- Mi az az osztályozó?
- Osztályozó algoritmusok
Régebben az AI és a gépi tanulás használatához adattudományi és mérnöki háttérre volt szükség, de az új, felhasználóbarát eszközök és SaaS platformok mindenki számára elérhetővé teszik a gépi tanulást.
A gépi tanulás osztályozói az AI-technológia egyik legfontosabb felhasználási területe – az adatok automatikus elemzése, a folyamatok racionalizálása és értékes meglátások gyűjtése.
- Mi az osztályozó a gépi tanulásban?
- Mi a különbség egy osztályozó és egy modell között?
- Tesztelje saját szövegével
- Eredmények
- 5 típusú osztályozó algoritmus
- Döntésfa
- Naive Bayes osztályozó
- K-közelebbi szomszédok
- Support Vector Machines (SVM)
- Mesterséges neurális hálózatok
- A gépi tanulási osztályozókat az Ön szolgálatába állítjuk
Mi az osztályozó a gépi tanulásban?
A gépi tanulásban az osztályozó olyan algoritmus, amely az adatokat automatikusan egy vagy több “osztályba” sorolja vagy kategorizálja. Az egyik leggyakoribb példa egy e-mail osztályozó, amely az e-maileket vizsgálja, hogy osztálycímke szerint szűrje őket: Spam vagy nem spam.
A gépi tanulási algoritmusok segítenek olyan feladatok automatizálásában, amelyeket korábban kézzel kellett elvégezni. Hatalmas mennyiségű időt és pénzt takaríthatnak meg, és hatékonyabbá tehetik a vállalkozásokat.
Mi a különbség egy osztályozó és egy modell között?
A osztályozó maga az algoritmus – a gépek által az adatok osztályozására használt szabályok. Az osztályozó modell ezzel szemben az osztályozó gépi tanulásának végeredménye. A modellt az osztályozó segítségével képzik ki, így a modell végső soron osztályozza az adatokat.
Léteznek felügyelt és nem felügyelt osztályozók. A felügyelet nélküli gépi tanulási osztályozókat csak címkézetlen adatkészletekkel táplálják, amelyeket a mintafelismerés vagy az adatokban lévő struktúrák és anomáliák alapján osztályoznak. A felügyelt és félig felügyelt osztályozókat gyakorló adathalmazokkal táplálják, amelyekből megtanulják az adatokat előre meghatározott kategóriák szerint osztályozni.
A hangulatelemzés a felügyelt gépi tanulás egyik példája, ahol az osztályozókat arra képzik ki, hogy elemezzék a szöveget a vélemény polaritása szempontjából, és a szöveget az osztályba sorolják: Pozitív, semleges vagy negatív. Próbálja ki ezt az előre betanított hangulatelemző modellt, hogy megnézze, hogyan működik.
Tesztelje saját szövegével
Eredmények
A gépi tanulási osztályozókat a közösségi médiából, e-mailekből, online véleményekből stb. származó vásárlói megjegyzések automatikus elemzésére használják (mint a fenti), hogy kiderítsék, mit mondanak az ügyfelek a márkáról.
Más szövegelemzési technikák, például a témaosztályozás, automatikusan átválogathatják az ügyfélszolgálati jegyeket vagy NPS-felméréseket, témák szerint kategorizálhatják őket (árképzés, jellemzők, támogatás stb.), és a megfelelő osztályra vagy munkatárshoz irányíthatják őket.
Az olyan SaaS szövegelemző platformok, mint a MonkeyLearn, könnyű hozzáférést biztosítanak a nagy teljesítményű osztályozó algoritmusokhoz, lehetővé téve, hogy az Ön igényeihez és kritériumaihoz igazított osztályozási modelleket állítson össze, általában mindössze néhány lépésben.
A gépi tanulási osztályozók túlmutatnak az egyszerű adattérképezésen, lehetővé téve a felhasználók számára, hogy a modelleket folyamatosan frissítsék az új tanulási adatokkal, és a változó igényekhez igazítsák azokat. Az önvezető autók például osztályozó algoritmusokat használnak a képi adatok kategóriába történő bevitelére; legyen az egy stoptábla, egy gyalogos vagy egy másik autó, folyamatosan tanulnak és idővel javulnak.
De melyek a főbb osztályozó algoritmusok és hogyan működnek?
5 típusú osztályozó algoritmus
Az Ön igényeitől és adataitól függően az alábbi 5 legfontosabb osztályozó algoritmusnak kell megfelelnie.
- Döntésfa
- Naive Bayes osztályozó
- K-Nearest Neighbors
- Support Vector Machines
- Mesterséges neurális hálózatok
Döntésfa
A döntésfa egy felügyelt gépi tanulási osztályozó algoritmus, amelyet egy fa szerkezetéhez hasonló modellek felépítésére használnak. Az adatokat egyre finomabb és finomabb kategóriákba sorolja: a “fatörzstől” az “ágakon” át a “levelekig”. A matematika “ha-akkor” szabályát használja a tágabb kategóriákba illeszkedő alkategóriák létrehozására, és lehetővé teszi a pontos, szerves kategorizálást.
Egy döntési fa például így kategorizálná az egyes sportágakat:
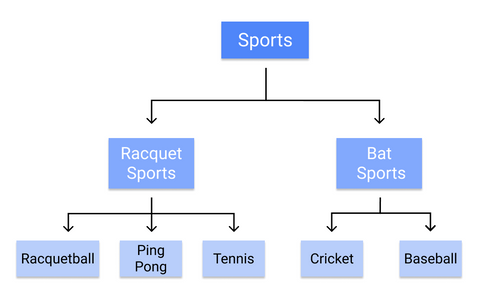
Mivel a szabályokat szekvenciálisan, a törzstől a levelekig tanuljuk, a döntési fának már a képzés kezdetétől fogva jó minőségű, tiszta adatokra van szüksége, különben az ágak túlságosan illeszkedőek vagy torzak lehetnek.
Naive Bayes osztályozó
A naiv Bayes a valószínűségi algoritmusok egy családja, amely kiszámítja annak a lehetőségét, hogy egy adott adatpont egy vagy több kategóriába tartozhat (vagy nem). A szövegelemzésben a Naive Bayes-t ügyfélmegjegyzések, hírcikkek, e-mailek stb. kategorizálására használják, témákba, témakörökbe vagy “címkékbe” sorolja, hogy előre meghatározott kritériumok szerint rendszerezze őket, például így:
A naiv Bayes algoritmusok kiszámítják az egyes címkék valószínűségét egy adott szöveg esetében, majd a legnagyobb valószínűségű kimenetet adják ki:

Ez azt jelenti, hogy A valószínűsége, ha B igaz, egyenlő B valószínűsége, ha A igaz, szorozva A valószínűségével, osztva B valószínűségével.
A címkéről címkére haladva ez kiszámítja annak valószínűségét, hogy egy adatpont egy adott kategóriába tartozik-e vagy sem: Igen/Nem.
K-közelebbi szomszédok
A K-közelebbi szomszédok (k-NN) egy mintafelismerő algoritmus, amely a képzési adatpontokat úgy tárolja és tanulja meg, hogy kiszámítja, hogyan felelnek meg más adatoknak az n-dimenziós térben. A K-NN célja, hogy megtalálja a k legközelebbi kapcsolódó adatpontokat a jövőbeli, nem látott adatokban.
A szövegelemzésben a k-NN egy adott szót vagy kifejezést egy előre meghatározott kategóriába helyezne a legközelebbi szomszédjának kiszámításával: a k-t a szomszédok többségi szavazata dönti el. Ha k = 1, akkor az 1-hez legközelebbi osztályba kerülne.
Support Vector Machines (SVM)
A SVM algoritmusok az adatokat osztályozzák és modelleket képeznek szuper véges polaritásfokozatokon belül, létrehozva egy 3 dimenziós osztályozási modellt, amely túlmutat az egyszerű X/Y előrejelző tengelyeken.
Nézze meg ezt a vizuális ábrázolást, hogy megértse az SVM algoritmusok működését. Két címkénk van: piros és kék, két adatjellemzővel: X és Y, és arra képezzük az osztályozót, hogy egy X/Y koordinátát pirosnak vagy kéknek adjon ki.
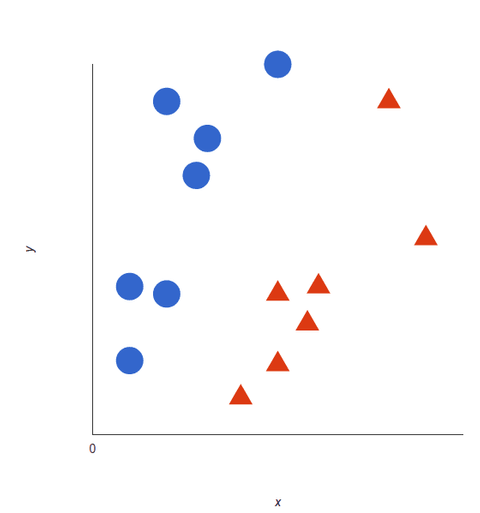
Az SVM hozzárendel egy hipersíkot, amely a legjobban elválasztja (megkülönbözteti) a címkéket. Két dimenzióban ez egyszerűen egy egyenes vonal. A kék címkék a hipersík egyik oldalára esnek, a pirosak pedig a másikra. A hangulatelemzésben ezek a címkék lennének a Pozitív és a Negatív.
A gépi tanulási modell képzésének maximalizálása érdekében a legjobb hipersík az, amelyik a legnagyobb távolsággal rendelkezik az egyes címkék között:
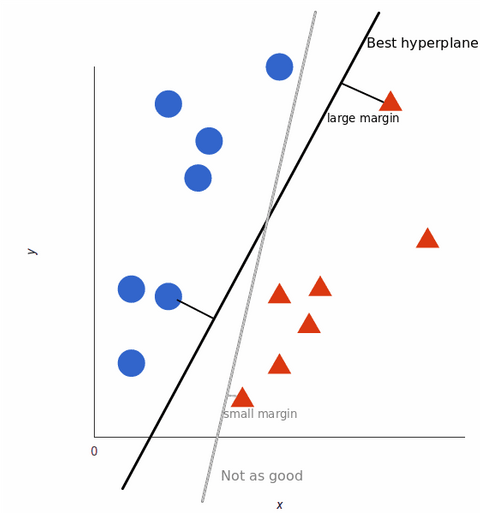
Amint adathalmazaink egyre összetettebbé válnak, előfordulhat, hogy nem lehet egyetlen vonalat húzni a két osztály megkülönböztetésére:
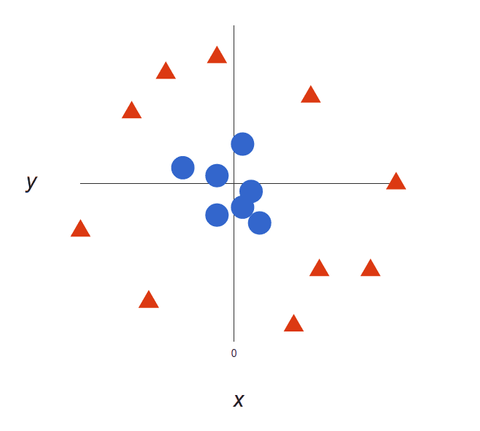
Az SVM algoritmusok kiváló osztályozók, mert minél összetettebbek az adatok, annál pontosabb lesz a jóslat. Képzeljük el a fentieket 3 dimenziós kimenetként, egy Z tengellyel kiegészítve, így körré válik.
Visszatérképezve 2D-re, a legjobb hipersíkkal, így néz ki:
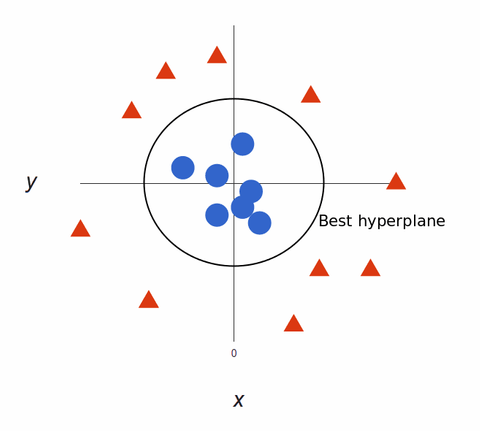
A SVM algoritmusok szuper pontos gépi tanulási modelleket hoznak létre, mert többdimenziósak.
Mesterséges neurális hálózatok
A mesterséges neurális hálózatok nem egy “algoritmustípus”, sokkal inkább algoritmusok gyűjteménye, amelyek együtt dolgoznak a problémák megoldásán.
A mesterséges neurális hálózatokat úgy tervezték, hogy az emberi agyhoz hasonlóan működjenek. A problémamegoldó folyamatokat egy láncolatba kapcsolják, így amint az egyik algoritmus vagy folyamat megoldott egy problémát, a következő algoritmus (vagy láncszem a láncban) aktiválódik.
A mesterséges neurális hálózatok vagy “mélytanulási” modellek hatalmas mennyiségű képzési adatot igényelnek, mivel folyamataik rendkívül fejlettek, de ha egyszer megfelelően betanították őket, képesek más, egyedi algoritmusokat meghaladó teljesítményre.
A mesterséges neurális hálózatok sokfélék lehetnek, például konvolúciós, rekurrens, feed-forward, stb, és az Ön igényeinek leginkább megfelelő gépi tanulási architektúra attól függ, hogy milyen problémát kíván megoldani.
A gépi tanulási osztályozókat az Ön szolgálatába állítjuk
A gépi tanulási osztályozó algoritmusok olyan gépi tanulási feladatok automatizálását teszik lehetővé, amelyek néhány évvel ezelőtt még elképzelhetetlenek voltak. És ami még ennél is jobb, lehetővé teszik, hogy a mesterséges intelligenciamodelleket az Ön igényei, nyelve és kritériumai szerint képezze ki, sokkal gyorsabban és nagyobb pontossággal teljesítve, mint az emberek valaha is képesek lennének.
A MonkeyLearn egy olyan gépi tanulási szövegelemző platform, amely a gépi tanulási osztályozók erejét rendkívül felhasználóbarát felülettel hasznosítja, így Ön racionalizálhatja a folyamatokat, és a legtöbbet hozhatja ki a szöveges adataiból az értékes meglátások érdekében.
Kipróbálhatja ezeket az előre betanított osztályozási modelleket, hogy megnézze, hogyan működik:
- NPS felmérés visszajelzés osztályozó: automatikusan osztályozza a nyílt végű felmérési válaszokat az ügyfélszolgálat, a használat egyszerűsége, a funkciók és az árképzés kategóriákba
- Sentiment Analyzer: elemezzen bármilyen szöveget a vélemény polaritás szempontjából: Pozitív, Negatív, Semleges
- Email Intent Classifier: automatikusan osztályozza az e-mail válaszokat Érdeklődés, Nem érdekel, Autoresponder, Email Bounce, Leiratkozás vagy Rossz személy
Vagy ütemezzen be egy ingyenes demót, hogy megnézze, mit kínál a MonkeyLearn.