- ¿Qué es un clasificador?
- Algoritmos de clasificación
- ¿Qué es un clasificador en el aprendizaje automático?
- ¿Cuál es la diferencia entre un clasificador y un modelo?
- Prueba con tu propio texto
- Resultados
- 5 tipos de algoritmos de clasificación
- Árbol de decisión
- Clasificador Naive Bayes
- K-Nearest Neighbors
- Máquinas de vectores de soporte (SVM)
- Redes neuronales artificiales
- Ponga los clasificadores de aprendizaje automático a trabajar para usted
- Árbol de decisión
- Clasificador de Bayes ingenuo
- K-Nearest Neighbors
- Máquinas de vectores de apoyo
- Redes neuronales artificiales
- Clasificador de opiniones de la encuesta NPS: clasifica automáticamente las respuestas de la encuesta abierta en las categorías Asistencia al cliente, Facilidad de uso, Características y Precio
- Analizador de sentimientos: analiza cualquier texto para la polaridad de la opinión: Positivo, Negativo, Neutral
- Clasificador de intención de correo electrónico: clasifica automáticamente las respuestas de correo electrónico como Interesado, No interesado, Autorespuesta, Rebote de correo electrónico, Desuscripción o Persona equivocada
Antes era necesario tener conocimientos de ciencia de datos e ingeniería para utilizar la IA y el aprendizaje automático, pero las nuevas herramientas de fácil uso y las plataformas SaaS hacen que el aprendizaje automático sea accesible para todos.
Los clasificadores de aprendizaje automático son uno de los principales usos de la tecnología de IA: para analizar automáticamente los datos, agilizar los procesos y reunir información valiosa.
¿Qué es un clasificador en el aprendizaje automático?
Un clasificador en el aprendizaje automático es un algoritmo que ordena o categoriza automáticamente los datos en una o más de un conjunto de «clases». Uno de los ejemplos más comunes es un clasificador de correo electrónico que analiza los correos electrónicos para filtrarlos por la etiqueta de clase: Spam o No Spam.
Los algoritmos de aprendizaje automático son útiles para automatizar tareas que antes tenían que hacerse manualmente. Pueden ahorrar enormes cantidades de tiempo y dinero y hacer que las empresas sean más eficientes.
¿Cuál es la diferencia entre un clasificador y un modelo?
Un clasificador es el algoritmo en sí mismo: las reglas que utilizan las máquinas para clasificar los datos. Un modelo de clasificación, por otro lado, es el resultado final del aprendizaje automático de su clasificador. El modelo se entrena utilizando el clasificador, de modo que el modelo, en última instancia, clasifica sus datos.
Existen clasificadores supervisados y no supervisados. Los clasificadores de aprendizaje automático no supervisado se alimentan únicamente de conjuntos de datos sin etiquetar, que clasifican según el reconocimiento de patrones o estructuras y anomalías en los datos. Los clasificadores supervisados y semisupervisados se alimentan con conjuntos de datos de entrenamiento, a partir de los cuales aprenden a clasificar los datos según categorías predeterminadas.
El análisis de sentimientos es un ejemplo de aprendizaje automático supervisado en el que los clasificadores se entrenan para analizar el texto en función de la polaridad de la opinión y lo clasifican: Positivo, Neutral o Negativo. Prueba este modelo de análisis de sentimiento preentrenado para ver cómo funciona.
Prueba con tu propio texto
Resultados
Los clasificadores de aprendizaje automático se utilizan para analizar automáticamente los comentarios de los clientes (como los anteriores) procedentes de las redes sociales, los correos electrónicos, las reseñas online, etc, para averiguar qué dicen los clientes sobre su marca.
Otras técnicas de análisis de texto, como la clasificación por temas, pueden ordenar automáticamente los tickets de atención al cliente o las encuestas NPS, categorizarlos por temas (precios, características, soporte, etc.) y dirigirlos al departamento o empleado correcto.
Las plataformas de análisis de texto SaaS, como MonkeyLearn, ofrecen un fácil acceso a potentes algoritmos de clasificación, permitiéndole construir modelos de clasificación personalizados según sus necesidades y criterios, normalmente en unos pocos pasos.
Los clasificadores de aprendizaje automático van más allá del simple mapeo de datos, permitiendo a los usuarios actualizar constantemente los modelos con nuevos datos de aprendizaje y adaptarlos a las necesidades cambiantes. Los coches autoconducidos, por ejemplo, utilizan algoritmos de clasificación para introducir datos de imágenes en una categoría; ya sea una señal de stop, un peatón u otro coche, aprendiendo y mejorando constantemente con el tiempo.
Pero, ¿cuáles son los principales algoritmos de clasificación y cómo funcionan?
5 tipos de algoritmos de clasificación
Dependiendo de sus necesidades y sus datos, estos 5 algoritmos de clasificación principales deberían tenerle cubierto.
Árbol de decisión
Un árbol de decisión es un algoritmo de clasificación de aprendizaje automático supervisado utilizado para construir modelos como la estructura de un árbol. Clasifica los datos en categorías cada vez más finas: desde el «tronco del árbol» hasta las «ramas» y las «hojas». Utiliza la regla if-then de las matemáticas para crear subcategorías que encajan en categorías más amplias y permite una categorización precisa y orgánica.
Por ejemplo, así es como un árbol de decisión clasificaría los deportes individuales:
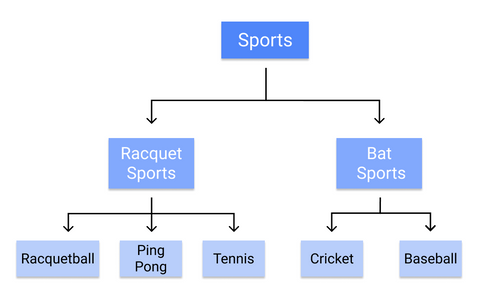
Como las reglas se aprenden secuencialmente, desde el tronco hasta la hoja, un árbol de decisión requiere datos limpios y de alta calidad desde el principio del entrenamiento, o las ramas pueden quedar sobreajustadas o sesgadas.
Clasificador Naive Bayes
Naive Bayes es una familia de algoritmos probabilísticos que calculan la posibilidad de que cualquier punto de datos pueda caer en una o más de un grupo de categorías (o no). En el análisis de texto, Naive Bayes se utiliza para categorizar los comentarios de los clientes, los artículos de noticias, los correos electrónicos, etc, en temas, tópicos o «etiquetas» para organizarlos según criterios predeterminados, así:
Los algoritmos de Bayes ingenuo calculan la probabilidad de cada etiqueta para un texto dado, y luego salen a por la probabilidad más alta:

Es decir, la probabilidad de A, si B es verdadera, es igual a la probabilidad de B, si A es verdadera, por la probabilidad de que A sea verdadera, dividida por la probabilidad de que B sea verdadera.
Pasando de etiqueta a etiqueta, esto calcula la probabilidad de que un punto de datos pertenezca o no a una determinada categoría: Sí/No.
K-Nearest Neighbors
K-nearest neighbors (k-NN) es un algoritmo de reconocimiento de patrones que almacena y aprende de los puntos de datos de entrenamiento calculando cómo se corresponden con otros datos en un espacio n-dimensional. K-NN tiene como objetivo encontrar los k puntos de datos relacionados más cercanos en datos futuros no vistos.
En el análisis de textos, k-NN colocaría una palabra o frase dada dentro de una categoría predeterminada calculando su vecino más cercano: k se decide por un voto plural de sus vecinos. Si k = 1, se etiquetaría en la clase más cercana a 1.
Máquinas de vectores de soporte (SVM)
Los algoritmos SVM clasifican los datos y entrenan los modelos dentro de unos grados de polaridad súper finitos, creando un modelo de clasificación tridimensional que va más allá de los simples ejes de predicción X/Y.
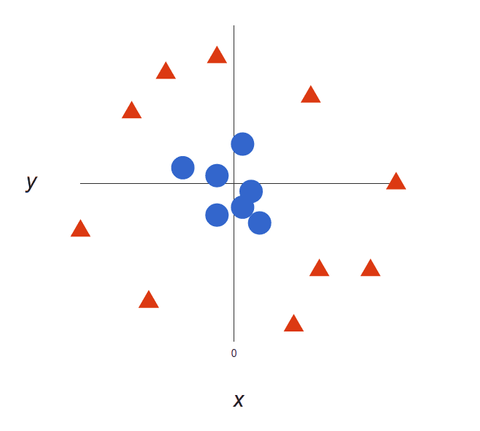
Eche un vistazo a esta representación visual para entender cómo funcionan los algoritmos SVM. Tenemos dos etiquetas: rojo y azul, con dos características de datos: X e Y, y entrenamos a nuestro clasificador para que emita una coordenada X/Y como roja o azul.
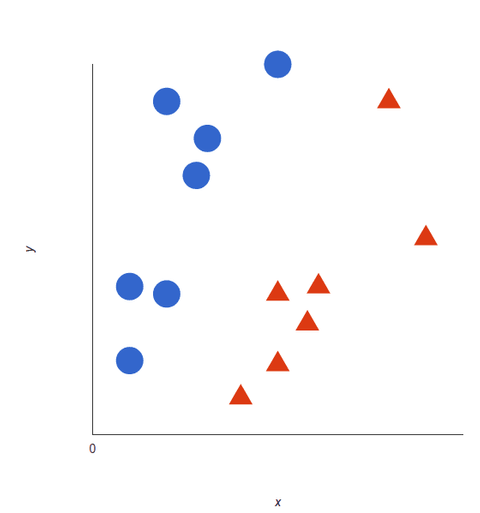
La SVM asigna un hiperplano que separa mejor (distingue entre) las etiquetas. En dos dimensiones esto es simplemente una línea recta. Las etiquetas azules caen en un lado del hiperplano y las rojas en el otro. En el análisis de sentimiento estas etiquetas serían Positiva y Negativa.
Para maximizar el entrenamiento del modelo de aprendizaje automático, el mejor hiperplano es el que tiene la mayor distancia entre cada etiqueta:
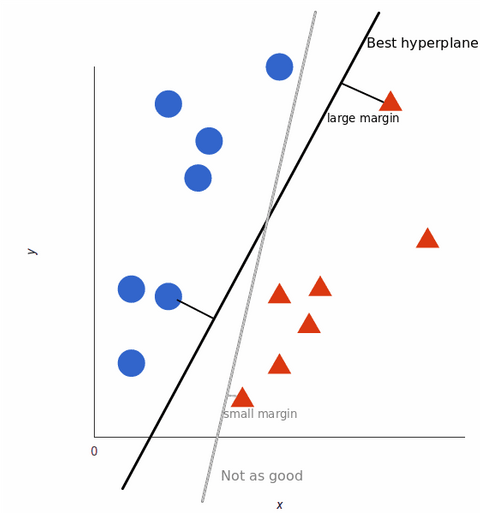
A medida que nuestros conjuntos de datos se vuelven más complejos, puede que no sea posible dibujar una sola línea para distinguir entre las dos clases:
Los algoritmos SVM son excelentes clasificadores porque, cuanto más complejos sean los datos, más precisa será la predicción. Imagine lo anterior como una salida tridimensional, con un eje Z añadido, por lo que se convierte en un círculo.
Mapeado de nuevo a 2D, con el mejor hiperplano, se ve así:
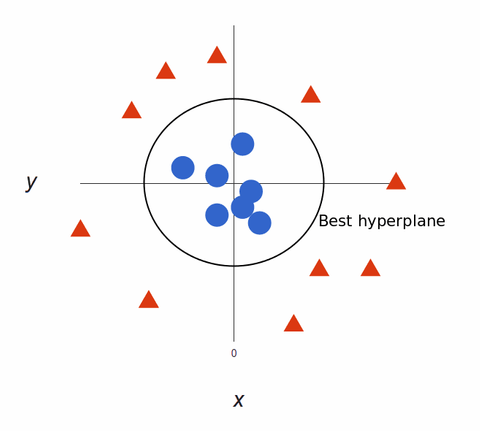
Los algoritmos SVM crean modelos de aprendizaje automático súper precisos porque son multidimensionales.
Redes neuronales artificiales
Las redes neuronales artificiales no son un «tipo» de algoritmo, sino un conjunto de algoritmos que trabajan juntos para resolver problemas.
Las redes neuronales artificiales están diseñadas para funcionar de forma muy parecida a como lo hace el cerebro humano. Conectan los procesos de resolución de problemas en una cadena de eventos, de modo que una vez que un algoritmo o proceso ha resuelto un problema, el siguiente algoritmo (o eslabón de la cadena) se activa.
Las redes neuronales artificiales o los modelos de «aprendizaje profundo» requieren enormes cantidades de datos de entrenamiento porque sus procesos son muy avanzados, pero una vez que se han entrenado adecuadamente, pueden rendir más que otros algoritmos individuales.
Hay una gran variedad de redes neuronales artificiales, incluyendo las convolucionales, las recurrentes, las feed-forward, etc., y la arquitectura de aprendizaje automático que mejor se adapte a sus necesidades depende del problema que pretenda resolver.
Ponga los clasificadores de aprendizaje automático a trabajar para usted
Los algoritmos de clasificación permiten la automatización de tareas de aprendizaje automático que eran impensables hace apenas unos años. Y, lo que es mejor, permiten entrenar los modelos de IA según las necesidades, el lenguaje y los criterios de su negocio, actuando mucho más rápido y con un mayor nivel de precisión de lo que jamás podrían los humanos.
MonkeyLearn es una plataforma de análisis de texto de aprendizaje automático que aprovecha el poder de los clasificadores de aprendizaje automático con una interfaz extremadamente fácil de usar, para que pueda agilizar los procesos y sacar el máximo provecho de sus datos de texto para obtener información valiosa.
Pruebe estos modelos de clasificación preentrenados para ver cómo funciona:
O programe una demostración gratuita para ver todo lo que MonkeyLearn tiene que ofrecer.