- Co to jest klasyfikator?
- Algorytmy klasyfikacyjne
Niegdyś, aby korzystać z AI i uczenia maszynowego, trzeba było posiadać wiedzę z zakresu data science i inżynierii, ale nowe, przyjazne dla użytkownika narzędzia i platformy SaaS sprawiają, że uczenie maszynowe jest dostępne dla każdego.
Klasyfikatory uczenia maszynowego są jednym z głównych zastosowań technologii AI – do automatycznej analizy danych, usprawniania procesów i zbierania cennych informacji.
- Co to jest klasyfikator w uczeniu maszynowym?
- Jaka jest różnica między klasyfikatorem a modelem?
- Testuj z własnym tekstem
- Wyniki
- 5 typów algorytmów klasyfikacji
- Drzewo decyzyjne
- Klasyfikator Naiwnego Bayesa
- K-Nearest Neighbors
- Support Vector Machines (SVM)
- Sztuczne sieci neuronowe
- Put Machine Learning Classifiers to Work for You
Co to jest klasyfikator w uczeniu maszynowym?
Klasyfikator w uczeniu maszynowym to algorytm, który automatycznie porządkuje lub kategoryzuje dane do jednej lub więcej z zestawu „klas”. Jednym z najczęstszych przykładów jest klasyfikator wiadomości e-mail, który skanuje wiadomości e-mail, aby przefiltrować je według etykiety klasy: Spam lub Nie Spam.
Algorytmy uczenia maszynowego są pomocne w automatyzacji zadań, które wcześniej musiały być wykonywane ręcznie. Dzięki nim można zaoszczędzić ogromne ilości czasu i pieniędzy, a firmy stają się bardziej wydajne.
Jaka jest różnica między klasyfikatorem a modelem?
Klasyfikator to sam algorytm – reguły używane przez maszyny do klasyfikowania danych. Z drugiej strony, model klasyfikacyjny jest końcowym rezultatem uczenia maszynowego klasyfikatora. Model jest trenowany przy użyciu klasyfikatora, dzięki czemu model ostatecznie klasyfikuje dane.
Istnieją zarówno klasyfikatory nadzorowane, jak i nienadzorowane. Nienadzorowane klasyfikatory uczenia maszynowego są zasilane tylko nieoznakowanymi zestawami danych, które klasyfikują na podstawie rozpoznawania wzorców lub struktur i anomalii w danych. Klasyfikatory nadzorowane i częściowo nadzorowane są zasilane zestawami danych treningowych, z których uczą się klasyfikować dane zgodnie z wcześniej ustalonymi kategoriami.
Analiza nastrojów jest przykładem nadzorowanego uczenia maszynowego, gdzie klasyfikatory są szkolone do analizy tekstu pod kątem polaryzacji opinii i przypisania tekstu do klasy: Pozytywny, Neutralny lub Negatywny. Wypróbuj ten wstępnie wytrenowany model analizy sentymentu, aby zobaczyć jak to działa.
Testuj z własnym tekstem
Wyniki
Klasyfikatory uczenia maszynowego są wykorzystywane do automatycznej analizy komentarzy klientów (takich jak powyższy) z mediów społecznościowych, e-maili, recenzji online, itp, aby dowiedzieć się, co klienci mówią o Twojej marce.
Inne techniki analizy tekstu, takie jak klasyfikacja tematyczna, mogą automatycznie sortować bilety obsługi klienta lub ankiety NPS, kategoryzować je według tematu (Ceny, Funkcje, Wsparcie, itp.) i kierować je do odpowiedniego działu lub pracownika.
Platformy do analizy tekstu typu SaaS, takie jak MonkeyLearn, dają łatwy dostęp do potężnych algorytmów klasyfikacyjnych, pozwalając na budowanie modeli klasyfikacyjnych dostosowanych do potrzeb i kryteriów użytkownika, zazwyczaj w zaledwie kilku krokach.
Klasyfikatory uczenia maszynowego wykraczają poza proste mapowanie danych, pozwalając użytkownikom na ciągłe aktualizowanie modeli za pomocą nowych danych i dostosowywanie ich do zmieniających się potrzeb. Samojeżdżące samochody, na przykład, używają algorytmów klasyfikacji do wprowadzania danych obrazu do kategorii; czy jest to znak stopu, pieszy, czy inny samochód, stale ucząc się i poprawiając w czasie.
Ale jakie są główne algorytmy klasyfikacji i jak one działają?
5 typów algorytmów klasyfikacji
Zależnie od Twoich potrzeb i danych, te 5 najlepszych algorytmów klasyfikacji powinno Cię objąć.
- Drzewo decyzyjne
- Naive Bayes Classifier
- K-Nearest Neighbors
- Support Vector Machines
- Artificial Neural Networks
Drzewo decyzyjne
Drzewo decyzyjne jest nadzorowanym algorytmem klasyfikacji uczenia maszynowego używanym do budowania modeli o strukturze drzewa. Klasyfikuje dane na coraz to drobniejsze kategorie: od „pnia drzewa”, poprzez „gałęzie”, aż do „liści”. Wykorzystuje matematyczną zasadę „jeśli – to” do tworzenia podkategorii, które pasują do szerszych kategorii i pozwala na precyzyjną, organiczną kategoryzację.
Na przykład, w ten sposób drzewo decyzyjne sklasyfikowałoby poszczególne dyscypliny sportowe:
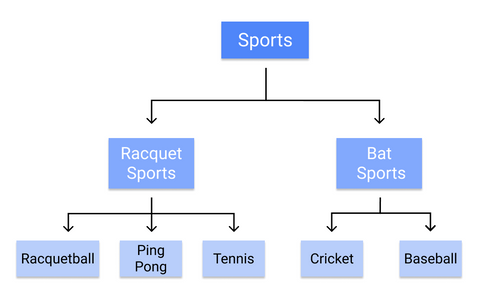
Ponieważ reguły uczone są sekwencyjnie, od pnia do liścia, drzewo decyzyjne wymaga wysokiej jakości, czystych danych od samego początku szkolenia, w przeciwnym razie gałęzie mogą zostać nadmiernie dopasowane lub przekrzywione.
Klasyfikator Naiwnego Bayesa
Naiwny Bayes to rodzina algorytmów probabilistycznych, które obliczają prawdopodobieństwo, że dowolny punkt danych może należeć do jednej lub więcej z grupy kategorii (lub nie). W analizie tekstu, Naive Bayes jest używany do kategoryzowania komentarzy klientów, artykułów informacyjnych, e-maili, itp, do tematów, zagadnień lub „tagów”, aby zorganizować je zgodnie z wcześniej ustalonymi kryteriami, jak poniżej:
Algorytmy Naive Bayes obliczają prawdopodobieństwo każdego tagu dla danego tekstu, a następnie wychodzą dla najwyższego prawdopodobieństwa:

Mając na myśli, że prawdopodobieństwo A, jeśli B jest prawdziwe, jest równe prawdopodobieństwu B, jeśli A jest prawdziwe, razy prawdopodobieństwo A bycia prawdziwym, podzielone przez prawdopodobieństwo B bycia prawdziwym.
Przechodząc od znacznika do znacznika, oblicza się prawdopodobieństwo, że punkt danych należy do określonej kategorii lub nie: Yes/No.
K-Nearest Neighbors
K-nearest neighbors (k-NN) to algorytm rozpoznawania wzorców, który przechowuje i uczy się na podstawie szkoleniowych punktów danych, obliczając, jak odpowiadają one innym danym w przestrzeni n-wymiarowej. K-NN ma na celu znalezienie k najbliżej spokrewnionych punktów danych w przyszłych, niewidzianych danych.
W analizie tekstu, k-NN umieściłby dane słowo lub frazę w określonej kategorii poprzez obliczenie jej najbliższego sąsiada: k jest ustalane przez głosowanie mnogiej liczby sąsiadów. Jeśli k = 1, słowo lub wyrażenie zostanie przypisane do klasy najbliższej 1.
Support Vector Machines (SVM)
Algorytmy SVM klasyfikują dane i trenują modele w ramach super skończonych stopni polaryzacji, tworząc trójwymiarowy model klasyfikacyjny, który wykracza poza osie predykcyjne X/Y.
Spójrz na tę wizualną reprezentację, aby zrozumieć, jak działają algorytmy SVM. Mamy dwa znaczniki: czerwony i niebieski, z dwoma cechami danych: X i Y, i trenujemy nasz klasyfikator, aby wyprowadził współrzędną X/Y jako czerwoną lub niebieską.
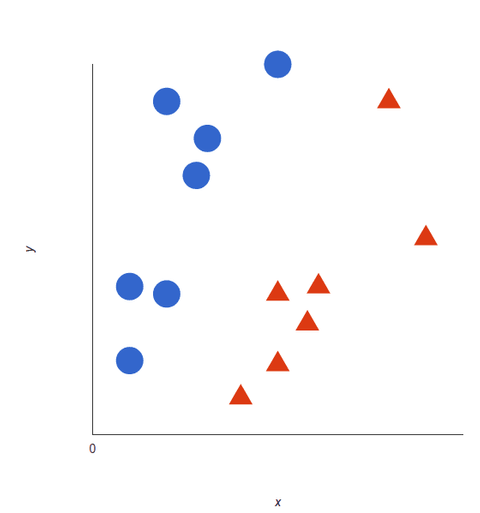
SVM przypisuje hiperpłaszczyznę, która najlepiej oddziela (rozróżnia) znaczniki. W dwóch wymiarach jest to po prostu linia prosta. Niebieskie tagi znajdują się po jednej stronie hiperpłaszczyzny, a czerwone po drugiej. W analizie sentymentu byłyby to znaczniki pozytywne i negatywne.
Aby zmaksymalizować szkolenie modelu uczenia maszynowego, najlepszą hiperpłaszczyzną jest ta z największą odległością pomiędzy każdym znacznikiem:
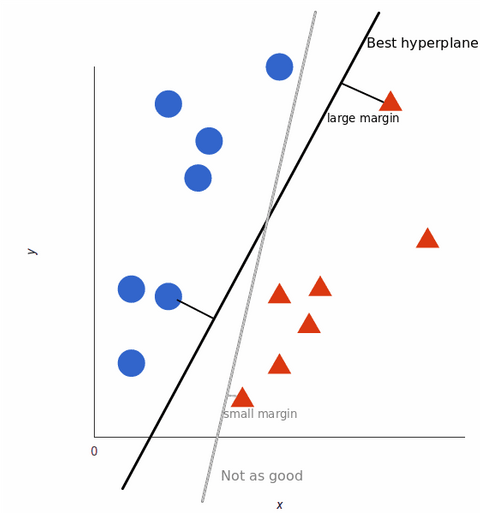
Jak nasze zbiory danych stają się bardziej złożone, może nie być możliwe narysowanie pojedynczej linii rozróżniającej dwie klasy:
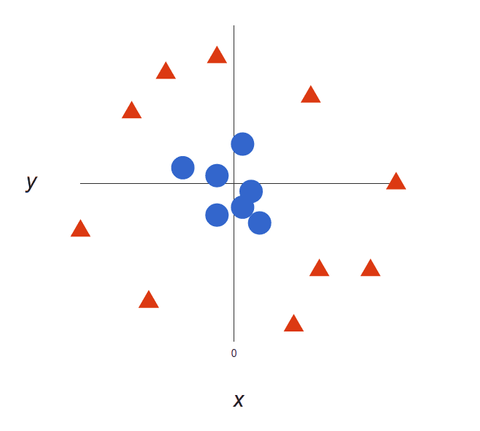
Algorytmy SVM są doskonałymi klasyfikatorami, ponieważ im bardziej złożone dane, tym dokładniejsze będzie przewidywanie. Wyobraźmy sobie powyższe jako trójwymiarowe dane wyjściowe, z dodaną osią Z, więc staje się to okręgiem.
Mapped back to 2D, z najlepszą hiperpłaszczyzną, wygląda to tak:
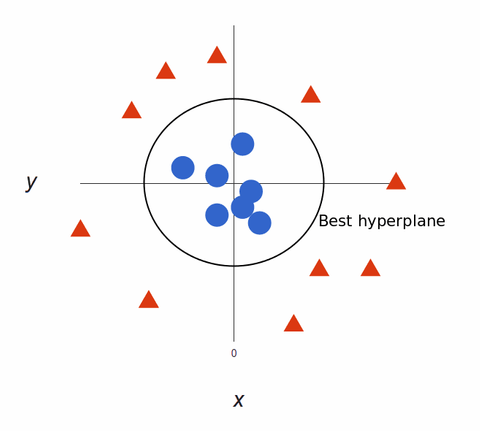
Algorytmy SVM tworzą super dokładne modele uczenia maszynowego, ponieważ są wielowymiarowe.
Sztuczne sieci neuronowe
Sztuczne sieci neuronowe nie są „typem” algorytmu, ale zbiorem algorytmów, które współpracują ze sobą w celu rozwiązywania problemów.
Sztuczne sieci neuronowe zostały zaprojektowane tak, aby działać podobnie jak ludzki mózg. Łączą procesy rozwiązywania problemów w łańcuch zdarzeń, tak że gdy jeden algorytm lub proces rozwiąże problem, aktywowany jest następny algorytm (lub ogniwo w łańcuchu).
Sztuczne sieci neuronowe lub modele „głębokiego uczenia” wymagają ogromnej ilości danych szkoleniowych, ponieważ ich procesy są bardzo zaawansowane, ale gdy zostaną odpowiednio przeszkolone, mogą osiągać wyniki przewyższające inne, indywidualne algorytmy.
Istnieją różne rodzaje sztucznych sieci neuronowych, w tym konwolucyjne, rekurencyjne, feed-forward itp, a architektura uczenia maszynowego najlepiej odpowiadająca Twoim potrzebom zależy od problemu, który chcesz rozwiązać.
Put Machine Learning Classifiers to Work for You
Algorytmy klasyfikacji umożliwiają automatyzację zadań uczenia maszynowego, które były nie do pomyślenia zaledwie kilka lat temu. Co więcej, pozwalają one trenować modele AI do potrzeb, języka i kryteriów Twojej firmy, działając znacznie szybciej i z większą dokładnością niż ludzie kiedykolwiek byli w stanie.
MonkeyLearn to platforma do analizy tekstu, która wykorzystuje moc klasyfikatorów uczenia maszynowego z niezwykle przyjaznym dla użytkownika interfejsem, dzięki czemu możesz usprawnić procesy i w pełni wykorzystać swoje dane tekstowe, aby uzyskać cenne spostrzeżenia.
Wypróbuj te wstępnie wytrenowane modele klasyfikacyjne, aby zobaczyć, jak to działa:
- Klasyfikator opinii w ankietach NPS: automatycznie klasyfikuje otwarte odpowiedzi w ankietach w kategoriach Obsługa klienta, Łatwość użycia, Funkcje i Ceny
- Analizator nastrojów: analizuje dowolny tekst pod kątem polaryzacji opinii: Pozytywna, Negatywna, Neutralna
- Klasyfikator intencji email: automatycznie klasyfikuj odpowiedzi email jako Zainteresowane, Niezainteresowane, Autoresponder, Email Bounce, Unsubscribe lub Niewłaściwa osoba
Zaplanuj darmowe demo, aby zobaczyć wszystko, co MonkeyLearn ma do zaoferowania.
Zaplanuj darmowe demo, aby zobaczyć wszystko, co MonkeyLearn ma do zaoferowania.