- Wat is een Classifier?
- Classificatie-algoritmen
Vroeger had je een data science en engineering achtergrond nodig om AI en machine learning te gebruiken, maar nieuwe gebruiksvriendelijke tools en SaaS-platforms maken machine learning voor iedereen toegankelijk.
Machine learning classifiers zijn een van de belangrijkste toepassingen van AI-technologie – om automatisch gegevens te analyseren, processen te stroomlijnen en waardevolle inzichten te verzamelen.
- Wat is een classifier bij machine learning?
- Wat is het verschil tussen een classifier en een model?
- Test met uw eigen tekst
- Resultaten
- 5 soorten classificatiealgoritmen
- Decision Tree
- Naive Bayes Classifier
- K-Nearest Neighbors
- Support Vector Machines (SVM)
- Kunstmatige neurale netwerken
- Zet Machine Learning Classifiers aan het werk voor u
Wat is een classifier bij machine learning?
Een classifier bij machine learning is een algoritme dat automatisch gegevens ordent of categoriseert in een of meer van een reeks “klassen”. Een van de meest voorkomende voorbeelden is een e-mail classifier die e-mails scant om ze te filteren op klasse label: Spam of Not Spam.
Machine learning algoritmen zijn nuttig om taken te automatiseren die voorheen handmatig moesten worden gedaan. Ze kunnen enorme hoeveelheden tijd en geld besparen en bedrijven efficiënter maken.
Wat is het verschil tussen een classifier en een model?
Een classifier is het algoritme zelf – de regels die door machines worden gebruikt om gegevens te classificeren. Een classificatiemodel daarentegen is het eindresultaat van het machinaal leren van uw classificator. Het model wordt getraind met behulp van de classifier, zodat het model uiteindelijk uw gegevens classificeert.
Er zijn zowel gesuperviseerde als ongesuperviseerde classifiers. Niet-gesuperviseerde classificeerders voor machinaal leren krijgen alleen ongelabelde datasets te zien, die ze classificeren op basis van patroonherkenning of structuren en anomalieën in de gegevens. Gesuperviseerde en semi-gesuperviseerde classifiers worden gevoed met trainingsdatasets, waaruit zij leren gegevens te classificeren volgens vooraf bepaalde categorieën.
Sentimentanalyse is een voorbeeld van gesuperviseerd machinaal leren, waarbij classifiers worden getraind om tekst te analyseren op opiniepolariteit en de tekst in een bepaalde klasse in te delen: Positief, Neutraal, of Negatief. Probeer dit vooraf getrainde sentimentanalysemodel uit om te zien hoe het werkt.
Test met uw eigen tekst
Resultaten
Machine learning classifiers worden gebruikt voor het automatisch analyseren van opmerkingen van klanten (zoals hierboven) uit sociale media, e-mails, online reviews, enz,
Andere tekstanalysetechnieken, zoals onderwerpsclassificatie, kunnen automatisch tickets voor klantenservice of NPS-enquêtes sorteren, categoriseren op onderwerp (prijs, functies, ondersteuning, enz.) en ze doorsturen naar de juiste afdeling of medewerker.
SaaS tekstanalyse platforms, zoals MonkeyLearn, geven eenvoudig toegang tot krachtige classificatie algoritmen, waarmee u op maat gemaakte classificatie modellen kunt bouwen naar uw behoeften en criteria, meestal in slechts een paar stappen.
Machine learning classifiers gaan verder dan eenvoudige data mapping, waardoor gebruikers modellen voortdurend kunnen bijwerken met nieuwe leergegevens en aanpassen aan veranderende behoeften. Zelfrijdende auto’s gebruiken bijvoorbeeld classificatiealgoritmen om beeldgegevens in een categorie in te voeren; of het nu een stopteken, een voetganger of een andere auto is, ze leren voortdurend en verbeteren in de loop van de tijd.
Maar wat zijn de belangrijkste classificatiealgoritmen en hoe werken ze?
5 soorten classificatiealgoritmen
Afhankelijk van uw behoeften en uw gegevens, zou u met deze top 5 classificatiealgoritmen aan uw trekken moeten komen.
- Decision Tree
- Naive Bayes Classifier
- K-Nearest Neighbors
- Support Vector Machines
- Artificial Neural Networks
Decision Tree
Een beslissingsboom is een machine learning classificatie-algoritme dat wordt gebruikt om modellen te bouwen zoals de structuur van een boom. Het classificeert gegevens in steeds fijnere categorieën: van “boomstam”, naar “takken”, naar “bladeren”. Het gebruikt de als-dan-regel van de wiskunde om subcategorieën te creëren die in bredere categorieën passen en maakt precieze, organische categorisatie mogelijk.
Op deze manier zou een beslisboom bijvoorbeeld individuele sporten categoriseren:
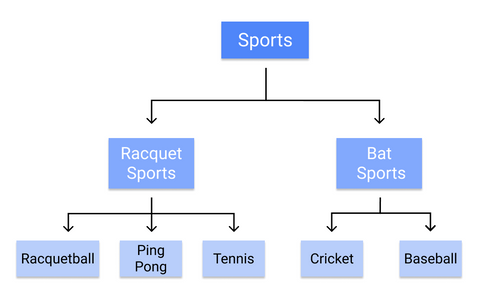
Aangezien de regels sequentieel worden geleerd, van stam tot blad, vereist een beslisboom vanaf het begin van de training schone gegevens van hoge kwaliteit, anders kunnen de takken overgepast of scheef worden.
Naive Bayes Classifier
Naive Bayes is een familie van probabilistische algoritmen die de mogelijkheid berekenen dat een gegeven gegeven gegevenspunt in een of meer van een groep categorieën kan vallen (of niet). In tekstanalyse wordt Naive Bayes gebruikt om commentaren van klanten, nieuwsartikelen, emails, enz, in onderwerpen, thema’s of “tags” om ze te ordenen volgens vooraf bepaalde criteria, zoals dit:
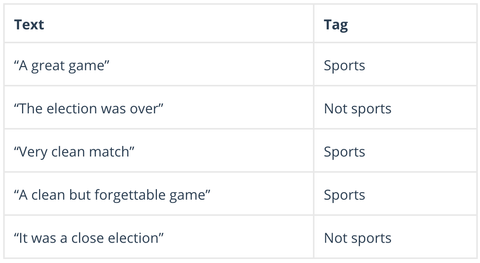
Naive Bayes-algoritmen berekenen de waarschijnlijkheid van elke tag voor een gegeven tekst, en voeren vervolgens uit voor de hoogste waarschijnlijkheid:

Dat wil zeggen dat de waarschijnlijkheid van A, als B waar is, gelijk is aan de waarschijnlijkheid van B, als A waar is, maal de waarschijnlijkheid van A dat A waar is, gedeeld door de waarschijnlijkheid van B dat B waar is.
Door van tag naar tag te gaan, wordt de waarschijnlijkheid berekend dat een gegevenspunt al dan niet in een bepaalde categorie thuishoort: Ja/Nee.
K-Nearest Neighbors
K-nearest neighbors (k-NN) is een patroonherkenningsalgoritme dat van trainingsdatapunten opslaat en leert door te berekenen hoe deze corresponderen met andere gegevens in een n-dimensionale ruimte.
In tekstanalyse zou k-NN een gegeven woord of zinsdeel in een vooraf bepaalde categorie plaatsen door de dichtstbijzijnde buur te berekenen: k wordt bepaald door een meervoudige stemming van de buren. Als k = 1, wordt het woord of de woordgroep ingedeeld in de dichtstbijzijnde 1.
Support Vector Machines (SVM)
SVM-algoritmen classificeren gegevens en trainen modellen binnen super-eindige graden van polariteit, waardoor een 3-dimensionaal classificatiemodel ontstaat dat verder gaat dan alleen X/Y voorspellende assen.
Kijk eens naar deze visuele weergave om te begrijpen hoe SVM-algoritmen werken. We hebben twee tags: rood en blauw, met twee gegevenskenmerken: X en Y, en we trainen onze classifier om een X/Y-coördinaat als rood of blauw te laten uitkomen.
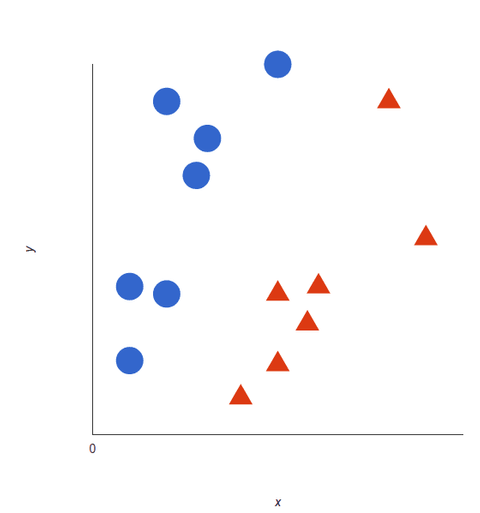
Het SVM wijst een hypervlak toe dat de tags het best scheidt (onderscheidt tussen). In twee dimensies is dit gewoon een rechte lijn. Blauwe tags vallen aan de ene kant van het hypervlak en rode aan de andere. In sentimentanalyse zouden deze tags positief en negatief zijn.
Om de training van het machine-learningmodel te maximaliseren, is de beste hyperplane die met de grootste afstand tussen elke tag:
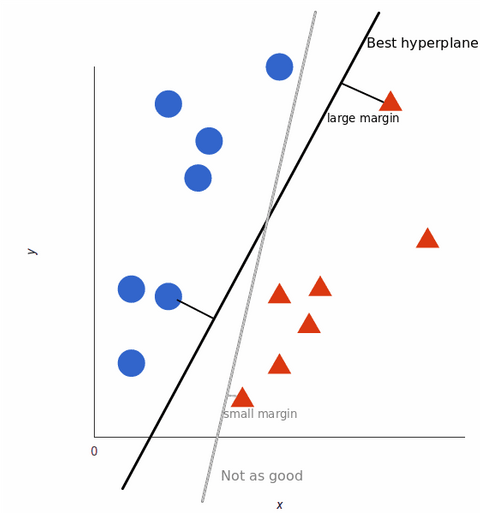
Als onze datasets complexer worden, is het wellicht niet mogelijk een enkele lijn te trekken om de twee klassen van elkaar te onderscheiden:
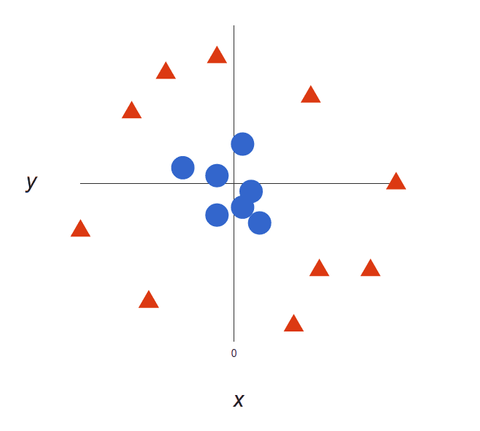
SVM-algoritmen zijn uitstekende classifiers, want hoe complexer de gegevens, des te nauwkeuriger de voorspelling zal zijn. Stel je het bovenstaande voor als een 3-dimensionale uitvoer, met een toegevoegde Z-as, zodat het een cirkel wordt.
Teruggekoppeld naar 2D, met het beste hypervlak, ziet het er zo uit:
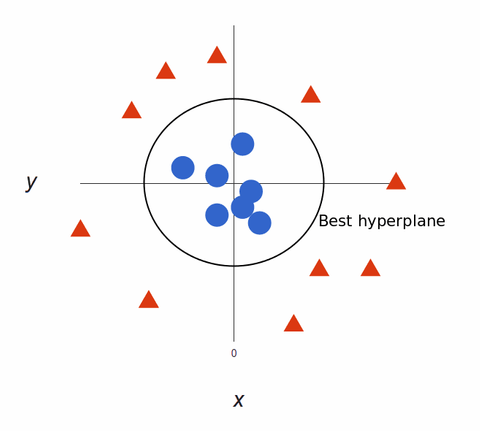
SVM-algoritmen creëren supernauwkeurige modellen voor machinaal leren, omdat ze multidimensionaal zijn.
Kunstmatige neurale netwerken
Kunstmatige neurale netwerken zijn niet zozeer een “type” algoritme, als wel een verzameling algoritmen die samenwerken om problemen op te lossen.
Kunstmatige neurale netwerken zijn ontworpen om te werken zoals het menselijk brein dat doet. Ze verbinden probleemoplossende processen in een keten van gebeurtenissen, zodat zodra een algoritme of proces een probleem heeft opgelost, het volgende algoritme (of schakel in de keten) wordt geactiveerd.
Kunstmatige neurale netwerken of “deep learning”-modellen vereisen enorme hoeveelheden trainingsgegevens omdat hun processen zeer geavanceerd zijn, maar zodra ze goed zijn getraind, kunnen ze beter presteren dan andere, individuele algoritmen.
Er zijn verschillende soorten kunstmatige neurale netwerken, waaronder convolutionele, recurrente, feed-forward, enz, en welke machine learning-architectuur het meest geschikt is voor uw behoeften, hangt af van het probleem dat u wilt oplossen.
Zet Machine Learning Classifiers aan het werk voor u
Classificatiealgoritmen maken de automatisering van machine learning-taken mogelijk die een paar jaar geleden nog ondenkbaar waren. En nog beter: u kunt AI-modellen trainen op de behoeften, taal en criteria van uw bedrijf, zodat ze veel sneller en nauwkeuriger werken dan mensen ooit zouden kunnen.
MonkeyLearn is een machine learning platform voor tekstanalyse dat de kracht van machine learning classifiers benut met een buitengewoon gebruiksvriendelijke interface, zodat u processen kunt stroomlijnen en het meeste uit uw tekstgegevens kunt halen voor waardevolle inzichten.
Probeer deze vooraf getrainde classificatiemodellen om te zien hoe het werkt:
- NPS Survey Feedback Classifier: classificeer automatisch reacties op open enquêtes in de categorieën Klantenondersteuning, Gebruiksgemak, Functies en Prijs
- Sentimentanalysator: analyseer elke tekst op opiniepolariteit: Positief, Negatief, Neutraal
- E-mail Intent Classifier: classificeer automatisch e-mail reacties als Geïnteresseerd, Niet Geïnteresseerd, Autoresponder, E-mail Bounce, Uitschrijven, of Verkeerde persoon
Of plan een gratis demo om alles te zien wat MonkeyLearn te bieden heeft.