- Co je klasifikátor?
- Klasifikační algoritmy
Dříve platilo, že k používání umělé inteligence a strojového učení je třeba mít datové a inženýrské vzdělání, ale nové uživatelsky přívětivé nástroje a platformy SaaS zpřístupňují strojové učení každému.
Klasifikátory strojového učení jsou jedním z nejlepších způsobů využití technologie AI – slouží k automatické analýze dat, zefektivnění procesů a získávání cenných poznatků.
- Co je klasifikátor ve strojovém učení?
- Jaký je rozdíl mezi klasifikátorem a modelem?
- Test s vlastním textem
- Výsledky
- 5 typů klasifikačních algoritmů
- Rozhodovací strom
- Naivní Bayesův klasifikátor
- K-nejbližší sousedé
- Support Vector Machines (SVM)
- Umělé neuronové sítě
- Put Machine Learning Classifiers to Work for You
Co je klasifikátor ve strojovém učení?
Klasifikátor ve strojovém učení je algoritmus, který automaticky řadí nebo kategorizuje data do jedné nebo více ze sady „tříd“. Jedním z nejběžnějších příkladů je klasifikátor e-mailů, který prohledává e-maily a filtruje je podle označení třídy:
Algoritmy strojového učení pomáhají automatizovat úlohy, které se dříve musely provádět ručně. Mohou ušetřit obrovské množství času a peněz a zefektivnit podnikání.
Jaký je rozdíl mezi klasifikátorem a modelem?
Klasifikátor je samotný algoritmus – pravidla, která stroje používají ke klasifikaci dat. Klasifikační model je naproti tomu konečný výsledek strojového učení klasifikátoru. Model je vycvičen pomocí klasifikátoru, takže model nakonec klasifikuje vaše data.
Existují klasifikátory pod dohledem i bez dohledu. Klasifikátorům strojového učení bez dohledu se podávají pouze neoznačené soubory dat, které klasifikují podle rozpoznávání vzorů nebo struktur a anomálií v datech. Supervidované a částečně supervidované klasifikátory jsou krmeny trénovacími datovými sadami, ze kterých se učí klasifikovat data podle předem stanovených kategorií.
Analýza názorů je příkladem supervidovaného strojového učení, kdy jsou klasifikátory vyškoleny k analýze textu na názorovou polaritu a výstupu textu do dané třídy: Kladný, Neutrální nebo Záporný. Vyzkoušejte tento předtrénovaný model analýzy sentimentu a zjistěte, jak funguje.
Test s vlastním textem
Výsledky
Klasifikátory strojového učení se používají k automatické analýze komentářů zákazníků (jako výše uvedené) ze sociálních médií, e-mailů, online recenzí apod, abyste zjistili, co zákazníci říkají o vaší značce.
Další techniky analýzy textu, jako je klasifikace témat, mohou automaticky třídit lístky zákaznického servisu nebo průzkumy NPS, kategorizovat je podle témat (ceny, funkce, podpora atd.) a směrovat je na správné oddělení nebo zaměstnance.
Platformy pro analýzu textu typu SaaS, jako je MonkeyLearn, poskytují snadný přístup k výkonným klasifikačním algoritmům a umožňují sestavit klasifikační modely na míru vašim potřebám a kritériím, obvykle v několika málo krocích.
Klasifikátory strojového učení jdou nad rámec jednoduchého mapování dat a umožňují uživatelům neustále aktualizovat modely pomocí nových učebních dat a přizpůsobovat je měnícím se potřebám. Například samořiditelná auta používají klasifikační algoritmy pro zadávání obrazových dat do kategorie; ať už se jedná o značku zastávky, chodce nebo jiné auto, neustále se učí a v průběhu času se zlepšují.
Ale jaké jsou hlavní klasifikační algoritmy a jak fungují?
5 typů klasifikačních algoritmů
V závislosti na vašich potřebách a datech by vám mělo pomoci těchto 5 hlavních klasifikačních algoritmů.
- Rozhodovací strom
- Naivní Bayesův klasifikátor
- K-nejbližší sousedé
- Support Vector Machines
- Umělé neuronové sítě
Rozhodovací strom
Rozhodovací strom je klasifikační algoritmus strojového učení s dohledem, který se používá k vytváření modelů podobných struktuře stromu. Klasifikuje data do stále jemnějších kategorií: od „kmene stromu“ přes „větve“ až po „listy“. Využívá matematické pravidlo if-then k vytváření podkategorií, které zapadají do širších kategorií, a umožňuje přesnou, organickou kategorizaci.
Například takto by rozhodovací strom kategorizoval jednotlivé sporty:
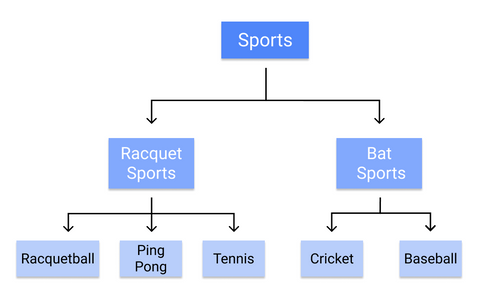
Jelikož se pravidla učí postupně, od kmene k listu, vyžaduje rozhodovací strom od počátku trénování kvalitní a čistá data, jinak může dojít k nadměrnému přizpůsobení nebo zkreslení větví.
Naivní Bayesův klasifikátor
Naivní Bayes je rodina pravděpodobnostních algoritmů, které vypočítávají možnost, že libovolný datový bod může spadat do jedné nebo více skupin kategorií (nebo také ne). V analýze textu se Naive Bayes používá ke kategorizaci komentářů zákazníků, novinových článků, e-mailů apod, do předmětů, témat nebo „značek“ k jejich uspořádání podle předem stanovených kritérií, jako například takto:
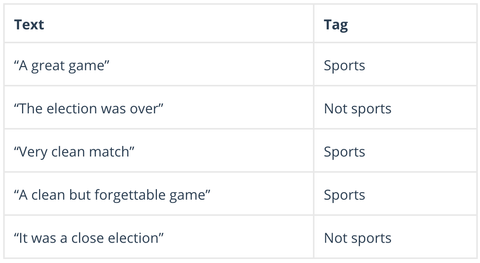
Algoritmy Naive Bayes vypočítají pravděpodobnost každého tagu pro daný text a poté vydají výstup pro nejvyšší pravděpodobnost:

To znamená, že pravděpodobnost A, pokud je B pravdivé, se rovná pravděpodobnosti B, pokud je A pravdivé, krát pravděpodobnost A, která je pravdivá, děleno pravděpodobností B, která je pravdivá.
Přesunem od značky ke značce se vypočítá pravděpodobnost, zda datový bod patří do určité kategorie, nebo ne:
K-nejbližší sousedé
K-nejbližší sousedé (k-NN) je algoritmus rozpoznávání vzorů, který ukládá a učí se z trénovacích datových bodů tím, že počítá, jak odpovídají jiným datům v n-rozměrném prostoru. Cílem k-NN je najít k nejbližších příbuzných datových bodů v budoucích, nezkoumaných datech.
V analýze textu by k-NN zařadil dané slovo nebo frázi do předem určené kategorie výpočtem jeho nejbližšího souseda: o k rozhoduje většinové hlasování jeho sousedů. Pokud by k = 1, bylo by zařazeno do třídy nejbližší 1.
Support Vector Machines (SVM)
Algoritmy SVM klasifikují data a trénují modely v rámci superkonečných stupňů polarity, čímž vytvářejí třírozměrný klasifikační model, který přesahuje pouhé predikční osy X/Y.
Podívejte se na toto vizuální znázornění, abyste pochopili, jak algoritmy SVM fungují. Máme dvě značky: červenou a modrou, se dvěma datovými prvky:
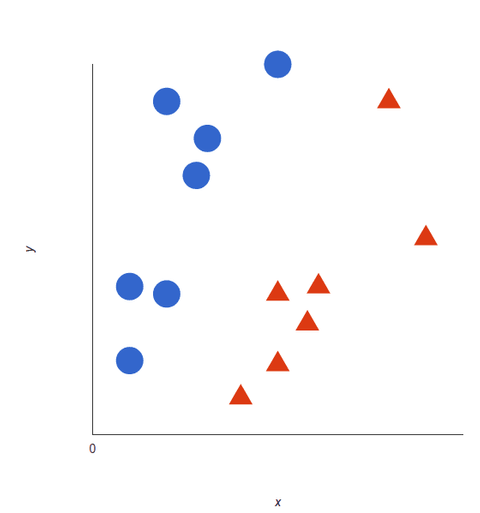
Model SVM přiřadí hyperrovinu, která nejlépe odděluje (rozlišuje) tagy. Ve dvou rozměrech je to jednoduše přímka. Modré tagy spadají na jednu stranu hyperplochy a červené na druhou. V analýze sentimentu by tyto značky byly Pozitivní a Negativní.
Pro maximalizaci trénování modelu strojového učení je nejlepší hyperrovina ta, která má největší vzdálenost mezi jednotlivými značkami:
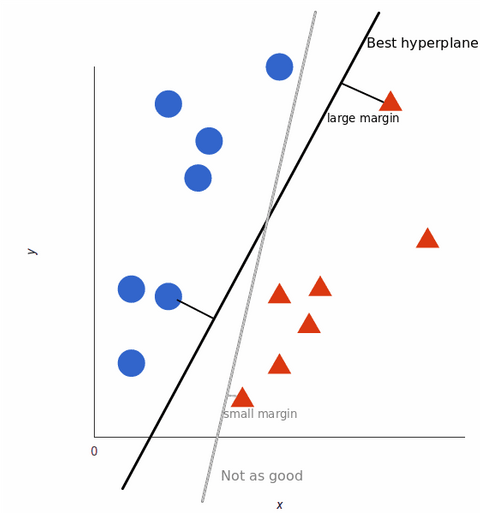
Když jsou naše datové sady složitější, nemusí být možné nakreslit jedinou přímku, která by rozlišila obě třídy:
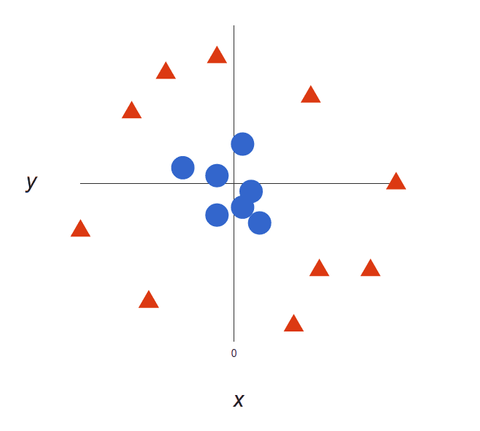
Algoritmy SVM jsou vynikajícími klasifikátory, protože čím složitější jsou data, tím přesnější bude předpověď. Představte si výše uvedený výstup jako trojrozměrný s přidanou osou Z, takže se z něj stane kruh.
Převedeno zpět do 2D, s nejlepší hyperplochou, vypadá takto:
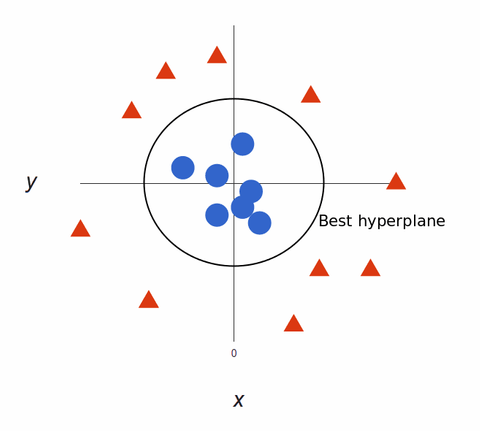
Algoritmy SVM vytvářejí superpřesné modely strojového učení, protože jsou vícerozměrné.
Umělé neuronové sítě
Umělé neuronové sítě nejsou ani tak „typem“ algoritmu, jako spíše souborem algoritmů, které spolupracují při řešení problémů.
Umělé neuronové sítě jsou navrženy tak, aby pracovaly podobně jako lidský mozek. Propojují procesy řešení problémů do řetězce událostí, takže jakmile jeden algoritmus nebo proces vyřeší problém, aktivuje se další algoritmus (nebo článek řetězce).
Umělé neuronové sítě nebo modely „hlubokého učení“ vyžadují obrovské množství tréninkových dat, protože jejich procesy jsou vysoce pokročilé, ale jakmile jsou řádně vyškoleny, mohou dosahovat výkonů, které předčí ostatní, jednotlivé algoritmy.
Existuje celá řada umělých neuronových sítí, včetně konvolučních, rekurentních, feed-forward atd, a architektura strojového učení, která nejlépe vyhovuje vašim potřebám, závisí na problému, který chcete vyřešit.
Put Machine Learning Classifiers to Work for You
Klasifikační algoritmy umožňují automatizaci úloh strojového učení, které byly ještě před několika lety nemyslitelné. A co je ještě lepší, umožňují trénovat modely umělé inteligence podle potřeb, jazyka a kritérií vaší firmy, které fungují mnohem rychleji a s větší přesností, než by kdy dokázali lidé.
MonkeyLearn je platforma pro strojovou analýzu textu, která využívá sílu klasifikátorů strojového učení s mimořádně přívětivým uživatelským rozhraním, takže můžete zefektivnit procesy a získat z textových dat maximum cenných poznatků.
Vyzkoušejte tyto předtrénované klasifikační modely a zjistěte, jak to funguje:
- Klasifikátor zpětné vazby z průzkumu NPS: automaticky klasifikuje odpovědi z otevřených průzkumů do kategorií Zákaznická podpora, Snadnost použití, Funkce a Cena
- Analyzátor sentimentu: analyzuje jakýkoli text z hlediska názorové polarity: Pozitivní, Negativní, Neutrální
- Klasifikátor e-mailových záměrů: automaticky klasifikuje e-mailové odpovědi jako Zájem, Nezájem, Automatický odesílatel, E-mail Bounce, Odhlásit nebo Špatná osoba
Nebo si naplánujte bezplatnou ukázku a podívejte se, co všechno MonkeyLearn nabízí.