dei modelli che memorizza e impara dai punti di dati di allenamento calcolando come essi corrispondono ad altri dati nello spazio n-dimensionale. K-NN mira a trovare i k punti di dati correlati più vicini in dati futuri, non visti.
Nell’analisi del testo, k-NN collocherebbe una data parola o frase all’interno di una categoria predeterminata calcolando il suo vicino più vicino: k è deciso da un voto plurale dei suoi vicini. Se k = 1, verrebbe etichettata nella classe più vicina a 1.
Support Vector Machines (SVM)
Gli algoritmi SVM classificano i dati e addestrano modelli entro gradi di polarità super finiti, creando un modello di classificazione tridimensionale che va oltre i semplici assi predittivi X/Y.
Guarda questa rappresentazione visiva per capire come funzionano gli algoritmi SVM. Abbiamo due tag: rosso e blu, con due caratteristiche di dati: X e Y, e addestriamo il nostro classificatore a produrre una coordinata X/Y come rossa o blu.
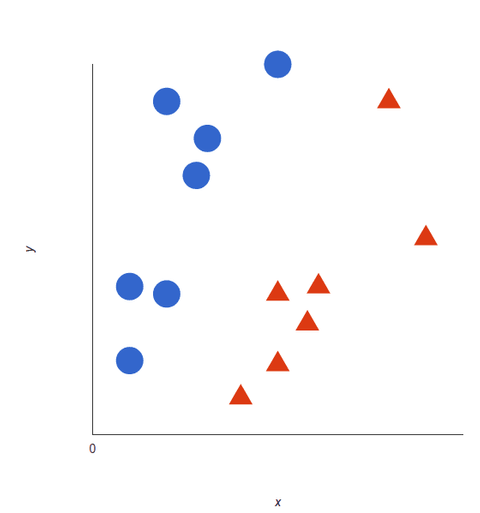
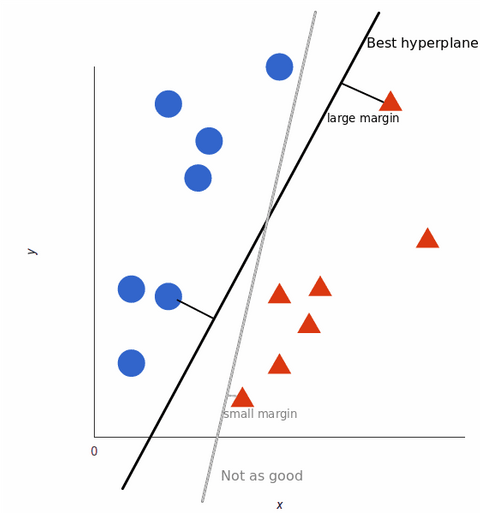
L’SVM assegna un iperpiano che separa (distingue) meglio le tag. In due dimensioni questo è semplicemente una linea retta. I tag blu cadono su un lato dell’iperpiano e quelli rossi sull’altro. Nella sentiment analysis questi tag sarebbero Positivo e Negativo.
Per massimizzare l’addestramento del modello di machine learning, l’iperpiano migliore è quello con la maggiore distanza tra ogni tag:
Come i nostri set di dati diventano più complessi, potrebbe non essere possibile tracciare una singola linea per distinguere le due classi:
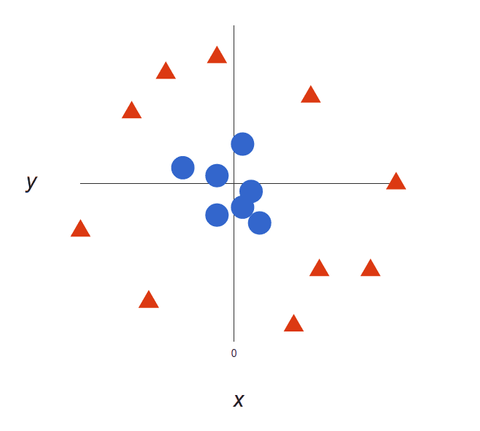
Gli algoritmi SVM sono eccellenti classificatori perché, più complessi sono i dati, più precisa sarà la previsione. Immaginate quanto sopra come un output tridimensionale, con un asse Z aggiunto, in modo che diventi un cerchio.
Mappato di nuovo in 2D, con il miglior iperpiano, appare così:
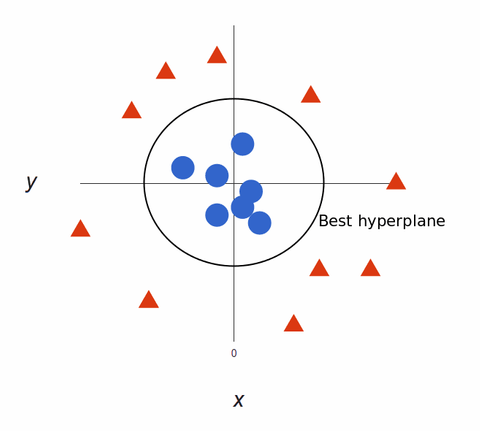
Gli algoritmiVM creano modelli di apprendimento automatico super accurati perché sono multidimensionali.
Reti neurali artificiali
Le reti neurali artificiali non sono un “tipo” di algoritmo, ma un insieme di algoritmi che lavorano insieme per risolvere i problemi. Collegano i processi di risoluzione dei problemi in una catena di eventi, in modo che una volta che un algoritmo o un processo ha risolto un problema, viene attivato l’algoritmo successivo (o l’anello della catena).
Le reti neurali artificiali o i modelli di “apprendimento profondo” richiedono grandi quantità di dati di allenamento perché i loro processi sono molto avanzati, ma una volta che sono stati addestrati correttamente, possono avere prestazioni superiori a quelle di altri algoritmi individuali.
Ci sono una varietà di reti neurali artificiali, comprese quelle convoluzionali, ricorrenti, feed-forward, ecc, e l’architettura di machine learning più adatta alle tue esigenze dipende dal problema che vuoi risolvere.
Metti i classificatori di machine learning a lavorare per te
Gli algoritmi di classificazione permettono l’automazione di compiti di machine learning che erano impensabili solo pochi anni fa. E, ancora meglio, ti permettono di addestrare i modelli AI alle necessità, alla lingua e ai criteri del tuo business, eseguendo molto più velocemente e con un livello di accuratezza maggiore di quanto potrebbero mai fare gli umani.
MonkeyLearn è una piattaforma di analisi testuale di apprendimento automatico che sfrutta la potenza dei classificatori di apprendimento automatico con un’interfaccia estremamente facile da usare, in modo che tu possa ottimizzare i processi e ottenere il massimo dai tuoi dati di testo per ottenere intuizioni preziose.
Prova questi modelli di classificazione pre-addestrati per vedere come funziona:
- NPS Survey Feedback Classifier: classifica automaticamente le risposte ai sondaggi a risposta aperta nelle categorie Supporto clienti, Facilità d’uso, Caratteristiche e Prezzi
- Sentiment Analyzer: analizza qualsiasi testo per la polarità delle opinioni: Positivo, Negativo, Neutrale
- Email Intent Classifier: classifica automaticamente le risposte via email come Interessato, Non Interessato, Autoresponder, Rimbalzo email, Disiscrizione, o Persona sbagliata
Organizza una demo gratuita per vedere tutto ciò che MonkeyLearn ha da offrire.